







视频链接:https://www.youtube.com/watch?v=Cjur2htVuSk

论文链接:https://arxiv.org/pdf/2502.04507
Git链接:https://github.com/hao-ai-lab/FastVideo
Huggingface:https://huggingface.co/FastVideo/FastHunyuan
亮点直击
识别并量化了最先进的视频 DiT 中的 3D 局部性和头部 specialization,揭示了完整 3D 注意力中的大量冗余。
引入了 SLIDING TILE ATTENTION,一种基于分块的滑动窗口注意力机制。优化内核与 FlashAttention 3 相比实现了最小的开销,MFU 达到 58.79%。
STA 将注意力加速超过 10 倍,并将端到端视频生成加速高达 3.53 倍,且没有或仅有最小的质量损失。
使用 DiTs 进行视频生成速度极慢——即使在 H100 上配备 FlashAttention-3,HunyuanVideo 生成 5 秒视频也需 16 分钟。而本次分享的滑动块注意力(STA)技术将其缩短至 5 分钟,无任何质量损失,无需额外训练。STA 在注意力计算上的加速比为 FlashAttention-2 的 2.8–17 倍,FlashAttention-3 的 1.6–10 倍。结合 STA 及其他优化方案,解决方案在无质量损失且无需训练的情况下,相比 FA3 全注意力基线提升端到端生成速度 2.98 倍。启用微调还能带来更大的加速效果!
视频 DiT 中的注意力
最先进的 Video DiT 依赖 3D 全注意力来捕捉空间和时间关系,使每个 token 都能在空间和时间维度上关注其他所有 token。然而,现代视频模型会生成大量 token——例如,HunyuanVideo 仅生成一个 5 秒 720p 视频就需要 115K 个 token。随着分辨率或时长的增加,问题变得更加严重:对于形状为 的视频(假设时间和空间维度相等),即使 略微增加,token 数量也会呈立方级增长。由于注意力计算的复杂度为二次方,这使得它迅速成为主要的计算瓶颈。如图 1(a) 所示,注意力计算在推理成本中占据主导地位。
