 SFT数据清洗及JSON格式输出细节
SFT数据清洗及JSON格式输出细节




作者:ybq
链接:https://zhuanlan.zhihu.com/p/6497090767
最近在清洗 sft 的数据,不得不说这工作是真磨人啊,细节多到让人抓狂。可能,这就是为什么从业者们都懂得 llm 的方法论,却依然没几个团队能造出好数据训出好模型吧。
借此机会,举个例子给大家聊聊 sft 数据能有多少繁琐的细节?也算是吐槽和分享自己的日常了。
先说一下为什么都 2024 年底了,还需要清洗 sft 数据,这不应该是去年就已经完成的工作吗?因为数据会过时,去年的高质量数据不代表今年还是高质量数据。
例如,user:你会选择猫作为宠物还是狗呢?
-
去年的 gpt4:作为大语言模型,我无法养宠物,吧啦吧啦。
-
今年的 gpt4:猫吧啦吧啦,狗吧啦吧啦,虽然我没有实体,但我推荐你吧啦吧啦。
显然,在去年,过度的安全是在大家的认可和接受范围之内的,但今年只会让用户觉着无趣,因此这条数据需要清洗,需要拿 gpt4 重新标注再加人工重新 review —— 总之,只要 OpenAI 还在更新模型,还在努力的为我们提供优质的数据生产器,我们就没理由不清洗数据。
题外话说完了,下面我以一个巨简单的 case 作为切入点,来谈谈 sft 的数据细节有多繁琐。这个 case 就是"以 json 格式输出"。
json 大家都很熟悉吧,我就不解释了。在我的认知里,json 就是能被 json.loads() 调用成功且不报错的字符串,想让模型做到以 json 格式输出也很简单,让 answer 过两行代码就搞定了。
data = json.loads(line)
json_str = json.dumps(data, indent=2, ensure_ascii=False)
大家肯定不觉着 json 工作有啥好展开说的,但有没有一种可能,json 格式还有变种:
-
makrdown 格式,需要在字符串前后加 ``json 和 ``` ,一般默认都要带上;
-
intent = 4 呢 还是 intent = 2 呢还是 intent = 0 呢,prompt 说了还好办,prompt 要是没说呢,难道模型随机选一个数字来输出吗?我们需要统一 answer 中所有的 json 默认 intent;
-
有一种格式叫 jsonl,或者说是把 json 结果输出到一行中;
-
有一种需求叫不准进行 markdown 渲染;
-
有两种 prompt 分别叫:“先分析,再输出 json” 和 “除了 json,其他内容一律不准输出”;
