






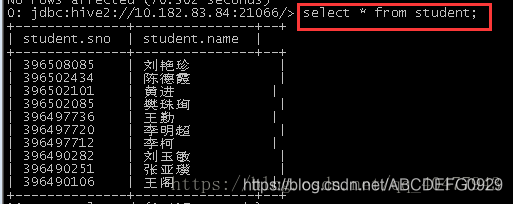
现有一个表student:
select * from student;
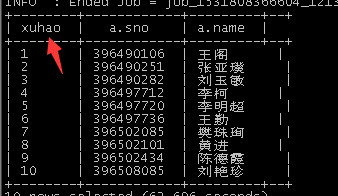
然后加上一列序号:
select row_number() over(partition by 1) as xuhao,
a.*
from student a;
得到结果:
转载自:https://blog.youkuaiyun.com/qq_40477943/article/details/81873293
 本文介绍如何使用SQL语句为现有的student表添加一列序号。通过row_number()函数结合partition by子句实现对表中每条记录进行编号。
本文介绍如何使用SQL语句为现有的student表添加一列序号。通过row_number()函数结合partition by子句实现对表中每条记录进行编号。
现有一个表student:
select * from student;
然后加上一列序号:
select row_number() over(partition by 1) as xuhao,
a.*
from student a;
得到结果:
转载自:https://blog.youkuaiyun.com/qq_40477943/article/details/81873293

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





















 4万+
4万+