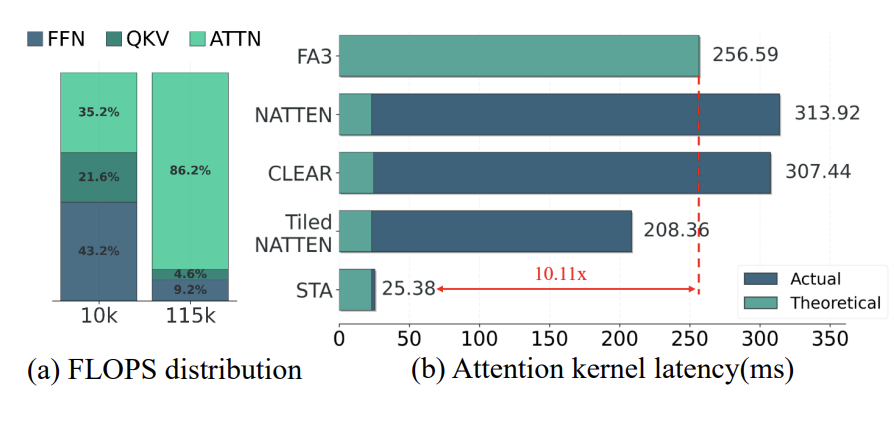
Figure 1: (a) Generating a 5s 720P clip in Hunyuan involves processing 115K tokens, making attention the dominant cost. (b) Attention latency comparison: existing methods fail to translate FLOP reduction into wall-clock speedup; STA is hardware-efficient and achieves proportional speedup with sparsity
假设 3D 全注意力存在大量冗余,如果能有效利用这些冗余,将大幅加速推理。为验证这一点,在图 2(左)中可视化了 HunyuanVideo 的注意力分数,并发现了明显的 3D 局部性模式:查询主要关注空间和时间上临近的键。为了量化这一现象,我们计算了注意力召回率——即集中在局部窗口内的注意力分数占总注意力分数的比例。如图 2(中)所示,尽管 HunyuanVideo 经过全 3D 注意力训练,但其仍表现出强烈的局部性:仅占总空间 15.52% 的小局部窗口就捕获了 70% 的总注意力。
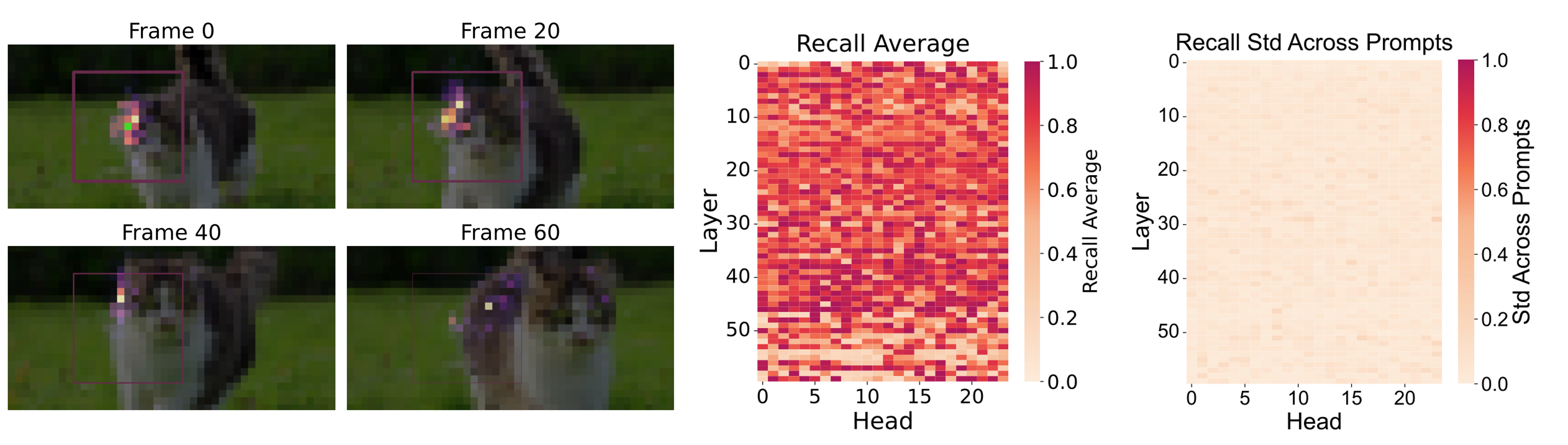
Figure 2. Left: Instead of attending to the entire image, the query (green dot)’ only attends to keys within a local window. Mid: Attention scores within the local window accouts for mojority of the entire attention. Right: Despite the different recall across heads, the standard deviation across prompts remains low.
