









离线多卡部署视觉模型Qwen2.5-VL企业级服务方案
一、背景
公司网络是有严格限制,所有涉及境外服务器的网站都无法访问,包括docker等镜像源。本教程,是在提前下载或构建好资源,通过上传到服务器后,做离线部署。
二、参考环境
- 大模型服务发布工具:VLLM=0.7.2。
- 大模型版本:qwen2.5-vl-7b, 其他版本也可。
- python版本:python==3.12。
- 环境可选:docker 或直接python env。
- cuda版本为12.1,如果用docker无需考虑。
三、获取模型文件
途径很多,比如github、huggface、modelscope等,就不多说了。
国内建议:https://modelscope.cn/search?search=Qwen2.5-VL
四、部署流程
4.1 运行脚本qwen2_start.sh准备
这个脚本,不管是在什么环境部署都一样,主要关注的是VLLM版本。不同版本参数会有差异。
#!/bin/bash
echo "###########start vl by vllm...##########"
export GLOO_SOCKET_IFNAME="enp210s0f0"
export CUDA_VISIBLE_DEVICES="1,2"
export VLLM_LOGGING_LEVEL="DEBUG"
export VLLM_ATTENTION_BACKEND="FLASH_ATTN"
vllm serve /model/Qwen2.5-VL-7B-Instruct \
--gpu-memory-utilization 0.8 \
--dtype auto \
--host 0.0.0.0 \
--port 7860 \
--tensor-parallel-size 2 \
--kv-cache-dtype fp8 \
--max-model-len 10000 \
--limit-mm-per-prompt mage=4,video=1 \
--api-key yourkey \
脚本注释如下:
- GLOO_SOCKET_IFNAME=“enp210s0f0”:绑定网卡,大部分人不需要,企业可能会有多网卡导致发布失败。
- CUDA_VISIBLE_DEVICES=“1,2” : 指定用那几个显卡,特别要注意显卡间能不能通信。
- export VLLM_LOGGING_LEVEL=“DEBUG” :打开日志等级,稳定了就用INFO吧。
- export VLLM_ATTENTION_BACKEND=“FLASH_ATTN” :指定attention技术,一般都是用flash_attention2会节约点显存,默认会用xformers.
- gpu-memory-utilization 0.8 : 模型加载时gpu使用率,这个一定要注意别填太大,不然给缓存留的不够。
- /model/Qwen2.5-VL-7B-Instruct: 模型文件路径或联网下载的标准名称。
- host、port:没啥可说的,就是服务端口及IP;
- tensor-parallel-size:和上面指定显卡数目要匹配,就是用几张卡推理的意思。
- kv-cache-dtype:缓存精度。这个不设置也行,一般都是fp8的精度。
- limit-mm-per-prompt:这个是qwen自己的参数,每次输入的图片和视频限制。
- max-model-len :这个特别要注意,就是上下问token数,显存小就舍小一点,毕竟gpt3.5才设置的2048。一定要设置,因为默认的值贼大,一般会显存溢出。
- api-key:就是访问密码了。
4.2 常见无法运行的大坑1:显存不足
4.2.1 最常见的显存不足
我们用的7B的模型,理论上24G显存卡就够了,可是单卡或多卡依然报显存不足。核心原因是gpu_memory_utilization设置太大了,导致给kv缓存的不够预分配。所以要配合max_model_len一起设置,显存利用率设置低一些,那上下文长度就能大一些。
4.2.2 故障原因分析
-
显存不足的根本原因举例:
• 日志显示总GPU内存为23.50GiB,已使用率95%(约22.32GiB可用)。
• 模型权重占用15.63GiB,KV缓存预留5.95GiB,理论上总和为21.58GiB,但实际初始化时仍出现显存溢出。
• 可能原因:KV缓存预估不准确、图捕获(cudagraph)过程额外占用内存,或模型加载存在内存碎片。 -
关键错误日志:
ERROR 03-14 02:13:07 engine.py:389] CUDA error: out of memory RuntimeError: CUDA error: out of memory这表明在初始化KV缓存或捕获CUDA图时,显存分配失败。
4.2.3 解决方案
-
降低GPU内存利用率
