






决策树基本理论
决策树思想
程序设计中的条件分支结构是if-else分支结构,最早的决策树就是利用这类结构分割数据。
目的:找到最高效的决策顺序。
决策树概念
决策树(Decision Tree)是一种基于树结构的分类或回归模型,在机器学习领域中被广泛应用。
决策树模型将样本数据集根据特征属性进行划分,每个节点代表一个特征属性,每个分支代表该特征属性的取值,叶子节点代表分类结果。这样,样本数据集就被划分为一系列子集,每个子集对应决策树的一个叶子节点。
决策树的构建过程是递归的,从根节点开始,选择一个最优的特征属性进行划分,然后递归地对每个子节点进行相同的操作,直到所有叶子节点都代表了一个类别或达到了停止条件,如达到最大深度、样本数量小于阈值等。
决策树模型具有易解释、易实现、效果稳定等优点,但也存在容易过拟合、对噪声敏感等缺点。针对这些问题,可以通过剪枝和集成学习等技术进行优化。
决策树的优缺点
优点:
1.易于理解和解释。由于决策树模型基于树形结构,因此可以直观地展示特征属性之间的关系,易于解释。
2.适用于多种类型的数据。决策树模型可以处理分类、回归等不同类型的数据。
3.能够处理非线性关系。与线性模型不同,决策树模型可以处理非线性关系,适用于复杂的问题。
缺点:
1.容易过拟合。当决策树过于复杂时,容易出现过拟合现象,影响模型的泛化能力。
2.对噪声敏感。样本数据中存在异常值或噪声时,会影响决策树的划分效果。
3.不稳定。当样本数据发生变化时,决策树模型可能会发生较大的变化,导致模型不稳定。
构建决策树的流程
构建决策树的基本流程包括以下步骤:
数据预处理:收集并准备用于构建决策树的数据集。包括数据清洗、处理缺失值和异常值等。
特征选择:选择最佳的特征属性作为初始根节点。常用的特征选择算法包括信息增益、信息增益比、基尼系数等。
构建节点:将选定的特征属性应用于当前节点,根据特征属性的不同取值划分出子节点。每个子节点代表一个特征属性取值。
递归分裂:对于每个子节点,重复步骤2和步骤3,直到满足终止条件。终止条件可以是达到最大深度、样本数量小于阈值等。
叶节点标记:对于每个叶节点,根据样本集合中的类别标签进行分类或预测结果的标记。
剪枝处理:对构建好的决策树进行剪枝处理,以避免过拟合。常见的剪枝方法有预剪枝和后剪枝。
决策树的评估:使用独立的测试数据集对决策树进行评估,计算准确率、精确率、召回率等指标,判断模型的性能。
决策树的应用:使用构建好的决策树进行分类或预测任务。对新样本进行测试时,根据特征属性逐步下行,最终到达叶节点得到分类或预测结果。
信息增益
信息增益是一种常用的特征选择准则,用于决策树算法中的特征选择步骤。信息增益的目标是选择对分类具有最大区分度的特征。
信息增益的计算基于信息熵的概念,信息熵衡量了样本集合的不确定性。信息熵的值越大,样本集合的不确定性就越高,反之亦然。信息增益是指在已知某个特征属性的条件下,对样本集合的不确定性减少的程度。
计算信息熵:
Ent(D) = - ∑ P(x_i) * log_2 P(x_i)
其中,p 表示样本属于某个类别的概率。