本文的分析指出了一个看似显而易见的解决方案:用局部化注意力替代全 3D 注意力,以加速视频生成。一个自然的做法是滑动窗口注意力(SWA),这种方法在 NLP 的 1D 序列处理中被广泛使用。然而,我们发现 SWA 在 2D 和 3D 中完全失效!尽管其理论上可行,但目前尚无适用于 3D 视频 DiT 的高效实现。
更糟糕的是,如图 1(右)所示,现有的 SWA 方法(如 CLEAR 和 NATTEN)虽然降低了 FLOPs,但未能真正提升速度,原因在于硬件利用率极低。为什么会这样?因为高阶滑动窗口注意力与现代 FlashAttention(FA)存在根本性不兼容问题,在 GPU 上的计算效率极低。
滑动窗口注意力的低效性
要理解为什么 SWA 与 FlashAttention(FA)不兼容,首先需要回顾 FA 的分块计算模式。FA 并非逐个处理 token,而是将输入序列划分为小块(通常为 ),并在 GPU 上高效计算。为简单起见,我们在讨论中假设使用方块结构。
FA 会将整个块的 、 和 加载到 GPU 的 SRAM,执行所有必要的计算,并仅将输出矩阵 写回 HBM,从而避免存储诸如注意力掩码或注意力分数等中间值。如图 3 所示,FA 将注意力图划分为更小的块,使每个块成为计算的基本单元。
为什么这很重要?首先,这避免了存储大规模的中间张量,从而节省大量内存。其次,GPU 设计本质上适用于矩阵乘法,不擅长处理标量甚至向量运算;它们在块级计算上表现出色,而非逐个 token 处理。
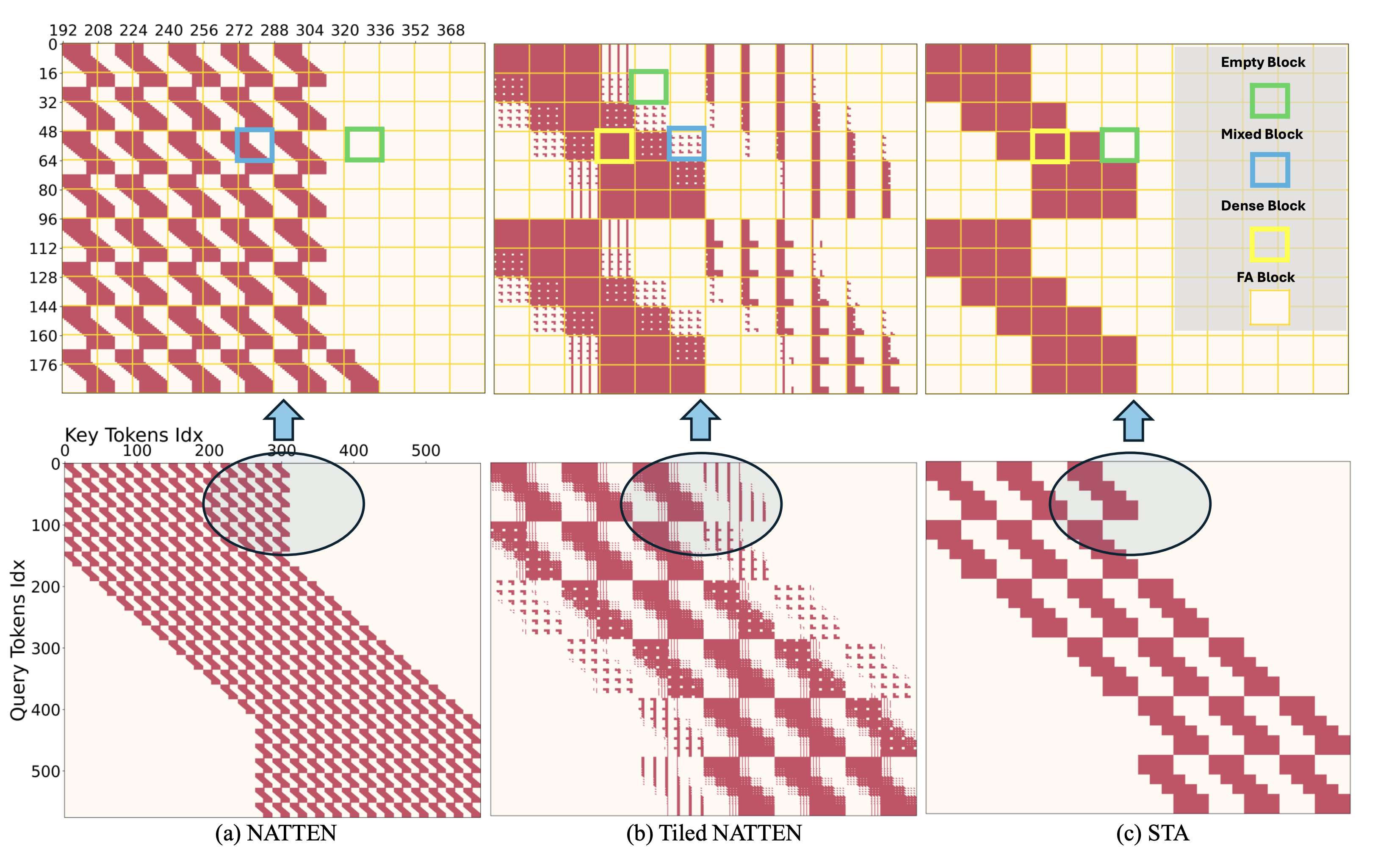
Figure 3. The attention map of NATTEN, Tiled NATTEN, and STA. We plot with an image size 24×24 and a 12×12 local window. The tile size is set to 4×4. Note that we mainly use STA in 3D scenarios for video generation in this paper, but for better illustration, we present the 2D scenario in this plot.
