








论文链接:https://arxiv.org/pdf/2502.01993
代码&模型链接:https://github.com/JianzeLi-114/FluxSR
亮点直击
开发了FluxSR,一种基于FLUX.1-dev的单步扩散Real-ISR模型。这是首个基于超过120亿参数大模型的单步扩散Real-ISR模型。
提出了一种流轨迹蒸馏(FTD)方法,明确建立了噪声到图像流与低分辨率到高分辨率流之间的关系。在噪声到图像流保持不变的情况下,能够保留T2I模型中的高度逼真性,并有效地将其转移到低分辨率到高分辨率的流中用于超分辨率。
为了使训练可行,提出了一种适合大型模型的训练策略,该策略在训练阶段不包括额外的教师模型。将教师的知识融入到噪声到图像流中,并在离线模式下生成大量这样的流,从而减少内存消耗和训练成本。
总结速览
解决的问题
-
多步扩散模型的计算成本高,限制了其在真实世界图像超分辨率(Real-ISR)任务中的应用。
-
现有的单步扩散方法受教师模型性能限制,低质量的教师模型会导致生成的图像出现伪影。
-
大模型的训练成本和内存消耗高,尤其在蒸馏过程中,使用额外教师模型会显著增加计算负担。
提出的方案
-
提出了FluxSR,一种基于流匹配模型的单步扩散Real-ISR技术。
-
引入了流轨迹蒸馏(FTD)方法,旨在将多步流匹配模型蒸馏为单步Real-ISR模型,解决生成分布偏移的问题。
-
采用大模型友好的训练策略,通过将教师模型的知识融入到噪声到图像流中,并通过离线模式生成流数据,避免在训练过程中使用额外的教师模型,从而减少内存消耗和训练成本。
-
提出了TV-LPIPS感知损失,结合总变差(TV)思想,恢复图像的高频分量,减少伪影。
