




今天给大家带来一篇知乎@张俊林 大佬的文章,针对OpenAI o1原理进行逆向工程图解。
知乎:https://zhuanlan.zhihu.com/p/721952915
OpenAI o1的推出称为横空出世不为过,尽管关于Q*、草莓等各种传闻很久了,用了强化学习增强逻辑推理能力这个大方向大家猜的也八九不离十,但是融合LLM和RL来生成Hidden COT,估计很少人能想到这点,而且目前看效果确实挺好的。
OpenAI奔向Close的路上越走越远,你要从o1官宣字面来看,除了“强化学习生成Hidden COT”外,基本找不到其它有技术含量的内容。Sora好歹还给出了个粗略的技术框架图,字里行间也透漏不少隐含的技术点,细心点总能发现很多蛛丝马迹,串起来之后整个背后的技术就若隐若现。而且,尽管目前有不少公开文献在用LLM+RL增强大模型的推理能力,但几乎找不到做Hidden COT生成的工作,所以可供直接参考的内容非常少,这为分析o1进一步增添了难度。
那是否就没办法了呢?倒也不一定,如果多观察细节,再加上一些专业性的推论,我觉得还是有痕迹可循的。本文以相对容易理解的方式来对o1做些技术原理分析,试图回答下列问题:
-
除了复杂逻辑推理能力获得极大增强,o1还有其它什么重要意义?
-
o1的完整训练过程大致会是怎样的?
-
o1是单个模型,还是多个模型?
-
O1中的RL状态空间如何定义?行为空间如何定义?会用何种Reward Model?可能用何种训练数据?LLM和RM融合后的模型结构可能会是怎样的?
-
……
为行文中指称方便,我将文中推导的模型称为“Reverse-o1”。当然,里面有些部分有判断依据,有些则是根据主流技术作出的推断,只要OpenAI不官宣技术框架,大概一千个从业者能有一千种解法,我主要参考了AlphaZero的做法,试图在此基础上融合LLM和RL,很多看法比较主观,谨慎参考。
OpenAI o1的重要意义
我个人认为OpenAI o1是大模型技术领域的一个巨大突破,除了复杂逻辑推理能力获得极大提升外,这里展开分析下它在其它方面的意义和价值所在。
首先,o1给大模型带来了自我反思与错误修正能力,我觉得这点价值特别大。 GPT 4这类模型,因为在输出答案的时候是逐个Token输出,当输出长度较长的时候,中间某些Token出错是一定会发生的,但即使LLM后来知道前面输出的Token错了,它也得将错就错往下继续编(这也是大模型幻觉的来源之一,为了看上去逻辑合理,LLM得用100个错误来掩盖前面的第一个错误),因为落Token无悔,没有机制让它去修正前面的错误。
而o1在“思考”也就是生成Hidden COT的过程中,如果你分析过OpenAI官网给出的Hidden COT例子的话,会发现它确实能意识到之前犯错了,并能自动进行修正。这种自我错误识别与修正对于LLM能做长链条思考及解决复杂任务非常重要,相当于越过了一个锁住LLM能力的很高的门槛。
第二,所谓新型的RL的Scaling law。 OpenAI自己PR可能更强调这点,各种解读也比较看中这一点。我猜测o1的RL大概率要么用了相对复杂的、类似AlphaGo的MCTS树搜索,要么用了简单树结构拓展,比如生成多个候选,从中选择最好的(Best-of-N Sampling),这种策略如果连续用,其实也是一种简单的树搜索结构。也有可能两者一起用。不论怎样,树搜索结构大概率是用了,COT是线性的不假,但这是产出结果,不代表内部思考过程就一定是线性的,我觉得靠线性思维推导过程很难解决复杂问题,树形结构几乎是不可避免的。
