




来源 | 机器之心 ID | almosthuman2014
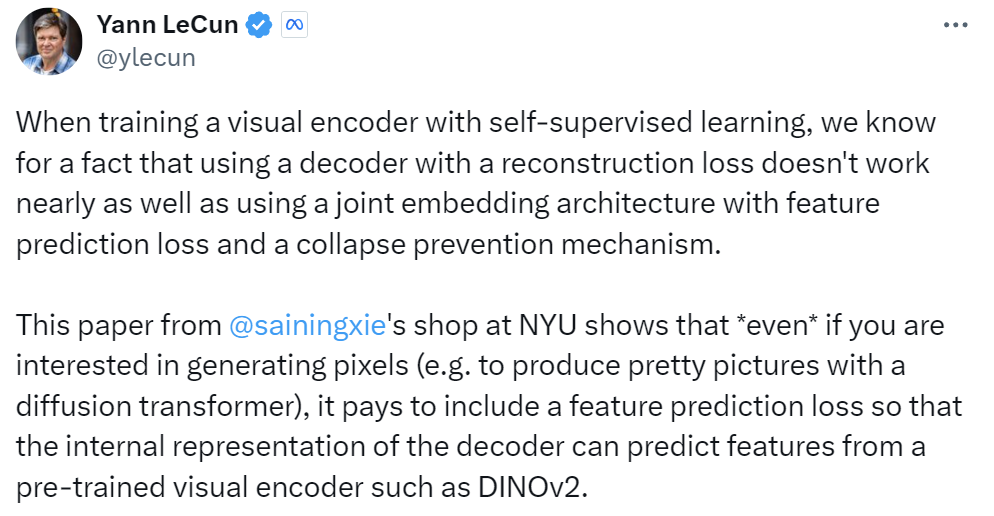
是什么让纽约大学著名研究者谢赛宁三连呼喊「Representation matters」?他表示:「我们可能一直都在用错误的方法训练扩散模型。」即使对生成模型而言,表征也依然有用。基于此,他们提出了 REPA,即表征对齐技术,其能让「训练扩散 Transformer 变得比你想象的更简单。」
Yann LeCun 也对他们的研究表示了认可:「我们知道,当使用自监督学习训练视觉编码器时,使用具有重构损失的解码器的效果远不如使用具有特征预测损失和崩溃预防机制的联合嵌入架构。这篇来自纽约大学 @sainingxie 的论文表明,即使你只对生成像素感兴趣(例如使用扩散 Transformer 生成漂亮图片),也应该包含特征预测损失,以便解码器的内部表征可以根据预训练的视觉编码器(例如 DINOv2)预测特征。」
我们知道,在生成高维视觉数据方面,基于去噪的生成模型(如扩展模型和基于流的模型)的表现非常好,已经得到了广泛应用。近段时间,也有研究开始探索将扩展模型用作表征学习器,因为这些模型的隐藏状态可以捕获有意义的判别式特征。
而谢赛宁指导的这个团队发现(另一位指导者是 KAIST 的 Jinwoo Shin),训练扩散模型的主要挑战源于需要学习高质量的内部表征。他们的研究表明:「当生成式扩散模型得到来自另一个模型(例如自监督视觉编码器)的外部高质量表征的支持时,其性能可以得到大幅提升。」
REPresentation Alignment(REPA),即表征对齐技术,便基于此而诞生了。这是一个基于近期的扩散 Transformer(DiT)架构的简单正则化技术。

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1584
1584

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