在 FlashAttention 中实现 2D/3D SWA 主要面临一个关键挑战:如何定义其注意力掩码。根据掩码的应用方式,我们将注意力块分为三种类型:
-
密集块(Dense blocks):保留所有注意力分数(计算效率极高 ✅)。
-
空块(Empty blocks):所有值均被掩码(可完全跳过 ✅)。
-
混合块(Mixed blocks):部分分数被保留,部分被掩码(效率灾难 ❌)。
虽然密集块和空块能够很好地适配 FA,但混合块会引入严重的计算开销,主要原因如下:
-
计算浪费:由于块是最小计算单元,FA 必须先计算整个块,再应用掩码,这会导致大量无用计算。
-
GPU 不友好的掩码处理:块内部的掩码不仅依赖于用户定义的注意力模式,还取决于该块在注意力图中的位置。更糟糕的是,这种掩码无法预先计算,否则会带来二次方级的内存开销。即使在 FlexAttention 中,一个简单的因果掩码也会带来 15% 的额外开销,而在 3D SWA 中,掩码处理的开销甚至可能超过计算整个块的成本!这就是为什么高阶 SWA 在 GPU 上表现不佳——它会生成过多的混合块!
为了说明这一问题,在图 3(a) 中分析了 NATTEN——一种改进的 SWA 变体。NATTEN 通过在图像/视频边界处移动窗口中心,确保每个查询点始终关注固定数量的键。然而,这种方法导致查询点关注不同的键组,破坏了注意力图的均匀性,并产生大量混合块。
为缓解这一问题,Tiled NATTEN 通过重新排序输入数据,提高密集块的比例(如图 3(b) 所示)。然而,仍有相当一部分块属于混合块,使得 SWA 在 GPU 上的计算效率始终低下。
理解 SWA 在图 3 中产生“之”字形注意力图的原因可能并不直观。为了直观展示这一现象,我们提供了一个动画,演示在 (10,10) 大小的图像上,使用 (5,5) 窗口的 2D SWA 过程。
插入视频:https://www.youtube.com/watch?v=tY5zWL7o7F0&t=2s fastvideo1.mp4
滑动块注意力(Sliding Tile Attention, STA)
STA的核心思想很简单:GPU 最适合逐块计算,但滑动窗口注意力(SWA)逐 token 滑动窗口,效率低下。我们提出的 STA 通过逐块滑动解决了这一问题。在 3D 场景中,将一个分块定义为一个连续的 token 组,形成一个时空立方体,其大小由 FlashAttention 中的块大小决定。这一小改动消除了注意力图中的混合块,并显著提高了计算效率。
-
SWA:逐 token 移动,创建不规则的注意力图,GPU 难以高效处理。
-
STA:逐块移动,形成密集和空的注意力块,对 GPU 友好。
具体来说:
-
一个大小为 的视频被划分为大小为 的非重叠分块。假设 FlashAttention 的块大小为 ,则 应满足条件 。
-
每个分块内的 token 被连续展平。窗口大小也应为分块大小的整数倍。
-
注意力窗口以步长 逐块移动。对于每个局部窗口,中心查询分块会关注窗口内的键分块。
-
这导致注意力图中只有密集块和空块,完全消除了低效的混合块,如图 3 (c) 所示。
下面的视频展示了 STA 的工作原理。为了更好地说明,我们使用了一个 2D 场景。在此示例中,我们将 STA 应用于一个 10×10 的图像,分块大小为 (2,2),窗口大小为 (6,6)。
插入视频:https://www.youtube.com/watch?v=D4gZ--LhZHs fastvideo2.mp4
STA可以通过 FlexAttention 高效实现,它提供了足够的功能来跳过所有空块,并避免在密集块上添加不必要的块内掩码。我们可以通过将块间掩码逻辑与计算内核解耦来进一步优化稀疏注意力掩码。因此,我们的注意力内核基于 ThunderKittens 和 FlashAttention-3 实现。