修改启动参数,减少显存占用:--gpu_memory_utilization 0.8 # 从0.95降至0.8,释放更多显存 -
减少KV缓存大小
通过以下参数降低KV缓存需求:--max_num_seqs 128 # 减少并发序列数 --max_model_len 2048 # 减少模型上下文长度(需平衡性能与需求) -
关闭图捕获(Cudagraph)
在显存紧张时,禁用图捕获以降低内存占用:--enforce_eager=True # 强制启用Eager模式,禁用Cudagraph -
优化模型加载
确保模型路径正确且无损坏,尝试重新下载或加载模型:--download_dir /path/to/cache # 指定缓存目录,避免重复下载 -
调整批处理参数
降低单次请求的批处理大小:--max_batch_size 1 # 单次仅处理一个请求
4.3 常见无法运行的大坑:多卡加载卡住
-
确保模型没bug,模型搭配的py文件在处理张量逻辑时,也会卡bug。这个只能去找开源作者社区或关注更新。
-
NCCL通信卡住,直接超时或不动(最常见)。一般是显卡通信问题,使用以下命令查询显卡通信机制,以确认是否异常。一般来说可以尝试通过sys链接的两张卡测试看。
nvidia-smi topo -m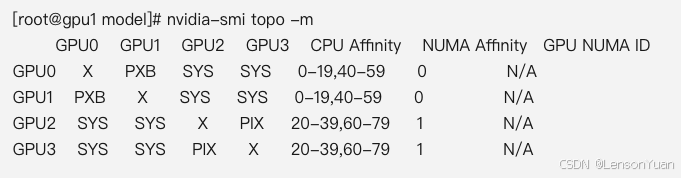
缩写 含义 典型场景 X自身(Self) GPU 内部环路 PXBPCIe x16 桥接(Direct PCIe Bridge) 同一 PCIe 树下的 GPU 直接互联 SYS系统总线(System Bus) 通过 CPU/主板 南桥间接连接 PIXPCIe 交换机(PCIe Switch) 多 GPU 通过 PCIe 交换机互联 -
模型是多模态,可能不支持奇数或偶数颗显卡。比如qwen2.5-vl-7b,就只支持偶数张卡。
4.4 运行环境准备
4.4.1 基于docker运行(推荐)
基于docker的话,里面都装好了各种底层和上程环境,我们只需要在宿主机上装好显卡驱动就行,一般版本是535+会比较合适。
4.4.1.1 获取官方镜像
拉取官方镜像,官方镜像只在hub.docker.com上(国内无法访问),目前基本国内镜像源都被封禁或关闭了,即使有遇到可以用的镜像源,一样不可能是最新版本,会存在各种问题。
以下是我的版本(digest:d082165a6bc5):
docker pull qwenllm/qwenvl:2.5-cu121
4.X【官方镜像压缩包下载】
本人已通过设法拉取了该镜像,当前通过docker打包成了tar文件,可直接下载后,通过docker命令导入。 下载的文件名为:qwenvl25_cu121_20250312.tar,导入方案如下:
# 用docker把tar导入到镜像
docker load -i ./qwenvl25_cu121_20250312.tar
# 查看是否导入成功,导入后是这个哈:qwenllm/qwenvl:2.5-cu121
docker images | grep qwen
【下载有问题可以优快云私信本人,工作日回复】
【按此方案的,可直接参考第5节简约全流程更直观】
- 千问官方镜像,里面不带模型文件哈,支持任意Qwen2.5-vl的模型,理论上也支持其他模型。
- 直白点就是环境安装情况决定能运行什么代码,想在该环境下的代码,直接在我的启动脚本(qwen2_start.sh)里改就行。此处列出该镜像环境情况供参考:
root@gpu2:/data/shared/Qwen# pip list Package Version --------------------------------- --------------------- accelerate 1.3.0 aiofiles 23.2.1 aiohappyeyeballs 2.4.4 aiohttp 3.11.12 aiohttp-cors 0.7.0 aiosignal 1.3.2 airportsdata 20241001 annotated-types 0.7.0 anyio 4.8.0 astor 0.8.1 async-timeout 5.0.1 attrs 25.1.0 av 14.1.0 blake3 1.0.4 blinker 1.4 cachetools 5.5.1 certifi 2025.1.31 charset-normalizer 3.4.1 click 8.1.8 cloudpickle 3.1.1 colorful 0.5.6 compressed-tensors 0.9.1 cryptography 3.4.8 dbus-python 1.2.18 depyf 0.18.0 dill 0.3.9 diskcache 5.6.3 distlib 0.3.9 distro 1.7.0 einops 0.8.0 exceptiongroup 1.2.2 fastapi 0.115.8 