有人问了,你有证据能说明o1大概率用了搜索树结构吗?我没有证据,但是可以推断,我的判断依据来自于o1 mini。之前的研究结论是这样的:尽管小模型语言能力强、世界知识还可以,但逻辑推理能力很难提起来,即使你通过比如蒸馏等措施试图把逻辑能力内化到小模型的参数里,效果有但有限,小模型和大模型差距最大的能力就是逻辑推理能力了。意思是说,纯靠参数内化来提升小模型的逻辑推理能力估计提升幅度有限。但o1 mini明显是个小模型,其复杂逻辑推理能力非常强,而且看样子可通过配置来提升或者降低它的逻辑推理能力(所谓inference-time Scaling law),如果你了解AlphaGo的运作机制的话,会发现这都是比较典型的搜索树的特点,可以通过控制搜索空间大小来提升模型能力。
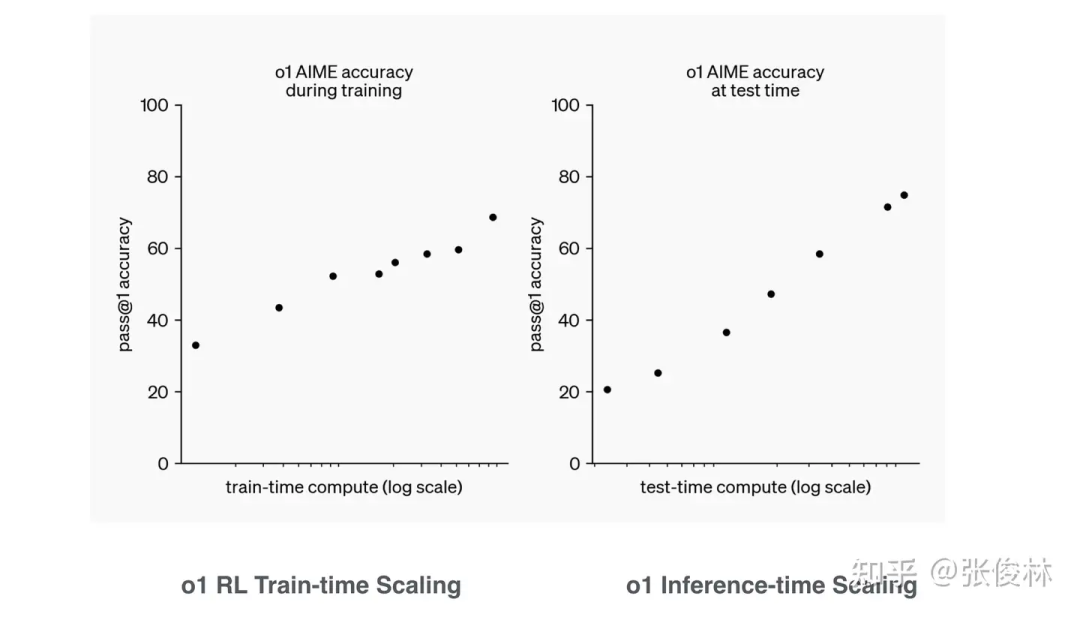
虽然我个人认为,如果把通过设置参数来控制如何拓展树结构(比如控制搜索的宽度和深度),这种模式如果能被称为Scaling law的话,多少有点勉强,若这样,那我们可以说2006年AlphaGo出来就有Scaling law了。
但不管怎么称呼它,无法忽视的是这种方法的可扩展性极好,无论是在RL训练阶段,还是LLM的Inference阶段,只要改下参数配置来增加树搜索的宽度和深度,就能通过增加算力提升效果,可扩展性好且方式灵活。从这点讲,o1确实具有重要意义,因为这证明了它把怎么融合LLM和树搜索这条路走通了,LLM模型能够达到AGI的上限就被提高了一大截。
第三,在o1之后,小模型大行其道真正成为可能。 小模型最近大半年也比较火,但从能力获取角度看,其实还是有上限锁定的,这个锁定小模型上限的就是逻辑推理能力。上面提到了,小模型的能力特点是:语言能力很强不比大模型弱、世界知识不如大模型但是可以通过给更多数据持续提升、受限于模型规模,逻辑推理能力能提升但比较困难。
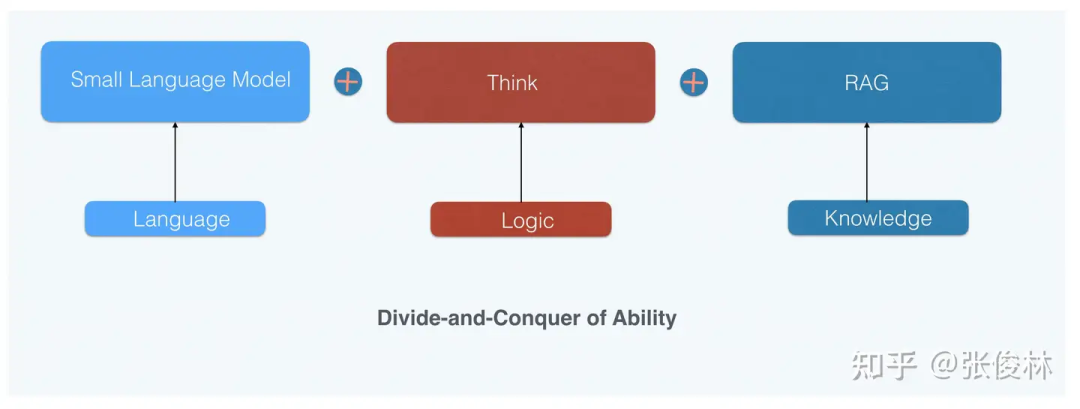
所以小模型的优化重点是世界知识和逻辑推理能力,而从o1 mini的效果(世界知识弱、逻辑推理强)可推出,之后我们可以采用“能力分治”(DCA,Divide-and-Conquer of Ability)的模式推进小模型的技术发展(参考上图):把语言、世界知识及逻辑推理三个能力解耦,语言能力靠小模型自身、逻辑推理靠类似o1的通过RL获得的深度思考能力,而世界知识可以靠外挂RAG获得增强。
通过“能力分治”,小模型完全可能具备目前最强大模型的能力,这等于真正为小模型扫清了前进路上的障碍,而SLM做起来成本又比较低,很多人和机构都可以做这事,所以可以预测:之后这种DCA模式将会大行其道,形成一种新的研发小模型的范式。
第四,o1可能会引发“安全对齐”新的范式。 O1在做安全对齐方面,大概采用了类似Anthropic的“AI宪法”的思路,就是说给定一些安全守则,指明哪些行为能做,哪些不能做,在o1逻辑推理能力提高之后,它遵循这些法则的能力也获得了极大增强,安全能力比GPT 4o强很多。这可能引发安全对齐新的模式:大家可以先把模型的逻辑推理能力加强,然后在此之上采取类似“AI宪法”的思路,因为OpenAI o1证明这种模式可极大增强大模型的安全能力。
