




知乎:Qs.Zhang张拳石
链接:https://zhuanlan.zhihu.com/p/2092355900
陈鹭,张拳石
Lu Chen, Yuxuan Huang, Yixing Li, Yaohui Jin, Shuai Zhao, Zilong Zheng, Quanshi Zhang, "Alignment Between the Decision-Making Logic of LLMs and Human Cognition: A Case Study on Legal LLMs" in arXiv:2410.09083, 2024.
大家好,我是陈鹭,是张拳石老师的访问实习博士生。
评测模型输出vs.评测模型内在逻辑。目前,对大模型的评测往往着眼于大模型输出结果本身的正确性(诸如幻觉问题和价值对齐问题)[1-3],然而在实际工业应用中,评测大模型表征可信程度的症结点在于评测大模型输出结果背后潜在决策逻辑的正确性,即神经网络是否使用正确的逻辑进行模型推断(inference)。事实上,我们发现尽管大模型在特定任务上已经展现出较高的准确率,其内在决策逻辑往往是非常混乱的。
然而,如何从数学上严格地解释神经网络内在的精细决策逻辑,是可解释性领域最大的挑战之一,即如何从理论上确保神经网络的解释结果是客观、可靠、且严谨的。这里,我们不能依赖一些工程近似方法(例如相关性方法或近似注意力机制)进行近似或拟合,因为这些方法往往在应用中无法给出解释严谨性的理论保障或实验验证。
幸运的是,团队之前基于交互的解释[3-4]已经证明了下面两个性质,从理论上保证了神经网络的决策逻辑可以被解释为稀疏的符号化交互概念。
-
证明一个在遮挡样本上平滑输出的神经网络(满足三个常见条件),在单个输入样本上,仅可以触发极少量的输入单元间的交互关系。例如,一个大语言模型,在输入句子上,仅仅触发 tokens 之间的 200 种交互效应;一个图像分类神经网络,在单个图像输入中,仅仅触发不同图像区域之间的少量交互效应。
-
理论证明给定一个包含 (n) 个输入单元的输入样本,基于触发的少量交互效应,可以精确拟合输入样本在 (2^n) 种任意遮挡状态下神经网络的所有输出值。
https://zhuanlan.zhihu.com/p/693747946
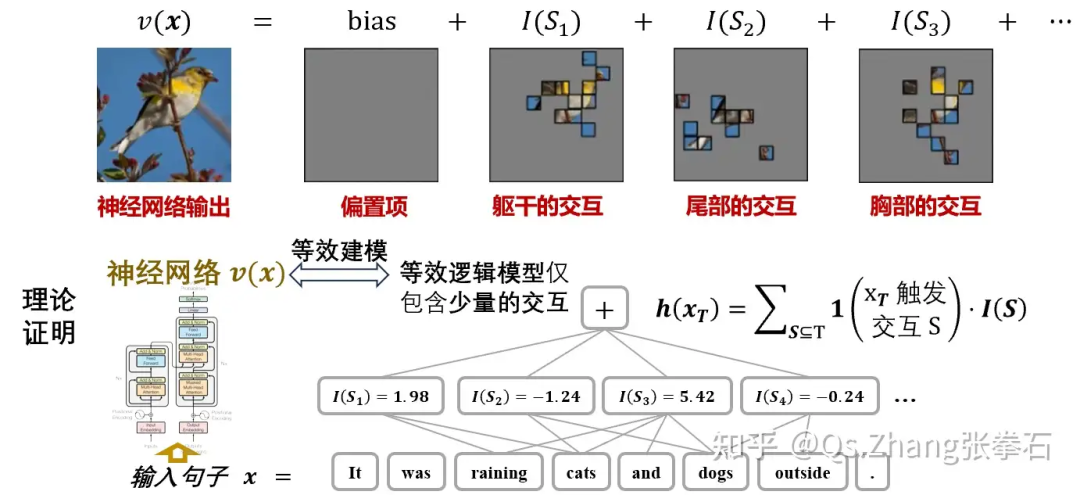
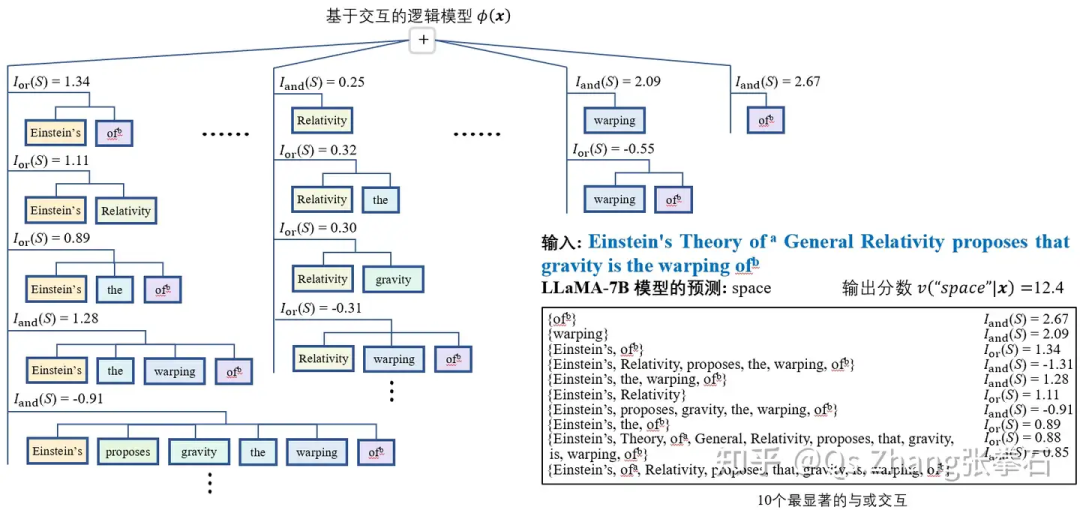
基于上述的理论基础,以法律大模型为例,我们发现尽管法律大模型判案结果的正确率很高,但哪怕在一些正确预测的法律案例中,超过一半的决策逻辑在人类认知上都是错误的。例如,我们发现大模型往往使用与判决结果无关的时间、地点或人物情感,或使用和案件无关的个人身份信息,来做出判决。基于等效交互理论,我们精确解释了神经网络的精细决策逻辑,并发现“使用错误或不相关的逻辑进行模型
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1219
1219

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









