




作者:叶子豪
原文:https://zhuanlan.zhihu.com/p/25920092499
在过去的两个月中,FlashInfer团队在密集地迭代优化DeepSeek MLA性能,并支持了DeepSeek MLA在prefill/decode/extend各个阶段的attention算子(支持SM_80/SM_89/SM_90,和任意的page大小),并在v0.2.2版[1]本中集中发布。在这篇文章中,我们将介绍近期我们一些版本中所做的一些优化,以及背后的思路。抛砖引玉,希望能启发到大家。
Prefill阶段的MLA计算与普通的MHA计算大致相同,唯一的区别在于需要支持q/k和v/o使用不同的head_dim,只需要简单修改attention模版即可(见 feat: support deepseek prefill attention shape by yzh119 · Pull Request #765 · flashinfer-ai/flashinfer[2])。而Decode和Extend阶段,我们需要单独设计高效的融合Page Attention算子,以便高效地与低秩kv-cache进行attention计算,相对于其它attention变体而言,MLA的挑战主要来自于以下两点:
-
• 矩阵吸收之后较大的head dimension (512)
-
• 矩阵吸收之后key和value共用同一个矩阵,流水线需要重新设计
我们将介绍flashinfer团队在这些问题上的解决方案(我们相信还有很多更好的设计),希望能引起大家的讨论和思考。
背景——MLA
对于MLA模型本身,已经有了很多的解读,推荐阅读苏神的文章了解背景: 缓存与效果的极限拉扯:从MHA、MQA、GQA到MLA [3]
背景——矩阵吸收
在推理阶段的注意力计算过程中,为了避免对 升维带来的显存带宽开销,我们可以改变矩阵的结合顺序(以下的推导省略了多头):,,以减少注意力算子的输入矩阵大小(I/O决定了解码阶段的效率),可以在注意力计算之前算好(在解码的过程中相对较小),这样整个Attention的计算转换为(同样,这里忽略了“头”的维度,其中和 均为多头矩阵)):
这个技巧叫做矩阵吸收,详细推导可以参考章老师的文章:DeepSeek-V2 高性能推理 (1):通过矩阵吸收十倍提速 MLA 算子[4]。通过矩阵吸收变换,我们可以将Multi-Head-Attention(MHA)计算转换成Multi-Query-Attention(MQA)计算,key和value共享一个 c_{kv} 矩阵,也就是MLA中的KV-Cache,其中没有“头”这个维度,query的部分有多头。
经过矩阵吸收变换之后,MLA的计算流程如下:
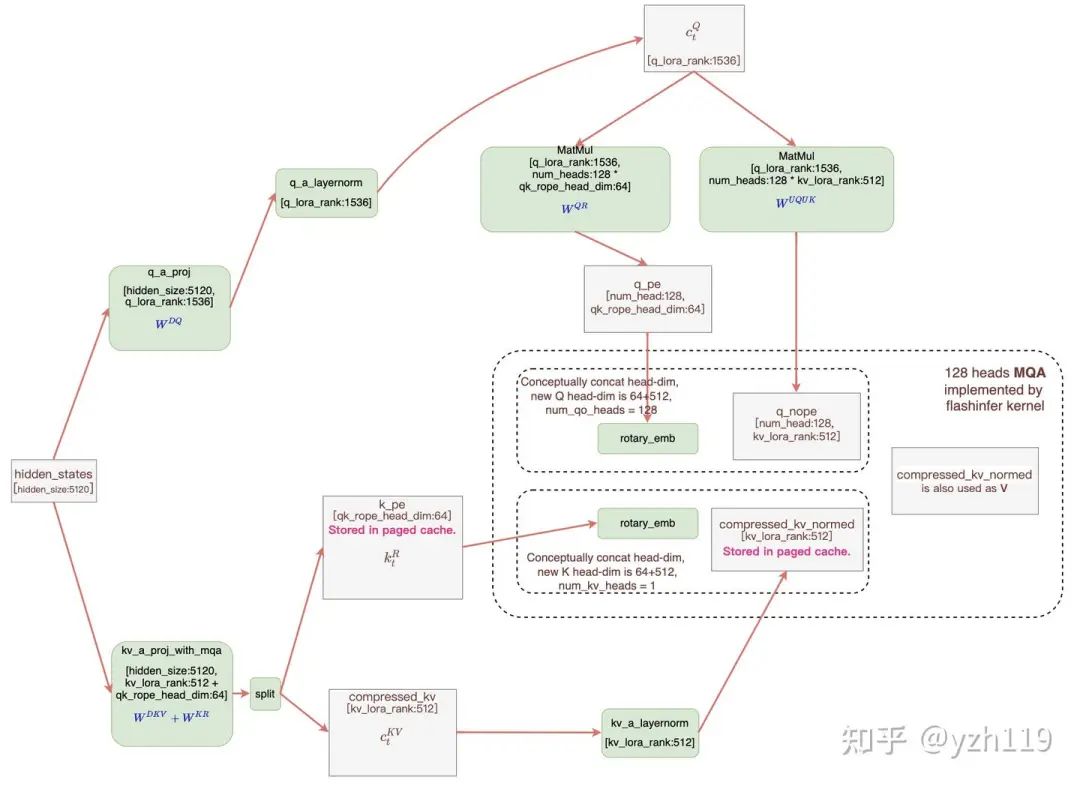
MLA计算流程(https://github.com/flashinfer-ai/flashinfer/pull/551),方框中是FlashInfer需要实现的MLA算子,其中c_kv被同时用做K和V,head_dim为512,rope部分的head_dim为64
可以用代码描述为:
q_pe = W_QR(c_q)
q_nope = W_UQ_UK(c_q)
output = W_UV_O(MQA(q_pe, q_nope, c_kv, k_pe))因此我们的目标是设计一个MQA算子,qk计算部分需要加上rope的维度(这块只需要简单地修改算子即可),重用key-cache和value-cache矩阵,同时需要支持较大的head_dim(512)。
是否需要融合算子?
在实现这个算子之前,我们先思考一个问题,我们是否需要这样一个融合算子:FlashAttention最初设计的初衷是减少对softmax矩阵储存以及方寸的开销,其大小正比于 ,占整体I/O的比值为:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2552
2552

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