-
引入了注意力多样性损失(ADL),作为正则化项,解决了生成图像中的重复模式问题。
应用的技术
-
Flux.1-dev作为基础模型,结合流匹配理论来学习噪声到图像流与低分辨率到高分辨率流之间的关系。
-
流轨迹蒸馏(FTD),通过保持原有T2I流不变,学习SR流轨迹。
-
TV-LPIPS感知损失,强调高频成分的恢复,改善图像真实感。
-
注意力多样性损失(ADL),改善Transformer模块中不同token的多样性,避免生成图像中的重复模式。
达到的效果
-
生成图像质量显著提高,能够保留高照片逼真度,同时有效避免伪影。
-
仅需一步采样,大幅减少计算开销和推理延迟。
-
通过创新的训练策略,显著降低了内存消耗和训练成本,使得大模型在资源有限的条件下仍能高效训练。
-
实验结果表明,FluxSR在多个评估指标上超越了现有的单步扩散Real-ISR方法。

方法
流轨迹蒸馏(FTD)
本文的目标是从预训练的文本到图像(T2I)流模型中蒸馏出一个单步扩散超分辨率模型。当前的大多数单步扩散ISR方法直接微调预训练的T2I模型,并结合如VSD或GAN等模块以提升性能。尽管这些方法已取得了不错的结果,但仍面临一些挑战。如下图2左侧所示,预训练的T2I模型的流轨迹与SR模型的流轨迹并不对齐。在微调过程中,这些方法没有机制保持扩散终点分布不变。换句话说,图中的真实数据分布(蓝色)发生了偏移,转换为生成分布(橙色)。对于已经很好拟合真实数据分布的大规模T2I模型,使用上述方法进行微调可能导致负面结果。
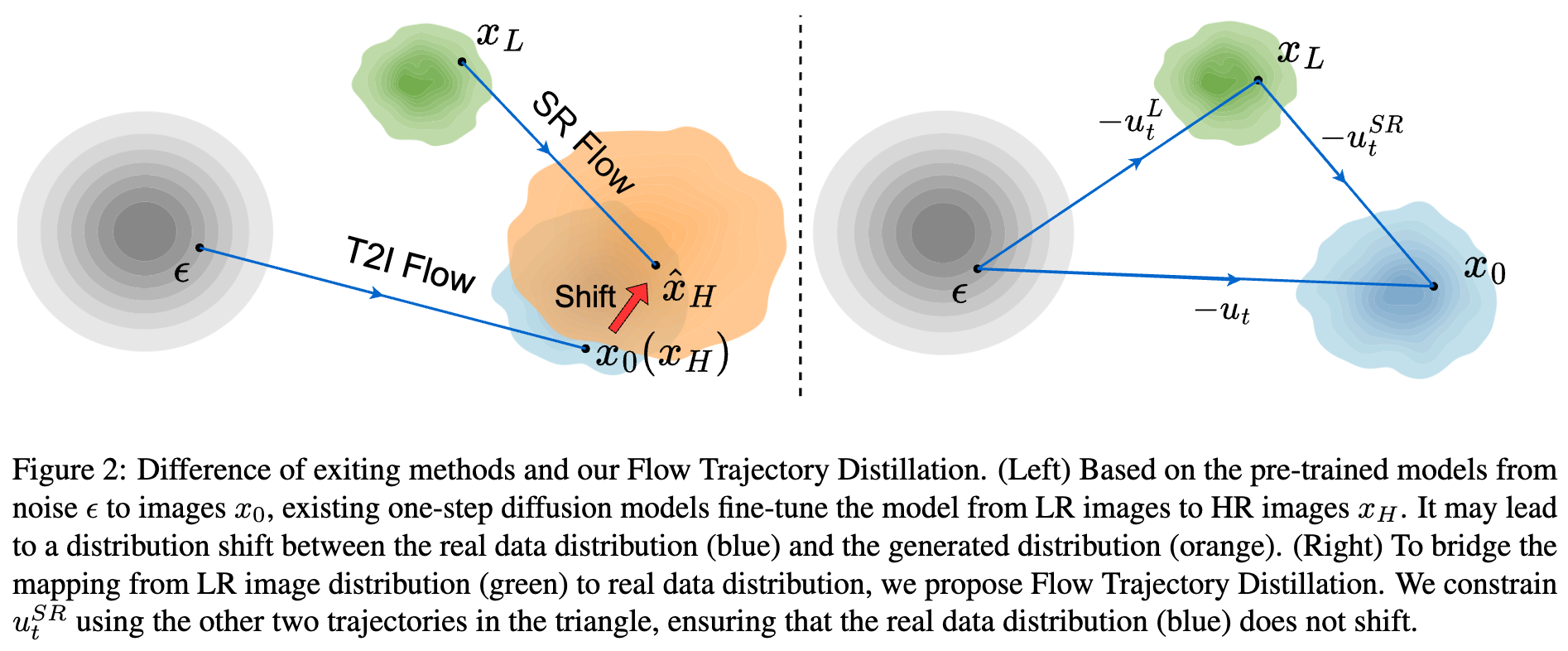