STA 的内核级优化
受到 FlashAttention-3 和 ThunderKittens 的启发,实现将线程块(threadblock)分为计算工作组(compute warpgroups)和数据工作组(data warpgroups),其中块间掩码完全由数据工作组管理。每个计算工作组负责计算一个查询块(query block),该查询块始终驻留在 SRAM 中(Split-Q)。数据工作组负责异步地将键值块(KV blocks)从 HBM(高带宽内存)加载到 SRAM 中。对于每个查询块,数据工作组需要确定该查询块在 STA 中会关注哪些键值块,并仅加载这些块。由于数据工作组是异步的,计算块间掩码和决定加载哪些数据的开销可以通过重叠操作来隐藏。另一方面,计算工作线程完全不需要感知稀疏注意力模式。它使用数据工作线程加载到共享内存中的键值块执行注意力计算,一旦循环缓存(circular cache)中的所有数据被消耗完毕,计算即完成。
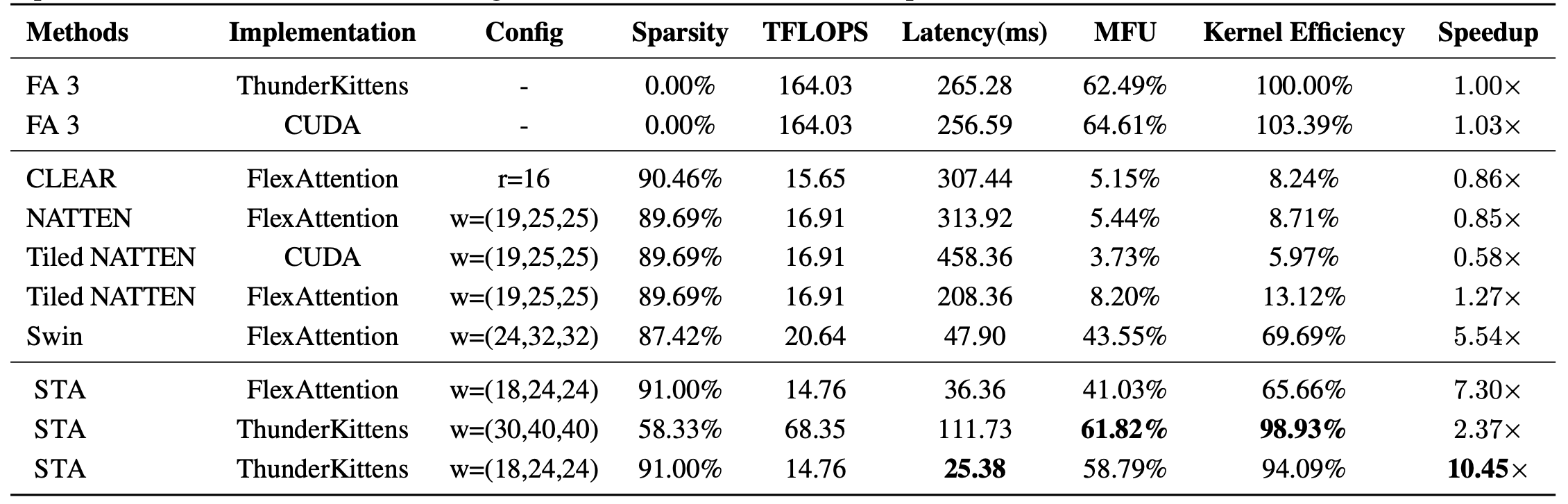
Table 1. Forward speed of sparse attention kernels in a setup aligned with HunyuanVideo’s inference configuration (bf16, 720P, 5s, 115.2K seq len, dhead = 128, # heads = 24). Config controls the window size of each sparse attention.
内核性能
在下表1中报告了内核性能。结果显示,现有的局部注意力方法在效率上存在困难。例如,尽管CLEAR将FLOPs减少到15.65,但实际上推理速度降低了14%。NATTEN也表现不佳——尽管实现了91%的稀疏性,但其基本版本比完整注意力慢了15%,即使在FlexAttention中优化的分块变体也只能将速度提升1.27倍。在当前选项中,Swin是唯一一个内存利用率因子(MFU)超过40%且内核效率超过60%的内核,但它牺牲了注意力机制的灵活性——Swin不是局部注意力的变体。
相比之下,在FlexAttention中测试时,STA将MFU从Tiled NATTEN的8.20%提高到41.03%。通过进一步的内核优化,STA相比完整注意力实现了10.45倍的加速。即使在58.33%的稀疏性下,它仍然提供了2.37倍的更快处理速度。这意味着STA可以处理更大的注意力窗口,同时仍然优于NATTEN。据我们所知,STA是第一种将高效的3D稀疏局部注意力与实际速度提升相结合的方法。
窗口大小校准实现无需训练的速度提升
如图2(右)所示,视频扩散模型表现出强烈的3D局部性和头部 specialization。虽然不同的注意力头在不同尺度上捕捉信息,但它们的局部性模式在不同提示之间保持一致。这使得我们可以使用一小部分提示为每个头搜索最佳窗口大小,并将结果推广到其他提示。对于每个元组——其中是推理步骤索引,是层索引,是头索引——我们确定最佳注意力掩码。
由于早期采样步骤对全局结构至关重要,我们在前15步保留完整注意力。对于剩余的步骤,从预定义的集合中选取候选掩码,通过计算其输出与完整注意力输出之间的L2距离,选择距离最小的掩码。本文的视频生成设置使用分辨率,转换为DiT形状为。我们将分块大小设置为,并从窗口大小中选择。在18个提示上进行校准,通过计算它们的L2距离平均值来确定每个头的最佳掩码策略。整个搜索过程在单个H100 GPU上不到18小时完成。通过窗口大小校准的STA实现了58%的注意力稀疏性和1.8倍的端到端加速,将DiT推理时间从945秒(FA3完整注意力)减少到520秒,且没有质量损失。