假定离散属性 a 有 V 个可能的取值 ,若使用a 来对样本集 D 进行划分,则会产生 V 个分支结点,其中第 v 个分支结点包含了 D 中所有在属性a 上取值为 的样本,记为Dv,我们可根据式 (4.1) 计
算出Dv 的信息熵。
再考虑到不同的分支结点所包含的样本数不同,给分支结点赋予权重 |Dv| / |D| , 即样本数越多的分支结点的影响越大,
计算出用属性a 对样本集 D 的信息增益:
Gain(D, A) = Ent(D) - ∑ (|D^v| / |D|) * Ent(D^v)
增益率
增益率是在决策树算法中用来选择分裂属性的一种方法,它考虑了特征的固有不确定性,以此来平衡特征取值数量对信息增益的影响。具体来说,信息增益率的计算涉及两个主要部分:信息增益和固有值。
- 信息增益(Information Gain):信息增益反映了在知道某个特征的信息之后,分类不确定性减少的程度。它的计算公式是原始数据集的熵减去按照某特征划分后子集的加权熵之和。
- 固有值(Intrinsic Value,IV):固有值是指特征本身的信息熵,即特征取值的不确定性。它是所有可能的特征值的熵的总和。
信息增益率的计算公式可以表示为:
信息增益率=增益率/固有值
属性的可能取值数目越多,则固有值通常就越大
基尼指数
基尼指数(Gini Index)是衡量样本集合的不纯度或杂质程度的一种指标,常用于决策树算法中的特征选择和节点划分。
基尼指数的计算基于样本集合中不同类别的分布情况。对于一个具有K个类别的样本集合,基尼指数可以表示为:
Gini = 1 - ∑(n_i * (i - 1) + 0.5)/ n^2
其中n是样本容量,n_i是第i个类别的样本数
Gini(D)越小,数据集D的纯度就越高。
剪枝处理
剪枝处理通过删减或跳过一些无需进一步探索的分支或节点,以减少搜索空间的大小。这样做可以节省计算资源,并加速算法的执行。剪枝处理的关键在于确定哪些分支或节点可以被剪掉,以及何时进行剪枝操作。
决策树算法中,剪枝处理被用来防止过拟合。决策树是一种用于分类和回归的机器学习算法,通过逐步划分特征空间来构建树形结构。但如果决策树过于复杂,可能会对训练数据过度拟合,导致在新数据上的泛化性能下降。剪枝处理可以通过删除一些叶子节点或合并一些相似的节点来简化决策树,以避免过拟合问题。
决策树算法中剪枝处理通常有两种:
预剪枝: 预剪枝是在构建决策树的同时进行剪枝操作。在每个节点进行划分之前,通过一些预定义的条件来判断是否应该继续划分子节点,从而避免生成过于复杂的树结构。
预剪枝可以有效地减少决策树的规模和复杂度,防止过拟合问题的发生。然而,它可能会导致欠拟合,因为可能会提前停止划分,忽略了一些潜在的划分特征。
后剪枝: 后剪枝是在构建完整的决策树后进行剪枝操作。它先使用训练数据构建完整的决策树,然后通过剪掉一些子树或叶子节点来简化树结构。
后剪枝通过在验证集上评估剪枝效果,可以更准确地选择剪枝点,避免过拟合问题,并提高模型的泛化能力。
决策树的实现
本次实验中使用了鸢尾花数据集作为示例数据
根据信息增益进行决策