理想情况下,最终的模型应该作为从低分辨率(LR)图像分布(图2中的绿色分布)到高分辨率(HR)图像分布(图2中的蓝色分布)的映射。我们的目标是在微调T2I模型的过程中,保持向量场在上的分布不变,同时修改扩散起始点的分布(即,如上图2所示,从噪声分布过渡到LR图像分布)。因此,本文提出了流轨迹蒸馏方法,通过拟合间接获取,避免了真实数据分布的偏移。
近似低分辨率图像分布
受DMD启发,可以通过训练一个扩散模型来学习训练数据的潜在分布。对于流匹配模型,在低分辨率数据上进行训练使能够获得拟合向量场的参数,该向量场将噪声分布映射到低分辨率图像分布。对应的条件流轨迹由以下公式给出:
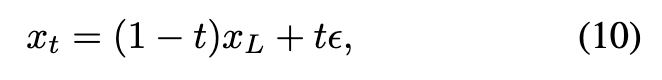
其中,,。在时间时,样本的速度由给出。
从噪声到图像流计算LR到HR的流
此时,已获得了从噪声到低分辨率(LR)图像的流模型,以及从噪声到真实世界高分辨率(HR)图像的流模型(即预训练的T2I模型)。鉴于ReFlow轨迹的线性性质,我们可以轻松推导出从低分辨率图像到高分辨率图像的流模型。有:
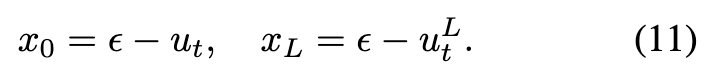
这里, 和 分别对 和 进行参数化。通过结合上述方程,得到从 到 的轨迹:
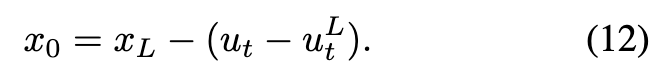
大模型友好的训练策略
尽管已经推导出了FTD的理论公式,但其实际应用面临以下挑战:
i) 推理效率:在推理过程中,需要预训练的T2I模型计算出的向量场和在LR数据上微调的模型计算出的向量场。这需要两个不同的流模型,每个模型有不同的参数,从而导致推理过程中的计算开销大。