-
……
emm,目前为止,大家可能还是不觉着 json 格式有多烦人,无非就是两个工作嘛:
-
选一个默认的 json 格式:带不带 markdown,intent 设置成几,是否输出在一行。然后把 sft 中所有涉及到的 json 数据全部清洗成这种格式;
-
补充那些对 json 格式有明确要求的 prompt,让模型不丢失灵活切换 json 格式的能力。
那我就继续提问:如果 prompt 里有 few_shot,但这个 few_shot 它是一个错误的 json,这时候是让模型模仿这个错误的 json 还是让模型严格按照 json 格式输出呢?
我随手测了下市面上体量最大的五家公司,好家伙给我五个答案 (do_sample = True):
-
4o: markdown + 标准 json + intent 2
-
豆包:标准 json + intent 0
-
kimi:markdown + few_shot_json + jsonl
-
qwen:few_shot_json + jsonl
-
文心:markdown + 标准 json + intent 4
你问我谁对,我只能说不知道。都是在尝试去 follow 格式,只不过有的模型是在 follow few_shot 的格式,有的模型是在 follow json 的格式。大家都对,全赢!我只是想用这个 case 强调,在训模型的时候,我们可以选用任何一种 json 风格,但是一定要统一。不要让模型随机出 json 风格,那不仅不利于模型训练,也会给用户的批量请求带来困扰。至于用哪种风格,让 PM 去调研一下客户需求即可。
大家也不要吐槽我的这个 prompt,觉着我是在没事儿找事儿,从业者应该都知道,这就是用户们最喜欢用的 prompt,你难道指望用户每次请求的时候,先去检验一下自己的示例是不是一个标准化 json 吗?单引号,中文引号,中文逗号,括号不匹配,……,各种错误比比皆是。
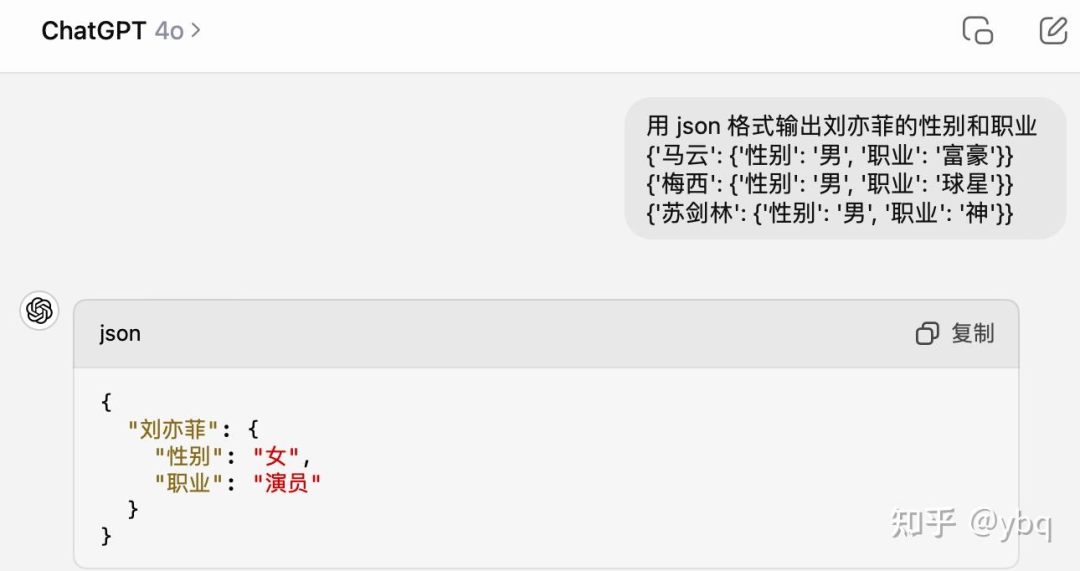
GPT4o
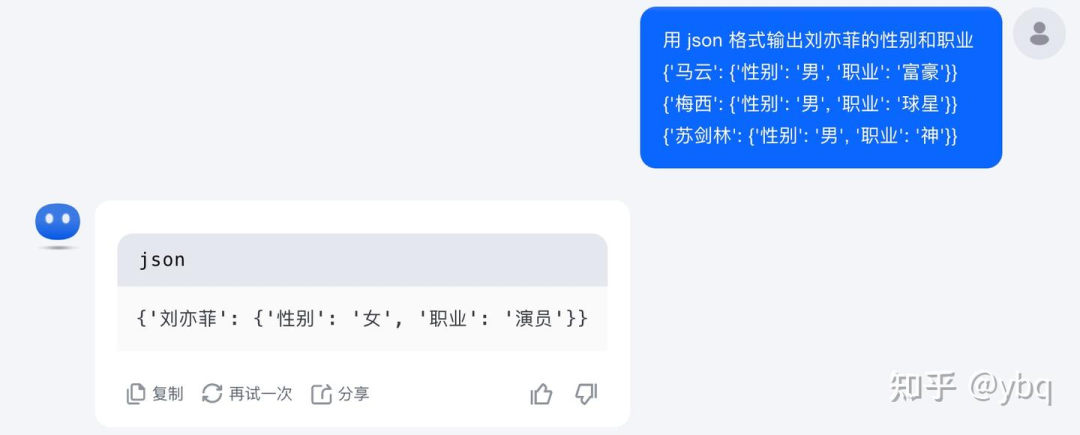
kimi

qwen 2.5
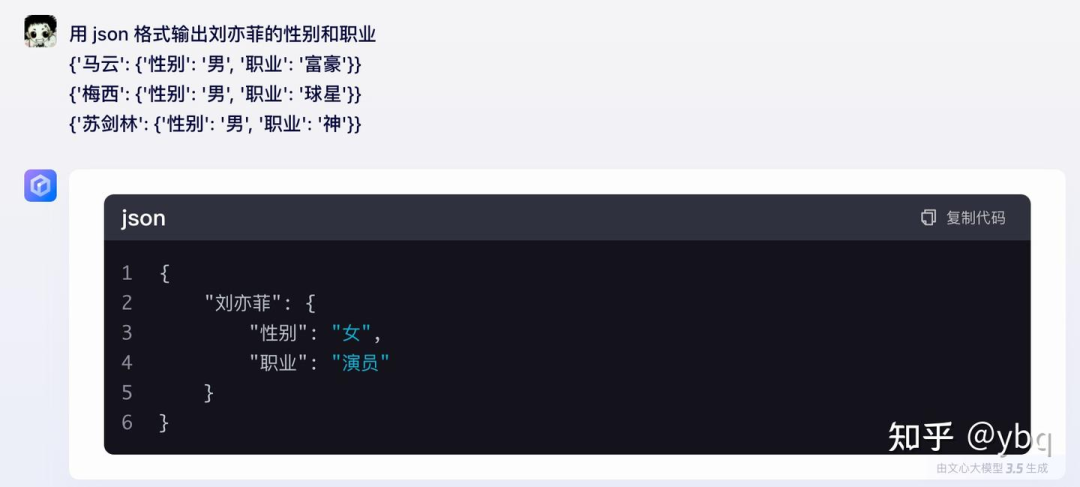
文心 3.5

豆包
到了这一步,你是不是有点认同我“以 json 格式输出”不是一个简单的工作了。但别着急,我还有一个问题要问:在数值任务上,针对数字,json 格式是使用 float / int 类型呢,还是 str 类型呢?
