



原文:https://zhuanlan.zhihu.com/p/26113545571
连续五天的Deepseek opensource庆典,第一天是flash mla,放出来之后star数直升,对之前有人跟我说过的”做重要的工作citation自然就会很高“有了更直接的感受。今天开会之余,赶紧测一波性能看看,我也不知道是不是别人早就测过了,不过无所谓,测完先放在这里了。目前对于MLA的复现肯定有很多,时间太短测不过来,就把要测试的目标列在这里,有空了以后慢慢加:
-
• flashinfer【完成】
-
• tilelang
-
• sglang triton mla实现
-
• 清华翟老师团队 triton mla实现【完成】
测试脚本在这个PR里:feat: add benchmark for flash_infer vs flash_mla by KnowingNothing · Pull Request #35 · deepseek-ai/FlashMLA
https://github.com/deepseek-ai/FlashMLA/pull/35
写脚本卡了一会,卡在了flashinfer的输入形状定义和flash_mla的不太一样,导致正确性一直过不了,再就是flashinfer的pin_memory会在torch set default device的情况下有小bug。解决这些之后,直接测试,只看decode,所以只关注带宽结果。
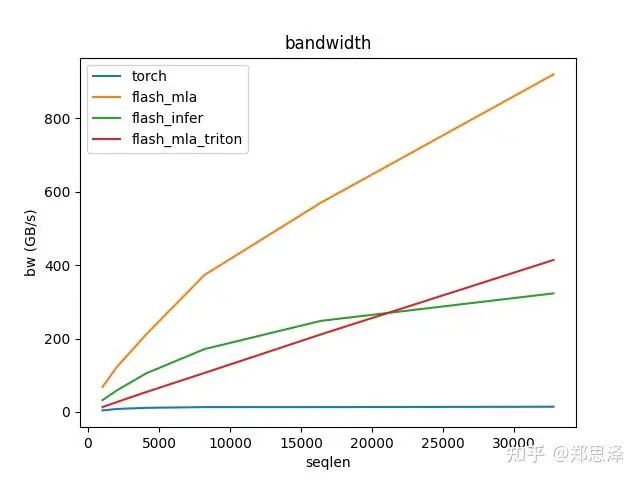
batch=1 q_head=16
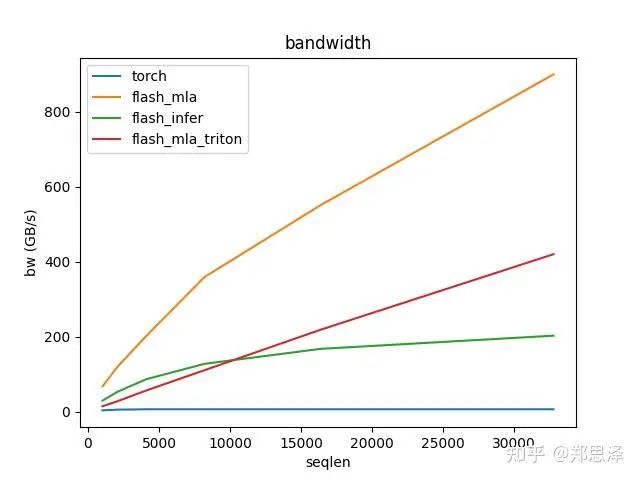
batch=1 q_head=32
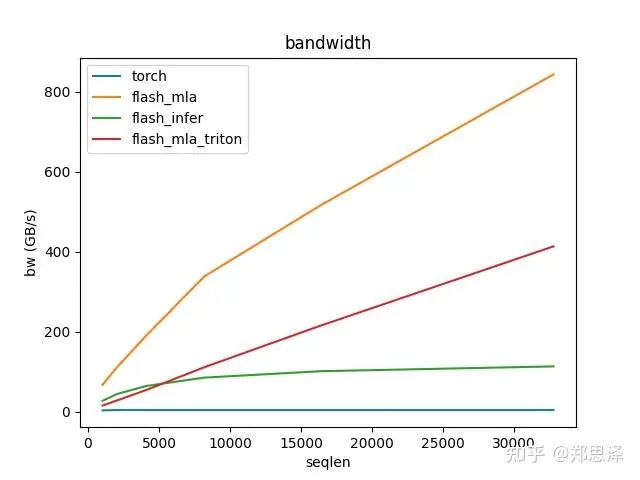
batch=1 q_head=64
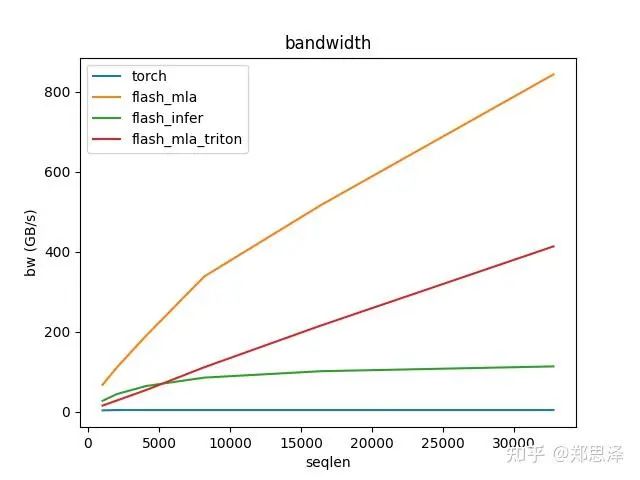
batch=1 q_head=128
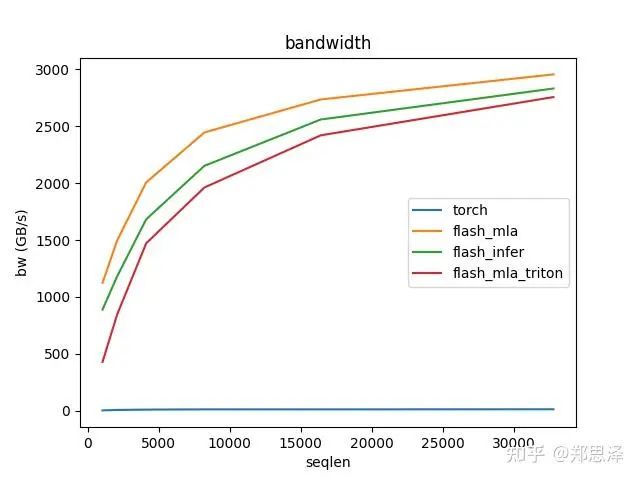
batch=32 q_head=16
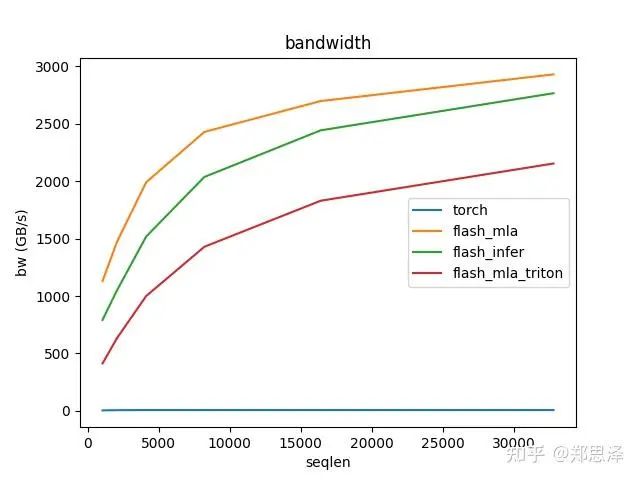