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier, plot_tree
import matplotlib.pyplot as plt
# 加载数据集
iris = load_iris()
# 定义决策树模型,设置criterion参数为'entropy',表示使用信息增益进行决策
clf = DecisionTreeClassifier(criterion='entropy')
# 训练模型
clf.fit(iris.data, iris.target)
# 绘制决策树
plt.figure(figsize=(10, 6))
plot_tree(clf, filled=True, feature_names=iris.feature_names, class_names=list(iris.target_names))
plt.show()运行结果为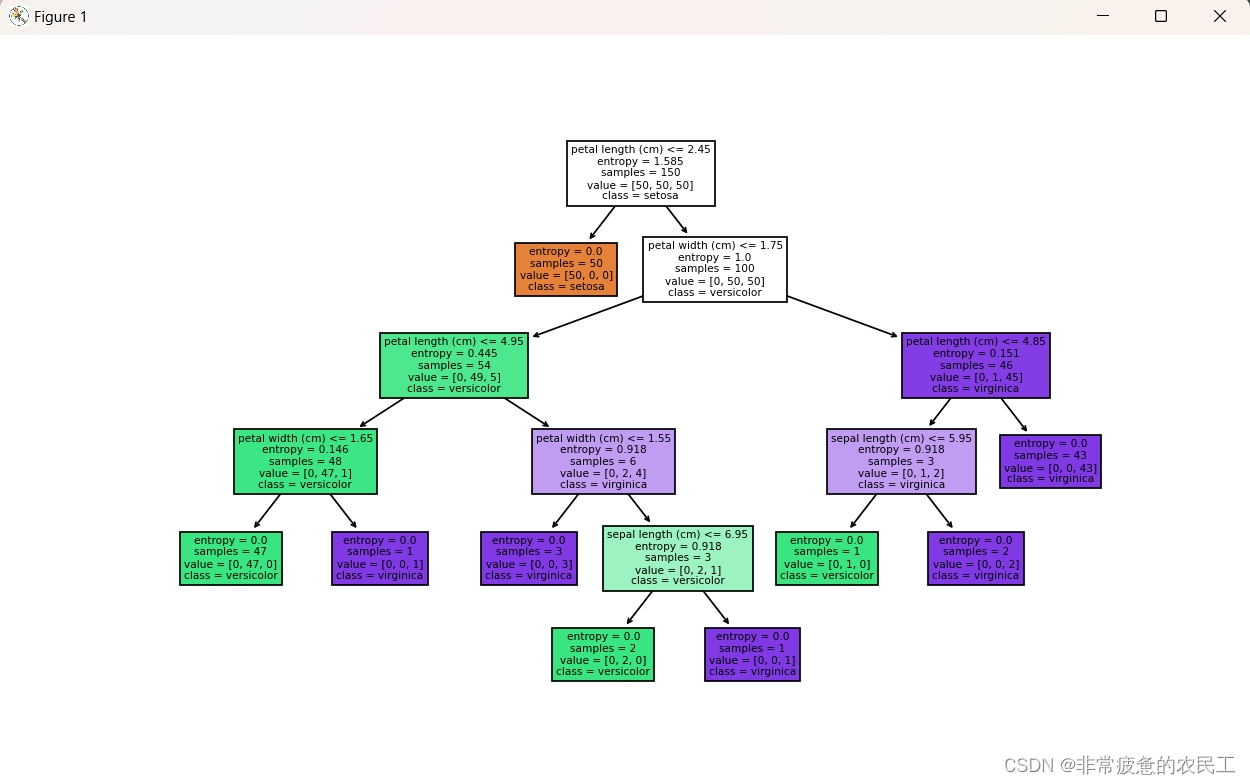
根据基尼指数进行决策
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier, plot_tree
import matplotlib.pyplot as plt
# 加载数据集
iris = load_iris()
# 定义决策树模型
clf = DecisionTreeClassifier()
# 训练模型
clf.fit(iris.data, iris.target)
# 绘制决策树
plt.figure(figsize=(10, 6))
plot_tree(clf, filled=True, feature_names=iris.feature_names, class_names=list(iris.target_names))
plt.show()
运行结果为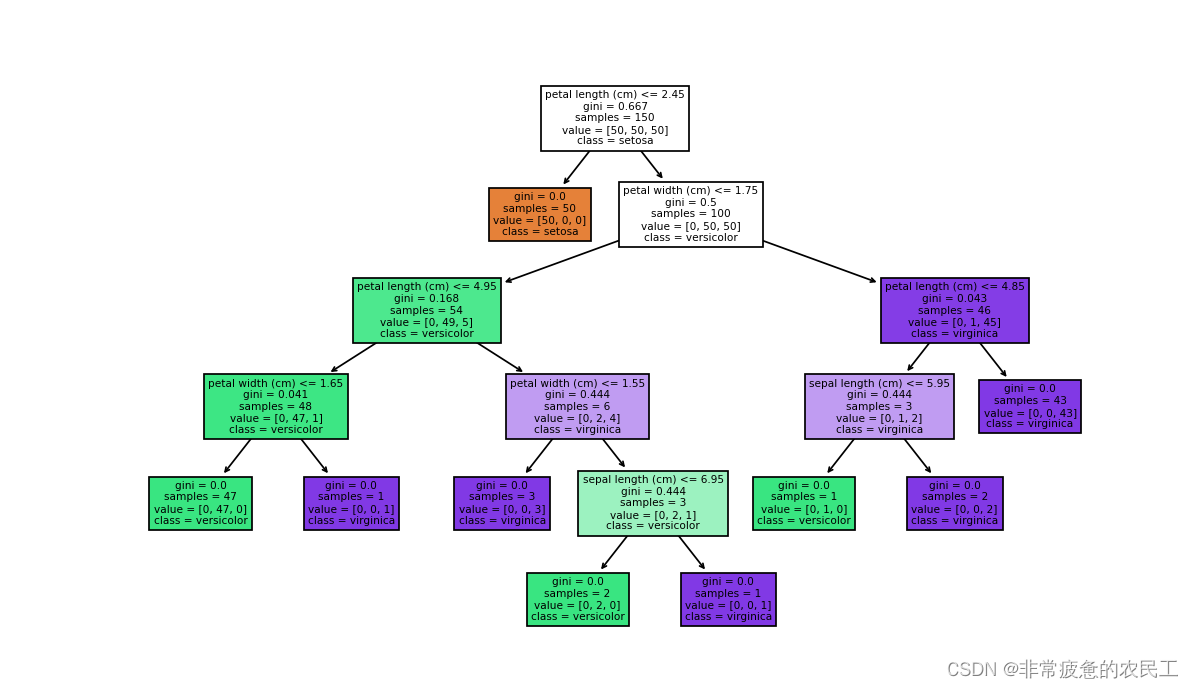
根据信息增益和基尼指数进行决策的决策树在分析运行结果上的异同之处主要体现在以下几个方面:
-
分裂标准不同:根据信息增益进行决策的决策树使用信息增益作为分裂标准,而根据基尼指数进行决策的决策树使用基尼指数作为分裂标准。
-
特征选择方式不同:根据信息增益进行决策的决策树会选择使得信息增益最大的特征进行分裂,而根据基尼指数进行决策的决策树会选择使得基尼指数最小的特征进行分裂。
-
处理连续值的方式不同:根据信息增益进行决策的决策树可以处理连续值,而根据基尼指数进行决策的决策树通常需要对连续值进行离散化处理。
-
树的形状可能不同:由于分裂标准和特征选择方式的不同,根据信息增益和基尼指数进行决策的决策树可能会生成不同的树形状。
-
对于数据不平衡的敏感度不同:根据信息增益进行决策的决策树对于数据不平衡较为敏感,而根据基尼指数进行决策的决策树对于数据不平衡相对较为鲁棒。

















 2879
2879

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