大家肯定都想选前者,我认同,但我要提醒一下,前者会影响模型的准确率,因为数值任务有个要素叫“单位”。
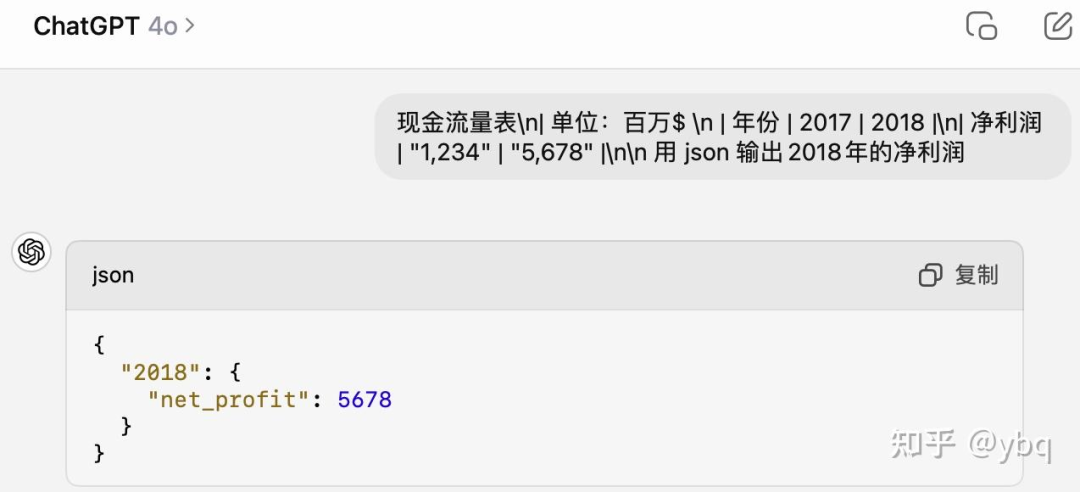
GPT4o
这里必须质问 ChatGPT 老师,我的单位“百万$” 去哪里了?虽然没有在 prompt 中明确指出要带单位,但这不应该是默认的常识吗?我们不能指望用户写出高质量的 prompt 呀。
当然,我并不是要为了拷打 ChatGPT 老师,我是想表达,在 next_token_prediction 的过程中,当模型的 “net_profit”: 的下一个 token 生成了数字 5,而不是双引号 " 的时候,神仙也救不回来这个 response 了。因为一旦没有输出引号,就代表模型选择了输出数值类型,那就必然没办法带单位了。这也就是我说的让模型习惯用 float / int 类型输出数值,可能会影响效果的原因。
不过也有补救办法,构造 sft 数据提醒模型每次额外输出一个 unit 字段。
{
"2018": {
"net_profit": 5678,
"unit": "百万$"
}
}
至此,“以 json 格式输出”的大多数细节,我已经强调完毕了。所有的细节总结下来,还是那句话:用什么格式不重要,只用一种格式很重要!
无独有偶,当我被 json 格式输出搞得焦头烂额的时候, https://www.zhihu.com/people/bf1764dccc55b8f831b89c9103f41564 同学也没好到哪里去。
最近深入研究数学的他,cot 数据不好造他不找我讨论,数据集翻译成中文后专有名词失真他不找我讨论,o1 造数据太贵他也不吐槽,但是他却因为一个问题来找我讨论:“你觉着模型输出的美元符号该不该带转义符号呢?”
-
数学数据有大量的 latex 表达式,都需要用 进行包裹起来,也就是:公式。那问题来了,美元 作为另外的含义,是不是得额外加个反斜杠呢?
-
当 表示美元的时候,它作为单位符号是不是不应该被公式$ 包裹起来(很多数据集包起来了)?
-
数值 1234 是不是应该全部写成 1,234?
-
如果全都要用 1,234 的表达方式,怎么实现批量替换呢?毕竟 公式 中的数字可不能给它加上这个逗号
-
……
这真是:你以为 llm 算法工程师在各种算法中挥斥方裘,实际上在和标点符号斗智斗勇。
最后强调一句,这仅仅是一个以 json 格式输出啊,sft 最基本的指令任务,至于那些复杂指令的数据如何构造、有多繁琐,只能靠大家自己去意会了。很多 llm 的工作不是想象中那么简单的,懂得怎么做仅仅是刚入门,只有实践了才知道有多少细节需要兼顾,有多少复杂的场景需要处理。我举的是洗符号、洗格式、洗 prompt 的例子,但还有更多的算法实践是举例举不出来的。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