batch=32 q_head=32
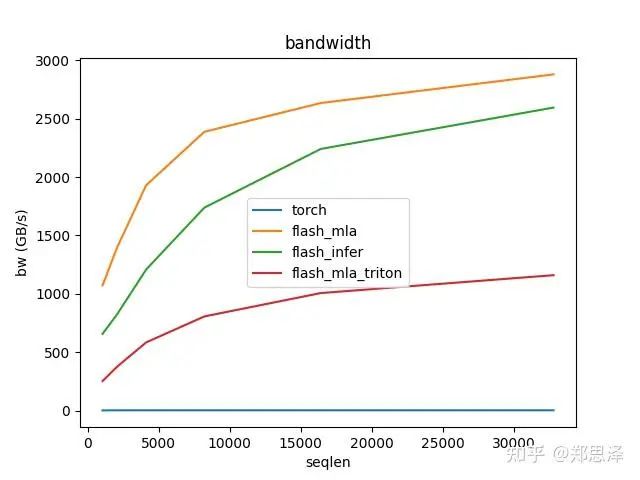
batch=32 q_head=64
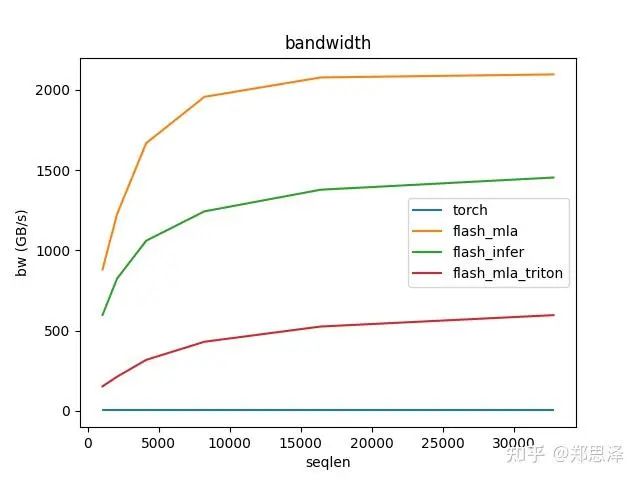
batch=1 q_head=128
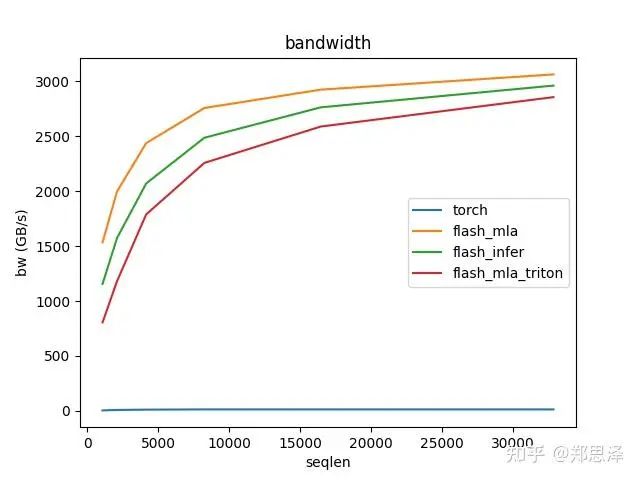
batch=64 q_head=16
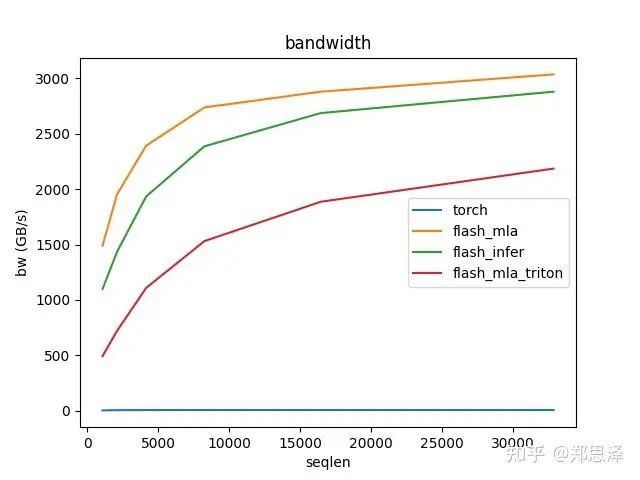
batch=64 q_head=32
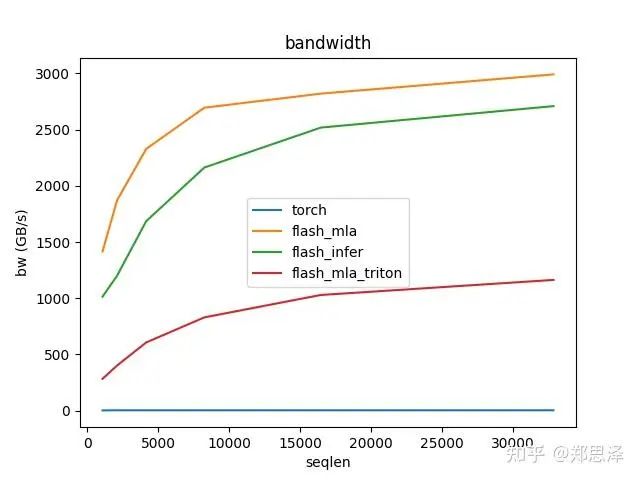
batch=64 q_head=64
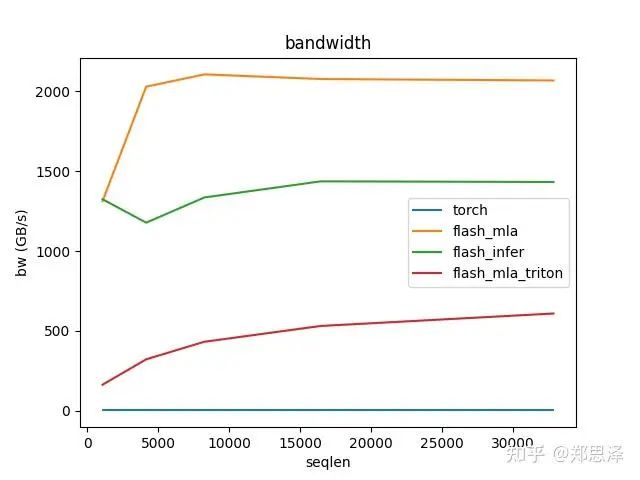
batch=64 q_head=128
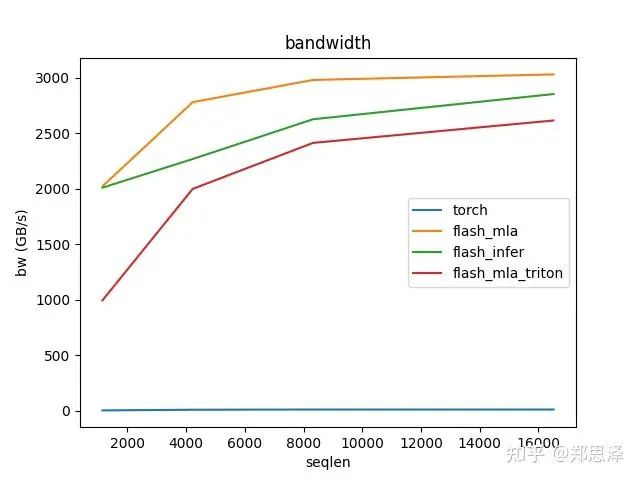
batch=128q_head=16
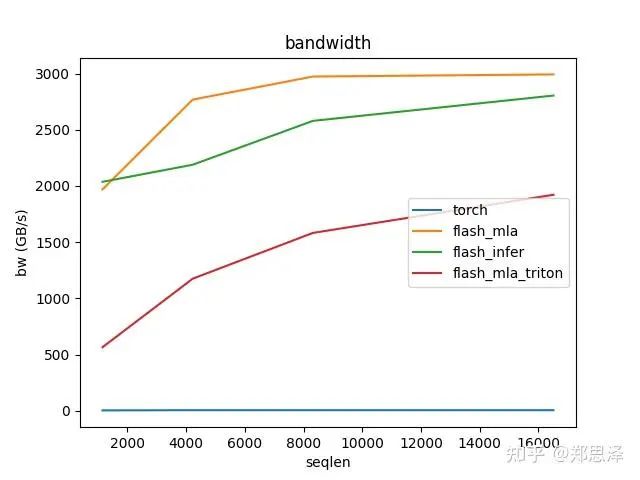