ffmpy 0.5.0 filelock 3.17.0 flash-attn 2.7.2.post1 frozenlist 1.5.0 fsspec 2024.6.1 gguf 0.10.0 google-api-core 2.24.1 google-auth 2.38.0 googleapis-common-protos 1.66.0 gradio 5.4.0 gradio_client 1.4.2 grpcio 1.70.0 h11 0.14.0 httpcore 1.0.7 httplib2 0.20.2 httptools 0.6.4 httpx 0.28.1 huggingface-hub 0.28.1 idna 3.10 importlib-metadata 4.6.4 iniconfig 2.0.0 interegular 0.3.3 jeepney 0.7.1 Jinja2 3.1.4 jiter 0.8.2 jsonschema 4.23.0 jsonschema-specifications 2024.10.1 keyring 23.5.0 lark 1.2.2 launchpadlib 1.10.16 lazr.restfulclient 0.14.4 lazr.uri 1.0.6 lm-format-enforcer 0.10.9 markdown-it-py 3.0.0 MarkupSafe 2.1.5 mdurl 0.1.2 mistral_common 1.5.2 more-itertools 8.10.0 mpmath 1.3.0 msgpack 1.1.0 msgspec 0.19.0 multidict 6.1.0 nest-asyncio 1.6.0 networkx 3.1 numpy 1.26.4 nvidia-cublas-cu12 12.1.3.1 nvidia-cuda-cupti-cu12 12.1.105 nvidia-cuda-nvrtc-cu12 12.1.105 nvidia-cuda-runtime-cu12 12.1.105 nvidia-cudnn-cu12 9.1.0.70 nvidia-cufft-cu12 11.0.2.54 nvidia-curand-cu12 10.3.2.106 nvidia-cusolver-cu12 11.4.5.107 nvidia-cusparse-cu12 12.1.0.106 nvidia-ml-py 12.570.86 nvidia-nccl-cu12 2.21.5 nvidia-nvjitlink-cu12 12.1.105 nvidia-nvtx-cu12 12.1.105 oauthlib 3.2.0 openai 1.61.1 opencensus 0.11.4 opencensus-context 0.1.3 opencv-python-headless 4.11.0.86 orjson 3.10.15 outlines 0.1.11 outlines_core 0.1.26 packaging 24.2 pandas 2.2.3 partial-json-parser 0.2.1.1.post5 pillow 10.4.0 pip 22.0.2 platformdirs 4.3.6 pluggy 1.5.0 prometheus_client 0.21.1 prometheus-fastapi-instrumentator 7.0.2 propcache 0.2.1 proto-plus 1.26.0 protobuf 5.29.3 psutil 6.1.1 py-cpuinfo 9.0.0 py-spy 0.4.0 pyasn1 0.6.1 pyasn1_modules 0.4.1 pybind11 2.13.6 pycountry 24.6.1 pydantic 2.10.6 pydantic_core 2.27.2 pydub 0.25.1 Pygments 2.19.1 PyGObject 3.42.1 PyJWT 2.3.0 pyparsing 2.4.7 pytest 8.3.4 python-apt 2.4.0+ubuntu4 python-dateutil 2.9.0.post0 python-dotenv 1.0.1 python-multipart 0.0.12 pytz 2025.1 PyYAML 6.0.2 pyzmq 26.2.1 qwen-vl-utils 0.0.10 ray 2.42.0 referencing 0.36.2 regex 2024.11.6 requests 2.32.3 rich 13.9.4 rpds-py 0.22.3 rsa 4.9 ruff 0.9.5 safehttpx 0.1.6 safetensors 0.5.2 SecretStorage 3.3.1 semantic-version 