STA通过利用3D完整注意力中的冗余来加速注意力。另一种加速视频生成的方法侧重于缓存,利用扩散步骤之间的冗余。我们证明STA与TeaCache兼容,TeaCache是一种基于缓存的最先进的扩散加速技术。结合我们的解决方案,实现了3倍加速,将DiT推理时间从945秒减少到317秒,且没有质量损失。
我们在MovieGen Bench中随机选择的200个提示上评估了我们的方法。以下,我们提供了原始Hunyuan模型与我们的3倍加速解决方案之间的额外非精选定性比较。
插入视频:https://www.youtube.com/watch?v=MG1qKa_F0QU fastvideo3.mp4
使用 STA 训练解锁更大的加速
除了为每个注意力头搜索最佳稀疏掩码外,还可以使用固定窗口并对 STA 进行微调,以在保持高稀疏性的同时最大化性能。由于 STA 遵循 3D 局部性特性,这种适应可以通过最小的训练开销高效学习。在本文的实验中,微调仅需在 8 个 H100 GPU 上花费 8 小时——与预训练视频扩散模型的成本相比可以忽略不计。尽管每个注意力层在受限的局部窗口上操作,但通过堆叠的 Transformer 层,感受野得以扩展,使得 Diffusion Transformer 能够生成全局一致的视频。
例如,在窗口配置为 的极高稀疏性下,STA 实现了 91.00% 的注意力稀疏性,带来了 5.76 倍的 FLOPs 减少和 3.53 倍的实际延迟减少。重要的是,这种效率提升几乎不会影响质量:STA 在无需训练的情况下保持了 80.58% 的 VBench 分数,并在微调后提升至 82.62%。
思考
高效的 2D/3D 滑动窗口注意力在 STA 之前并不存在,这似乎令人惊讶——毕竟,这是一个基本概念,并且在 1D 上下文中被广泛使用。那么,为什么直到现在才有人破解 2D/3D 的内核呢?
回顾一下,让我们看看 Swin Transformer。作者们面临着同样的挑战:高效的 2D 滑动窗口注意力内核实现起来并不简单。他们的解决方案是什么?完全避免它。Swin 没有使用真正的滑动窗口,而是采用了非重叠的静态窗口分区,绕过了效率问题,但代价是破坏了跨窗口注意力,而这对于视频任务至关重要。当然,Swin 能够成功是因为它用于预训练设置——模型通过学习在层之间通过移动窗口拼接信息来弥补这一限制。当你有预训练的奢侈条件时,这没问题,但在像我们这样的无需训练或微调场景中,它就不那么有效了。
所以,至少可以欣慰地知道,解决这个问题从来都不容易——但这正是让进展变得更加令人兴奋的原因!
结论
本研究引入SLIDING TILE ATTENTION 来加速视频扩散模型,通过为高阶滑动窗口类注意力优化内核,实现了高效的 GPU 执行,同时保留了局部性特性。实验表明,SLIDING TILE ATTENTION 在加速视频生成的同时,仅带来最小或没有质量损失。从概念上讲,本文的方法与其他加速技术(如缓存和一致性蒸馏)是正交的。相信 STA 的潜力远不止于加速视频扩散模型。它可以应用于预训练,并推广到其他高阶数据。局部性几乎是所有数据模态的普遍属性。希望 STA 能够激发跨领域的新的、更高效的模型。
参考文献
[1] Fast Video Generation with Sliding Tile Attention [2] https://hao-ai-lab.github.io/blogs/sta/

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