ii) 估计误差:在一步推理中运行流模型使得难以准确估计时间时的速度。如果不使用重建损失来优化生成器,模型的性能可能会下降。
本文提出了一种优化的训练策略,以确保在推理过程中只需要一个流模型。此外,还加入了重建损失,以提高模型性能。
直接参数化 。如下图3左侧所示,可以从和中推导出,也可以通过和获得。这避免了无法直接参数化的问题。使用来参数化。为了用一个模型表示和,将与LR图像对应的时间步长定义为,而不是0。这确保模型只在时间范围内表示,并且只在时表示。此外,LR图像分布与预训练的扩散模型的中间状态更为相似。如图3所示,类似于公式(11),有:
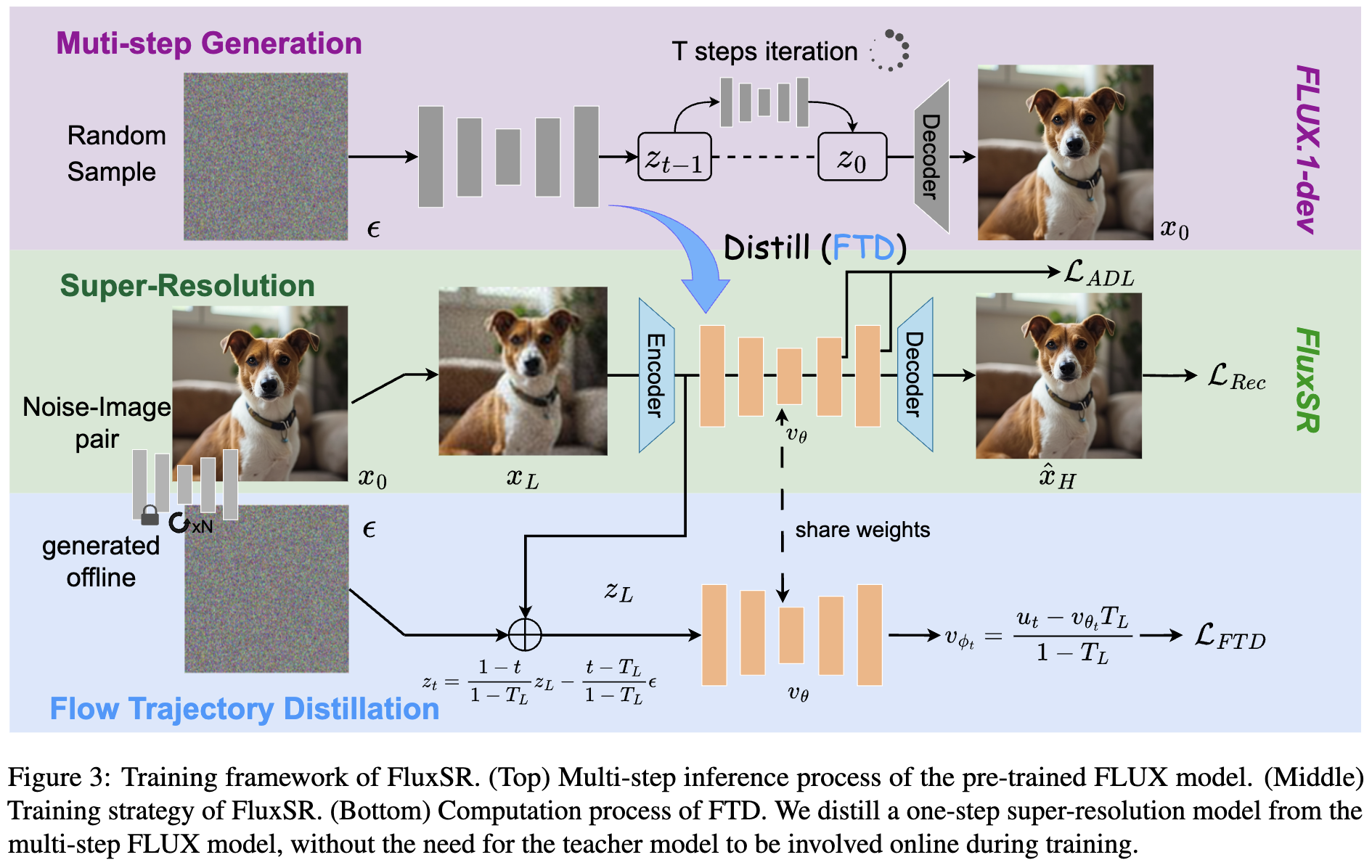
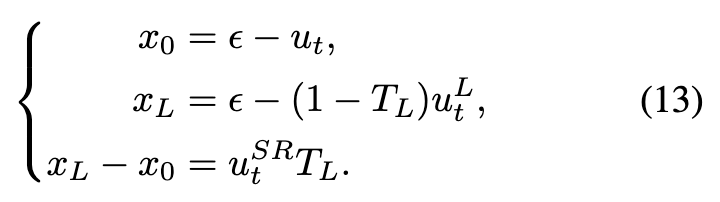
通过结合上述方程,得到:

模型的参数化可以表达为:
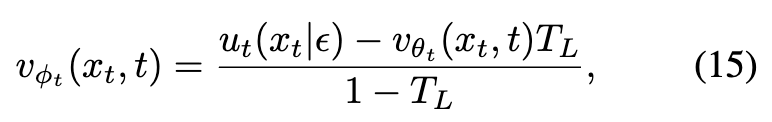
其中:
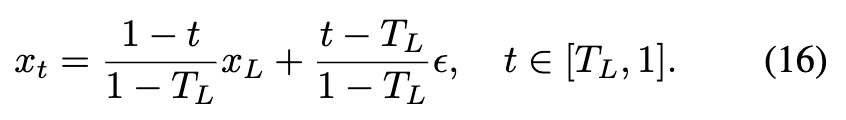
生成噪声到图像流的蒸馏。预计算由FLUX生成的噪声样本对,并将其作为训练数据,无需依赖任何真实图像。此方法为大模型训练提供了两个关键优势。1) 通过使用由教师模型生成的数据对,可以直接计算,从而避免了在单步推理过程中出现的估计误差。2) 在训练过程中,教师模型不再需要进行在线推理,这显著减少了GPU使用量和训练时间,尤其是对于像FLUX这样的超大T2I模型。
使用v-预测,FTD的损失函数如下所示:
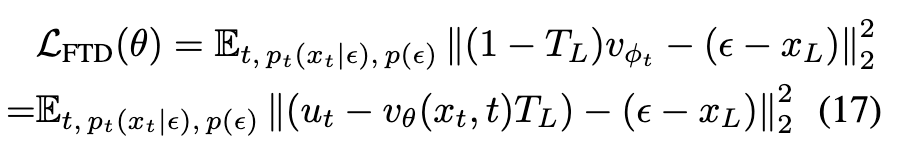
其中 。
生成器 可以表示为:
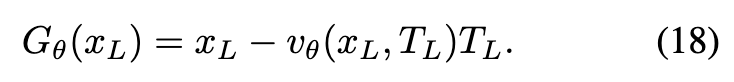
反伪影损失函数
在训练过程中,观察到生成器的预测在像素空间中会出现周期性的高频伪影。如下图4所示,伪影的周期为16像素,恰好是VAE缩放因子(8)与变换器补丁大小(2)的乘积。这表明每个token在某些维度上具有相似的成分。

感知损失的改进。 目标是减少平坦区域中相邻像素之间的变化,以抑制高频伪影,同时保持锐利的边缘。受到总变差(TV)损失的启发,提出了TV-LPIPS作为训练的感知损失。具体来说,TV-LPIPS计算如下:
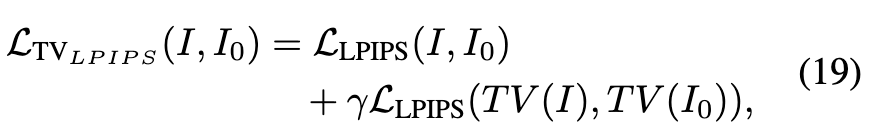
其中
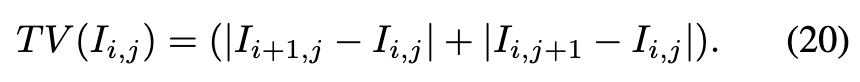
TV-LPIPS度量了像素变化的程度,并计算了与真实值的LPIPS距离。这不仅可以防止平滑区域中相邻像素之间的过度变化,还增强了LPIPS损失对高频成分的敏感性。总之,用于训练的重建损失可以表示为:
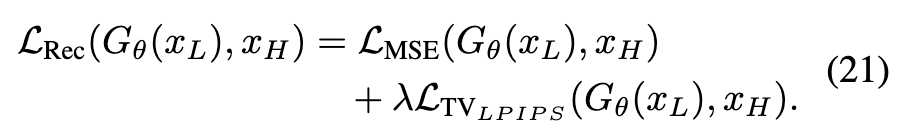
注意力多样性损失(ADL)。 为了解决特征层次的周期性伪影问题,引入了Guo等人提出的注意力多样性损失(ADL)。ADL旨在减少token之间的相似性并增强注意力的多样性。将此损失引入以防止不同的token生成相同的特征组件。
为了减少计算复杂性,ADL首先通过计算每个token特征向量与所有token特征向量的均值之间的余弦相似度来近似整体余弦相似度,该均值定义为:
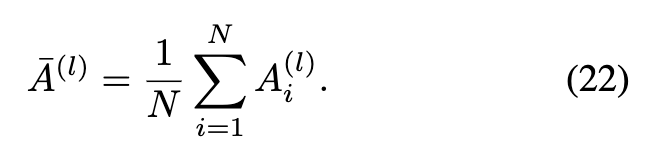