batch=128 q_head=32
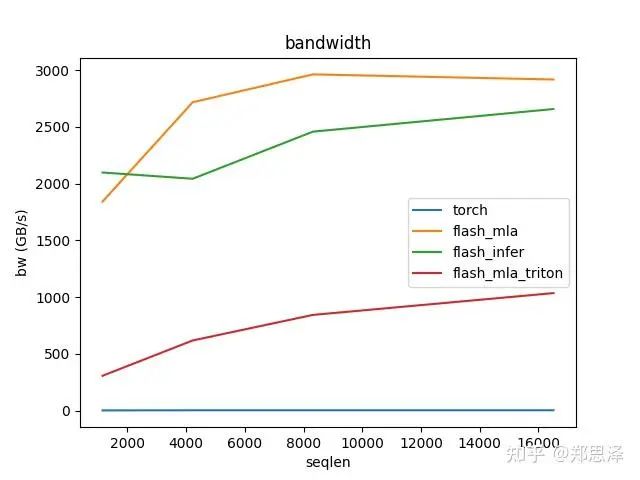
batch=128 q_head=64
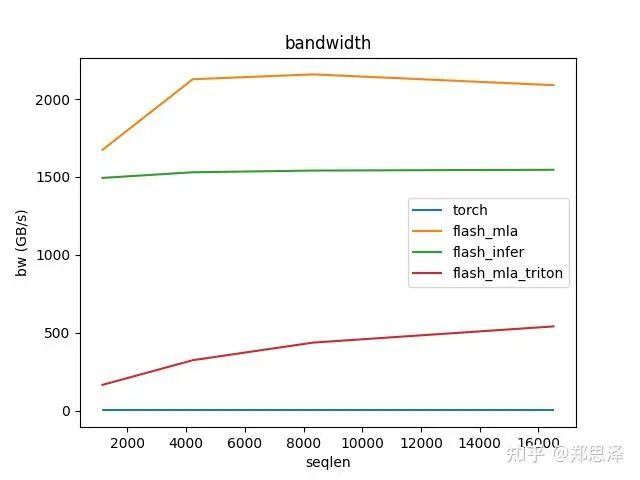
batch=128 q_head=128
总体来说deepseek官方实现都是最好的,flashinfer其次,triton实现的版本用的是翟老师团队一位同学的优化版本(optimize mla decode triton kernel · monellz/vllm@feebaa7[1]),组会上偶然听到,当时看到的结果是比flashinfer明显性能好,这里拿来测试一下本来是想证明triton实现高性能代码的能力,不过可能是因为组会上对比的flashinfer用的fa2后端,而现在我测的版本是fa3的版本,再加上我没有仔细调优,triton版本的性能不太理想,特别奇怪的是只对head=16性能好,其他的性能会骤降。之后如果调好了可以再重新测一下。
最近放出来的infra的东西,都是在我认知射程之内的东西了,相比之前v3和r1使不上劲的感觉,现在倒是能很快follow。不过infra只有和顶尖的芯片和顶尖的模型配合才有价值,单独卷infra是没有意义的,所以即使在射程之内了,另外两项缺憾却难以补足。
一个想法,在排除少数极强个体之外,未来能走在前沿的,一定是团队配合,这就首先排除了很多高校,因为高校博士生大多数都是单打独斗,形不成合力;
其次,能走在前沿的一定是占据了模型+infra+芯片三位一体紧密配合的优势,这又排除了很多大厂,因为尾大不掉和部门墙天然走向了另一条道路。
引用链接
[1] optimize mla decode triton kernel · monellz/vllm@feebaa7: https://github.com/monellz/vllm/commit/feebaa7c063be6bfb590a876741aeef1c5f58cf8

















 487
487

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