2.10.0 sentencepiece 0.2.0 setuptools 59.6.0 setuptools-scm 8.1.0 shellingham 1.5.4 six 1.16.0 smart-open 7.1.0 sniffio 1.3.1 starlette 0.45.3 sympy 1.13.1 tiktoken 0.7.0 tokenizers 0.21.0 tomli 2.2.1 tomlkit 0.12.0 torch 2.5.1+cu121 torchaudio 2.5.1+cu121 torchvision 0.20.1+cu121 tqdm 4.67.1 transformers 4.49.0.dev0 transformers-stream-generator 0.0.4 triton 3.1.0 typer 0.15.1 typing_extensions 4.12.2 tzdata 2025.1 urllib3 2.3.0 uvicorn 0.34.0 uvloop 0.21.0 virtualenv 20.29.1 vllm 0.7.2.dev56+gbf3b79ef wadllib 1.3.6 watchfiles 1.0.4 websockets 12.0 wheel 0.37.1 wrapt 1.17.2 xformers 0.0.28.post3 xgrammar 0.1.11 yarl 1.18.3 zipp 1.0.0
4.4.1.2 运行镜像容器脚本
# 假设宿主机模型路径为/data/model/Qwen2.5-VL-7B-Instruct
# 假设宿主机启动脚本路径为:/data/model/qwen2_start.sh
# 83e0e4ecdfa2 这个是我的imageId哈,建议用镜像名qwenllm/qwenvl:2.5-cu121,就是docker image查到的。
# 启动命令, -v就是文件夹映射,端口自己改就行,要和启动脚本上的对应。
docker run -d -p 7860:7860 --gpus all \
--privileged \
--cpus="40" \
--memory="100g" \
-v /data/model/:/model \
--ipc=host \
--network=host \
--name qwen2.5 \
wenllm/qwenvl:2.5-cu121 \
bash -c "/model/qwen2_start.sh"
运行成功的日志如下(docker logs qwen2.5):
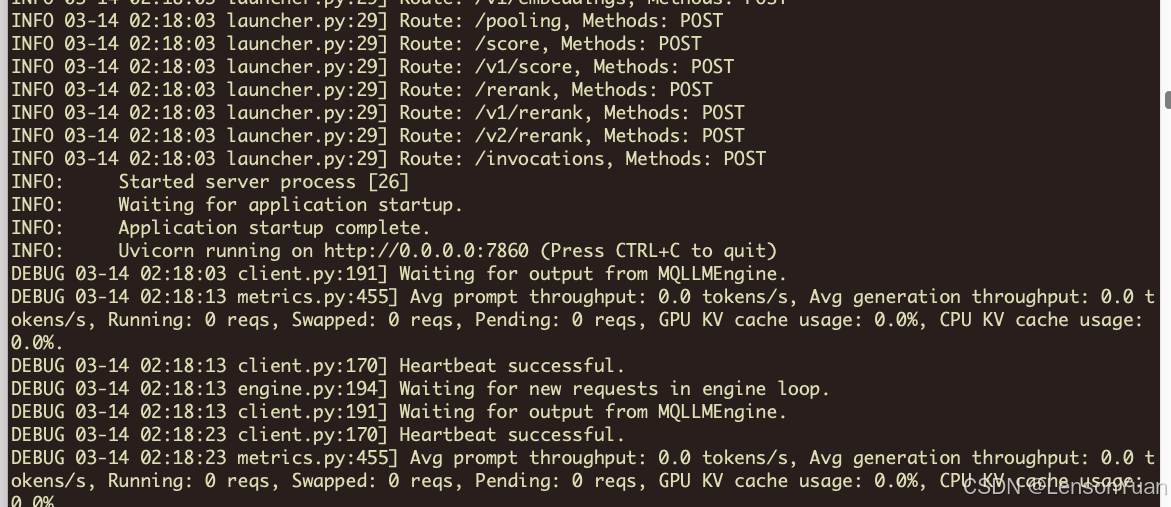
4.4.2 基于python环境运行
【python环境安装依赖多的包,如何避免错误后直接失败,请参考本人博客关于python环境包多依赖易失败的安装方案。】
重点是装python环境,不建议离线,因为依赖底层很麻烦。如果env要离线拷贝,也得相同cuda、内核、cpu、系统版本、GCC版本完全一致,才能拷贝打包到服务器后,能生效。
联网安装python环境步骤如下:
- 准备python版本,conda install -n myenv python==3.12。
- 装VLLM指定版本,一般会报错。建议先装壳,再装依赖,不然失败就是重来。
- torch系依赖的包无法安装的话,可以手动下载whl文件,安装完成后再装torch,如下依赖,大概率报错:xgrammar=0.1.11 失败, xformers=0.0.28.post3 失败,torchvision=0.20.1 失败。
准备好环境后,直接运行qwen2.5_start.sh即可。
# 激活对应环境后。
chmod +x ./qwen2.5_start.sh
bash ./qwen2.5_start.sh
4.4 调用测试
直接用python或类似大模型工具,填写请求即可,openai风格是V1,代码示例如下:
from openai import OpenAI
client = OpenAI(
base_url="http://192.168.111.23:7860/v1",
api_key="token-abc123",
)
model_type = client.models.list().data[0].id
print(f'model_type: {model_type}')
5. 特别补充说明(镜像包运行方式小白教程)
鉴于很开发者技术水平有限,下载环境后无法看出一些基础设置的调整,下面将“基于下载我提供的镜像服务”提供更细节的说明。
5.1 下载docker环境镜像并导入到服务器
- 第一步:下载的打包镜像名称为docker_qwenvl25_cu121_20250312.tar;该镜像包为platform=linux/amd64,不是arm64。因此,您的服务器CPU应该是X86架构才行。