在这里, 表示第 个 Transformer 层输出中的第 个特征向量。对于一个有 层的模型,ADL 计算所有层的平均 ADL 损失。
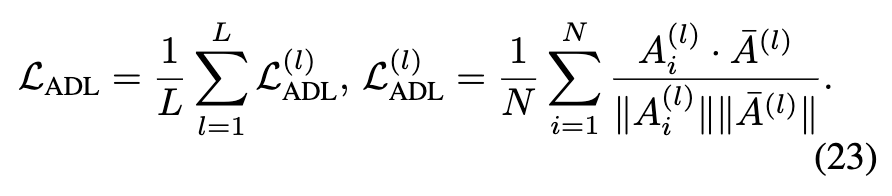
总之,FluxSR 的整体训练过程如算法 1 所示。

实验
实验设置
训练数据集:本文的方法不需要任何真实数据集。使用 FLUX.1-dev 生成了 2400 对大小为 1024x1024 的噪声-图像对作为训练数据。为了获得相应的低分辨率(LR)图像,使用了 RealESRGAN 提出的退化流程。
测试数据集:在合成数据集 DIV2K-val以及两个真实数据集 RealSR和 RealSet65 上评估本文的模型。对于 DIV2K-val,使用 RealESRGAN 退化流程生成相应的 LR 图像。在这些数据集上,使用全尺寸图像进行评估,以评估模型在真实场景中的性能。
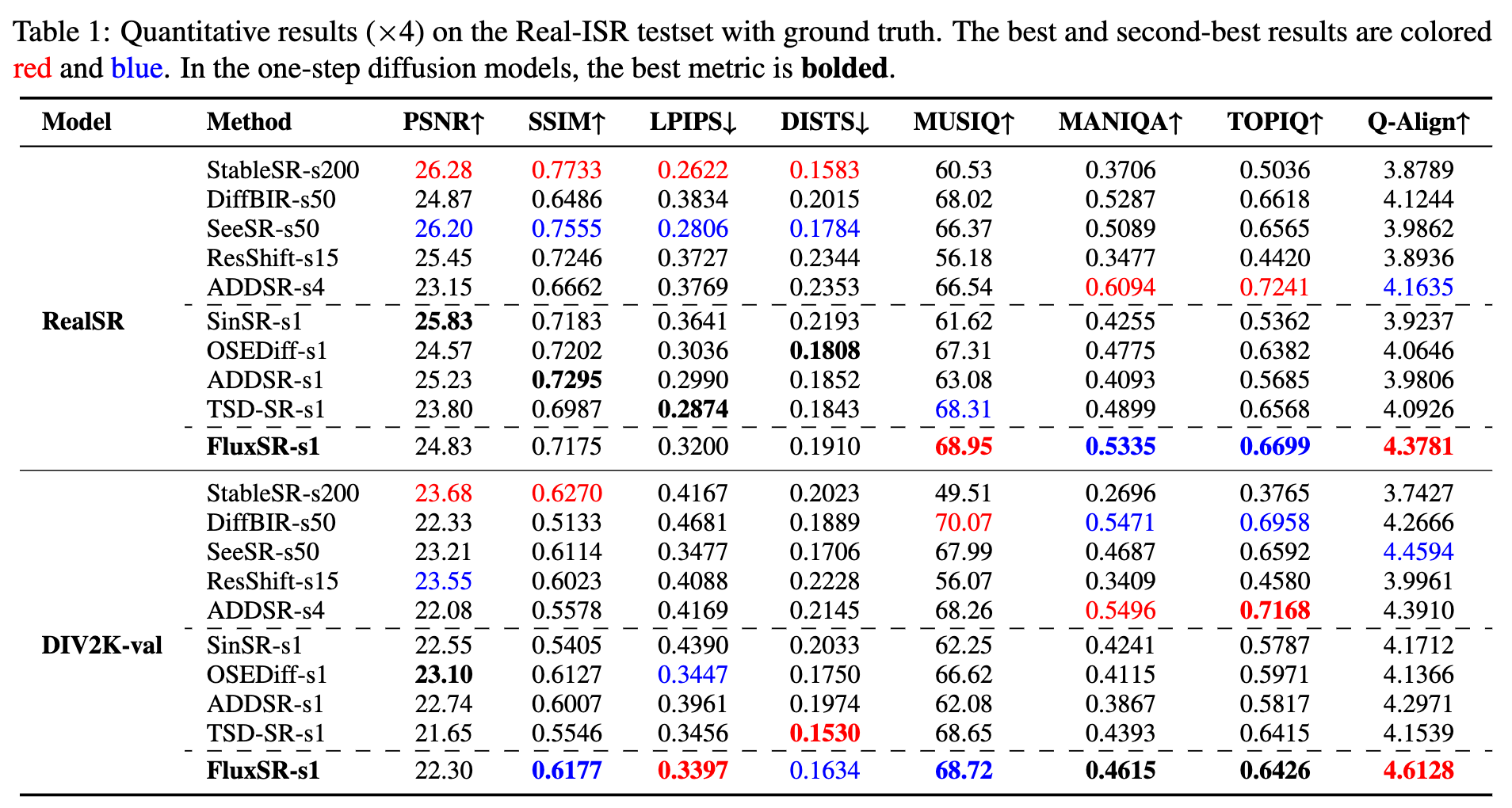
对比方法与评估指标:将本文的模型与其他基于扩散的图像超分辨率(ISR)模型进行性能对比,包括多步扩散 ISR 模型:StableSR、DiffBIR、SeeSR、ResShift 和 AddSR;以及单步扩散 ISR 模型:SinSR、OSEDiff和 。使用 4 个全参考指标(PSNR、SSIM、LIPIS 和 DISTS)以及 4 个无参考指标(MUSIQ、MANIQA、TOPIQ 和 Q-Align)评估本文的模型和上述方法。PSNR 和 SSIM 在 YCbCr 空间的 Y 通道上计算。
与最先进方法的对比
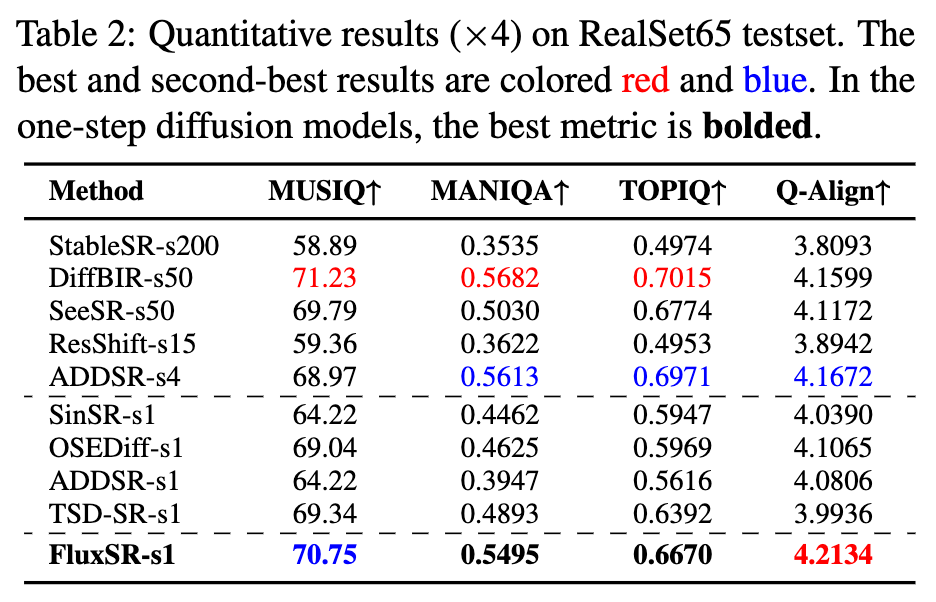
