



最近又被DeepSeek的新模型刷屏了。说实话,AI圈天天有新品,但这次发布的DeepSeek-OCR,真的让人眼前一亮。
虽然叫OCR,但它干的远不止是文字识别那么简单。这可能是近期最有趣的技术突破之一。

一、这不是你认识的OCR
大家都知道传统的OCR是个“文字搬运工”,把图片里的字抠出来变成可编辑的文本,任务就完成了。

但DeepSeek-OCR看完一张复杂的金融研究报告,能直接生成一个Markdown文档,里面的图表甚至能用代码重新绘制出来。这已经超出了传统OCR的能力范围。
二、核心创新:把文字当图片“看”
这项技术最酷的地方在于它处理长文本的思路。现在的AI读长文档,就像一个字一个字地指着读,不仅慢,而且记不住太多内容。DeepSeek-OCR换了个思路:给整页文字“拍张照”,把几千字的文章压缩成一张信息高度浓缩的“缩略图”。
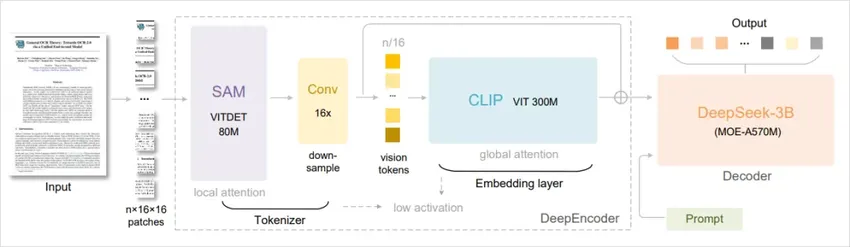
这就是所谓的“上下文光学压缩”——用视觉模态压缩长文本信息。
效果如何?1000字的文本压缩为约100个视觉token,实现10倍的压缩效率,而且在10倍压缩比下,解码精度可达97%。
三、为什么这很重要?
长文本处理一直是AI的痛点。传统模型处理长文本时,计算量会随着文本长度平方级增长,成本极高。
DeepSeek-OCR的解决方案很巧妙:最近的对话用文本形式记录,历史对话渲染成图片压缩存储。
当需要查询历史信息时,AI能快速从压缩的视觉token中还原出原文。
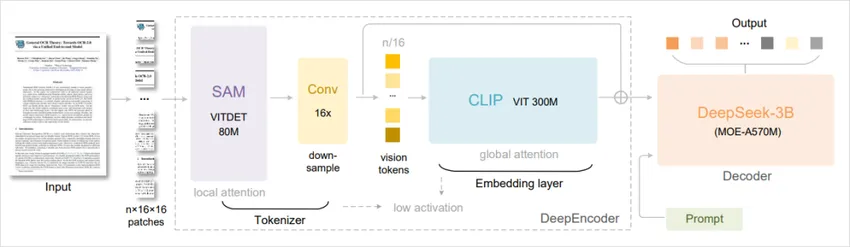
这意味着未来我们可以将整个文档库或代码库一次性输入给AI处理,成本大幅降低。
四、更酷的:数字生命的“遗忘曲线”
最让我震撼的是论文最后提到的一个设想:对于更久远的记忆,可以逐步缩小渲染图像来进一步减少资源消耗。
这几乎完美地模拟了人类的遗忘曲线——最近的信息记得很清晰,而遥远的记忆自然淡忘。
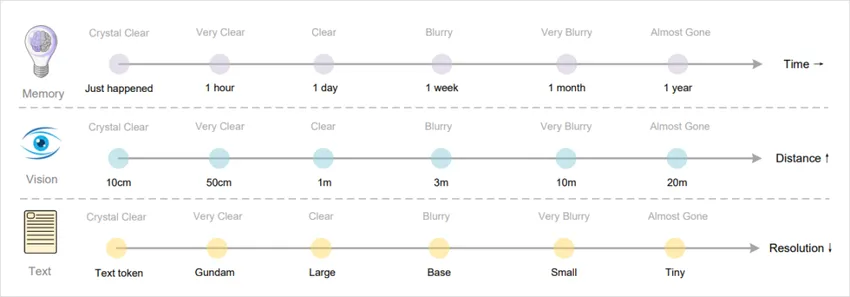
⭐我们总在追求AI的完美记忆,但或许,懂得遗忘才是真正的智能。
📌划重点
- 技术核心:将文本转换为图像处理,实现10倍压缩比
- 实际价值:突破长文本处理瓶颈,大幅降低成本
- 范式创新:挑战了“文本优于图像”的传统认知
- 开源精神:DeepSeek再次开源,推动技术普及
这项技术还在早期,但为我们打开了新的想象空间。AI的发展路径,往往就藏在这些“反直觉”的突破中。体验地址:
https://github.com/deepseek-ai/DeepSeek-OCR

















 327
327

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