- 第二步:进入到下载文件位置,用docker把tar包导入到images。如果成功,第二条命令会显示对应镜像包名。
#用docker把tar导入到镜像 docker load -i ./qwenvl25_cu121_20250312.tar # 查看是否导入成功,导入后是这个哈:qwenllm/qwenvl:2.5-cu121 docker images | grep qwen - 验证images是否可以正常运行在服务器。
执行下面的命令,看是否能正常新建容器并进入容器内bash,正常使用的话,退出即可(临时容器会自动删除)。docker run --gpus all --rm --name qwentest -it qwenllm/qwenvl:2.5-cu121 bash
5.2 下载qwen2.5-VL模型文件与编辑运行脚本
- 上节基本已经拥有了image,相当于环境已有。那要运行那个VL模型呢,去modelscope上下载吧。(不会用LFS或代码下载,就用迅雷一个个点击下载)。假设下载的文件夹为Qwen2.5-VL-7B-Instruct,放在了/data/model/路径下。
- 接下来,我们要准备运行VLM的脚本,即qwen2_start.sh。这个文件其实就是容器内执行代码的脚本,要加什么运行内容,都可以在这设置。
内容可以优化如下,* 新建一个qwen2_start.sh,把内容复制进去,win用户注意编码要是utf8) *:
特别注意:里面内容根据情况修改,比如显卡用哪几张、多网卡服务去需要绑定网卡、api-key应该设置成什么。#!/bin/bash echo "###########start vl by vllm...##########" # export GLOO_SOCKET_IFNAME="enp210s0f0" export CUDA_VISIBLE_DEVICES="1,2" export VLLM_LOGGING_LEVEL="DEBUG" export VLLM_ATTENTION_BACKEND="FLASH_ATTN" vllm serve /model/Qwen2.5-VL-7B-Instruct \ --gpu-memory-utilization 0.8 \ --dtype auto \ --host 0.0.0.0 \ --port 7860 \ --tensor-parallel-size 2 \ --kv-cache-dtype fp8 \ --max-model-len 10000 \ --limit-mm-per-prompt mage=4,video=1 \ --api-key token-abc123 \
tensor-parallel-size的值和你的CUDA_VISIBLE_DEVICES设置数量是一致的,qwen2-vl的模型必须偶数,如果是单卡运行,请去掉 tensor-parallel-size。
3. qwen2_start.sh放到服务器后,需要授予执行权限:chmod +x ./qwen2_start.sh
5.3 运行下载的容器服务并调用脚本
-
注意docker容器启动脚本情况:
端口是7860映射,要换其他端口,改前面那个数字(宿主机);
服务器 /data/model/映射到了容器内/model下,我们上一步的模型文件和脚本都在宿主机的 /data/model/下,也即在容器/model下,所以最底下执行的脚本路径如下:bash -c “/model/qwen2_start.sh”。# 假设宿主机模型路径为/data/model/Qwen2.5-VL-7B-Instruct # 假设宿主机启动脚本路径为:/data/model/qwen2_start.sh # 83e0e4ecdfa2 这个是我的imageId哈,建议用镜像名qwenllm/qwenvl:2.5-cu121,就是docker image查到的。 # 启动命令, -v就是文件夹映射,端口自己改就行,要和启动脚本上的对应。 docker run -d -p 7860:7860 --gpus all \ --privileged \ -v /data/model/:/model \ --name qwen2.5 \ qwenllm/qwenvl:2.5-cu121 \ bash -c "/model/qwen2_start.sh" -
启动后,我们查看docker执行日志看是否报错:docker logs --tail 100 qwen2.5
-
有报错的话,就检查下文件是否有问题,再看是否要修改qwen2_start.sh,搞好后重新docker restart进行排查。
如果报错和docker run 有关,那就删除容器,修改启动命令再重建容器。



















 7091
7091

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











