








文章链接:https://arxiv.org/pdf/2411.08656
项目链接:https://kebii.github.io/MikuDance/
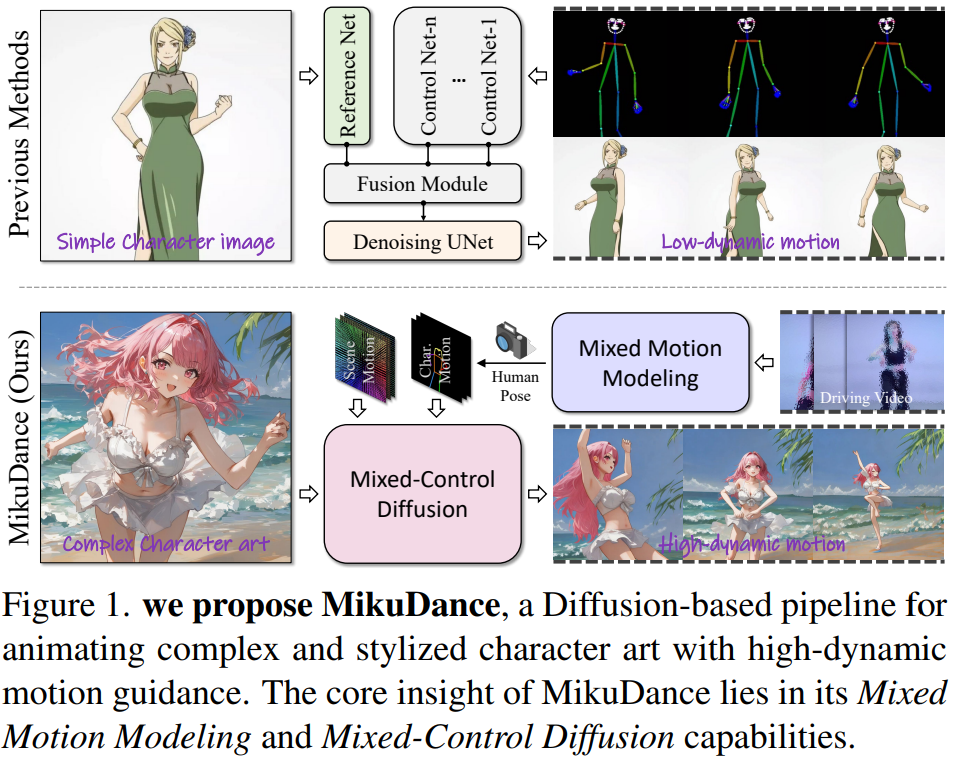
亮点直击
提出混合运动建模(Mixed Motion Modeling),用于在统一的逐像素空间中显式建模角色和相机运动,从而有效地表示高动态运动。
利用混合控制扩散(Mixed-Control Diffusion)隐式对齐角色的形状、姿势和比例与运动引导,从而实现角色艺术动画的连贯运动控制。
大量实验表明,MikuDance 的有效性和泛化能力,相较于最新的方法,能够实现更高质量的动画和高动态运动控制。
总结速览
要解决的问题
MikuDance 针对角色艺术动画中的两个主要难题:高动态运动和参考引导错位问题。
提出的方案
-
混合运动建模(Mixed Motion Modeling):通过场景运动跟踪策略(Scene Motion Tracking)对动态相机进行逐像素建模,实现角色与场景的统一运动建模。
-
混合控制扩散(Mixed-Control Diffusion):隐式地对多样角色的比例和体型进行运动引导对齐,从而灵活控制角色的局部运动。
应用的技术
-
场景运动跟踪策略(Scene Motion Tracking):显式建模动态相机,进行像素级空间的角色-场景运动建模。
-
运动自适应归一化模块(Motion-Adaptive Normalization Module):将全局场景运动注入角色动画中,支持全面的角色艺术动画生成。
达到的效果
通过大量实验,MikuDance 展现了其在各种角色艺术和运动引导场景中的有效性和泛化能力,生成的动画具有显著的运动动态效果和高质量的动画表现。


方法
入下图 2 所示,给定一个角色图像 和驱动视频 ,MikuDance 的目标是参考视频 中的人物和相机运动来动画化图像 。利用 Xpose 分别提取人体、面部和手部的姿势序列,并使用 DROID-SLAM 从 中提取相机姿势 ,其中 表示序列长度。角色的初始体态(与驱动视频相比在比例和姿势上存在显著差异)也从 中提取出来。接下来,通过 VAE 编码器将图像 和所有参考及驱动姿势图像编码到潜在空间中。相机姿势 经场景运动跟踪策略处理,以获得逐像素的场景运动引导。然后,利用混合控制扩散(Mixed-Control Diffusion)在潜在空间中将角色姿势和场景运动的混合运动引导作用于图像 ,以生成动画。最后,通过 VAE 时间解码器对潜在输出进行解码,以生成角色艺术动画。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