定量对比:下表 1 和表 2 展示了 FluxSR 与其他基于扩散的真实图像超分辨率(Real-ISR)方法的定量对比。在单步方法中,本文的方法在所有测试数据集上的所有无参考(NR)指标中均取得了最佳性能。对于 PSNR 和 SSIM 等全参考(FR)指标,最近的研究表明图像保真度和感知质量之间存在权衡。在基于扩散的超分辨率方法中,PSNR 和 SSIM 的参考价值有限。与多步方法相比,FluxSR 在所有数据集上均优于 StableSR。与 DiffBIR、SeeSR 和 AddSR 相比,FluxSR 在 TOPIQ 上略低。
定性对比
下图 5 展示了 FluxSR 与其他方法的视觉对比。FluxSR 能够在严重退化的情况下生成逼真的细节。

例如,在图 5 的第一行中,展示了一件外套图像的恢复结果,DiffBIR、ResShift 和 SinSR 受到噪声影响,导致生成的人工纹理。尽管 AddSR 和 TSD-SR 生成的图像相对清晰,但它们未能准确恢复衣领的设计。相比之下,FluxSR 重建的衣领更接近真实外观。图 5 的第二行展示了数字的恢复结果。FluxSR 生成了最逼真的结果,而 TSD-SR 虽然也大致恢复了数字,但受到 Sinc 噪声的影响,数字周围产生了明亮的边缘。
消融实验
本节使用 RealSR 作为测试数据集,训练迭代次数设置为 30k。
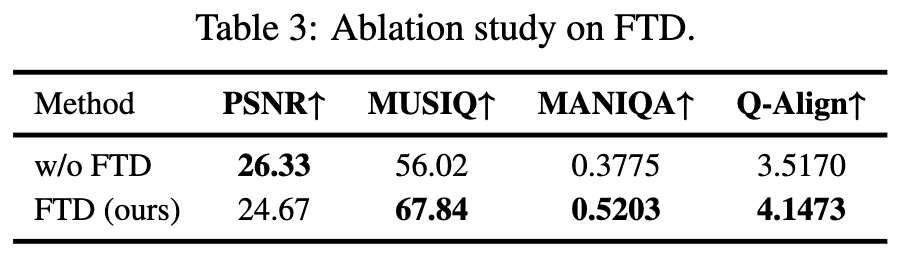
FTD 损失的有效性:为了验证 FTD 的有效性,将其与仅使用重建损失的训练进行了对比,结果如下表 3 所示。仅使用重建损失训练单步流模型会导致性能较差,无法生成高频细节并出现显著的高频伪影。使用提出的 FTD 损失不会破坏教师模型学习的数据分布,能够有效恢复高频细节并实现更高的真实感。