第五,“强化学习+LLM”的领域泛化能力,可能不局限于理科领域。 强化学习适合解决Reward比较明确的复杂问题,典型的是数理化、Coding等有标准答案的学科,所以很多人会质疑o1是否能泛化到更宽的领域。确实,o1的思考能力能否泛化到没有明确标准答案、Reward不好量化的领域是它发展的关键,泛化得好,则打开阳光大道,泛化得不好,领域局限性就会比较强。
我推测OpenAI可能已经找到了一些非数理学科的Reward定义方法,并将这个方法通过RL拓展到更多领域。既然o1可以读懂并遵循安全规则,以 “AI宪法”的思路解决安全问题,我觉得由此可以推导出一种针对模糊标准的Reward赋予方法:就是说针对不好量化的领域,通过写一些文字类的判断标准或规则,让大模型读懂并遵循它,以此来作为是否给予Reward的标准,符合标准则Reward高,否则Reward低。例如,针对写作文,就可以列出好文章的标准(结构清晰、文笔优美等规则),让大模型据此来给Reward。如此就能拓展到很多领域。
当然,想要这么做可能要分步骤,先用好给Reward的数理问题增强模型的复杂推理能力到一定层级,这样它就能看懂规则了,然后再做那些不好量化Reward的领域。(这都是我的猜测,没有依据)
由上述分析可看出,o1这条技术方向不仅增强了模型的复杂逻辑能力,由此可能引发大模型研发很多重要方向的革新,这是为何我说o1重要的主要原因。
OpenAI o1的完整训练过程推演

GPT 4等LLM模型训练一般由“预训练”和“后训练”两个阶段组成(参考上图)。“预训练”通过Next Token Prediction来从海量数据吸收语言、世界知识、逻辑推理、代码等基础能力,模型规模越大、训练数据量越多,则模型能力越强,我们一般说的Scaling Law指的是这一阶段的模型扩展特性,也是LLM训练最消耗算力资源的地方。“后训练”则分为SFT、RM和PPO三个过程,统称为人工反馈的强化学习(RLHF),这一阶段的主要目的有两个,一个是让LLM能遵循指令来做各种任务,另一个是内容安全,不让LLM输出不礼貌的内容。而训练好的模型推理(Inference)过程则是对于用户的问题直接逐个生成Token来形成答案。
OpenAI o1的整个训练和推理过程应与GPT 4这类典型LLM有较大区别。首先,“预训练”阶段应该是重新训练的,不太可能是在GPT 4o上通过继续预训练得到。 证据很好找,OpenAI官方一再宣称o1 mini逻辑推理能力极强,但在世界知识方面很弱。如果是在其它模型上魔改的,世界知识不会比GPT 4o mini更弱,所以侧面说明了是重新训练的;另外,这也说明了o1这类侧重逻辑推理的模型,在预训练阶段的数据配比方面,应该极大增加了逻辑类训练数据比如STEM数据、代码、论文等的比例,甚至我都怀疑o1 m
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1075
1075

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