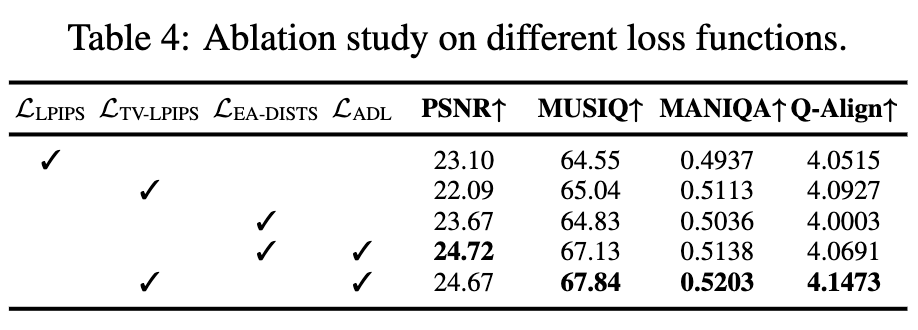
ADL 和 TV-LPIPS 的有效性:为了验证 ADL 和提出的 TV-LPIPS 损失的有效性,进行了相关的消融实验,研究每个损失函数组件的影响。此外还使用了 DFOSD 提出的 EA-DISTS 作为感知损失。下表 4 展示了实验结果,表明使用 TV-LPIPS 作为感知损失和 ADL 作为正则化项能够实现最佳性能。
结论与局限性
本文提出了 FluxSR,一种基于 FLUX(最先进的 T2I 扩散模型)的高效单步 Real-ISR 模型。FluxSR 利用流轨迹蒸馏(FTD)将多步流匹配模型蒸馏为单步超分辨率模型。它通过固定多步模型生成的噪声-图像对进行训练,不需要任何真实数据。本文采用 TV-LPIPS 和 ADL 来增强生成图像中的高频成分并减少周期性伪影。实验表明,FluxSR 实现了前所未有的真实感。
局限性:尽管 FluxSR 表现出色,但其参数量大且计算成本高。此外,尚未完全消除周期性伪影。未来,计划应用模型剪枝技术来压缩模型,并开发更有效的算法以防止周期性伪影,旨在实现轻量级且高性能的 Real-ISR 模型。
参考文献
[1] One Diffusion Step to Real-World Super-Resolution via Flow Trajectory Distillation

















 2332
2332

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









