







少样本图像分类(FewShot):CAML算法代码的实现与教学(二)【附代码下载】
一、引言
上一篇文章《少样本图像分类(FewShot):CAML算法代码的实现与教学(一)》中,已介绍了FewShot的基础概念、CAML算法的核心逻辑、代码讲解与问题。
本篇文章将针对源码进行实现与改进,实现推理部分和离线模型加载部分。
二、核心改进点
- 实现输入单张图片进行推理,输出类别和概率。
- 模型下载通过本地文件进行加载。
- 不再随机抽样,启动时加载指定的支持集,运行时输入一张图片作为查询集。
- 可任意指定支持集的位置、任意指定模型所在的位置。
- 样本特征编码部分和逻辑修改,源码bug修改。
三、相关工作
3.1 项目路径问题
项目使用的是pypyprojroot包进行项目路径管理的,但运行时无法定位根目录。
解决办法:根目录新建文件pyproject.toml,保证返回正确的根目录。
3.2 主要逻辑实现。
根目录新建caml_infer.py文件,实现代码逻辑。代码如下:
【注:其中meta_infer()方法的依赖,在推理讲解的部分中】
# -*- encoding: utf-8 -*-
"""
@File : caml_infer.py
@Description : None
@Author : 一只特立独行的羱
@Contact : 未知
@License : (C)Copyright 2019-2030,xx
@Modify Time @Version
------------ --------
2024/12/17 11:19 1.0
"""
import torch
import timm
from common.tools import project_path
from src.models.CAML import CAML
import torchvision.datasets as datasets
from PIL import Image
from src.evaluation.datasets import transform_manager
class CamlInfer(object):
def __init__(self, device="cuda:3", caml_model_path='caml_pretrained_models/CAML_CLIP/model.pth'):
# init
self.support_labels = None
self.support_inputs = None
self.way = None
self.shot = None
# 基础参数
self.device = device
self.caml_model_path = project_path(caml_model_path)
timm_feature_model_name, dim = "vit_base_patch16_clip_224", 768
timm_feature_model_path = project_path("CAML/timm/vit/open_clip_pytorch_model.bin")
self.feature_extractor = timm.create_model(timm_feature_model_name,
pretrained=True,
pretrained_cfg_overlay=dict(file=timm_feature_model_path),
img_size=224,
num_classes=0).eval()
# 提取timm模型的变换器
data_config = timm.data.resolve_model_data_config(self.feature_extractor)
self.transforms = timm.data.create_transform(**data_config, is_training=False)
# 加载CAML模型
self.model = CAML(feature_extractor=self.feature_extractor,
fe_dim= dim,
fe_dtype= torch.float32,
train_fe= False,
encoder_size='large',
device= self.device,
label_elmes= True,
dropout= 0.0)
# Get the model and load its weights.
self.model.load_state_dict(torch.load(self.caml_model_path, map_location=self.device), strict=False)
self.model.to(torch.device(self.device))
self.model.eval()
def load_support_set(self, support_path='camldatasets/Aircraft_fewshot', way=5, shot=7):
"""
param path: Aircraft的格式支持集
param way:
"""
self.way = way
self.shot = shot
# 数据集 way*shot
data_path = project_path(support_path)
dataset = datasets.ImageFolder(data_path, loader=lambda x: image_loader(path=x, is_training=False, transform_type=self.transforms, pre=False))
# batch_size=None#一次性返回整个数据集; shuffle=None# 不需要随机打乱数据
infer_loader = torch.utils.data.DataLoader(dataset, batch_size=len(dataset), shuffle=None, num_workers=3, pin_memory=False)
# 一次性获取support支持集合
self.support_inputs, self.support_labels = next(iter(infer_loader))
self.support_inputs= self.support_inputs.to(self.model.device)
def infer(self, path):
image_tensor = image_loader(path=path, is_training=False, transform_type=self.transforms, pre=False)
query = image_tensor.unsqueeze(0)
query = query.to(self.model.device)
with torch.no_grad():
max_index, probabilities = self.model.meta_infer(self.support_inputs, support_labels=self.support_labels, query_tensor=query)
tensor_rounded = torch.round(probabilities * 100) / 100
print(f'{self.way}-way-{self.shot}-shot acc: {tensor_rounded} - category: {max_index}')
if __name__ == '__main__':
ci = CamlInfer(caml_model_path='CAML/caml_pretrained_models/CAML_CLIP/model.pth')
# 加载默认支持集
ci.load_support_set(support_path='CAML/caml_universal_eval_datasets/Aircraft_fewshot')
test_pic = project_path( "CAML/caml_universal_eval_datasets/test/蓝猫.jpg")
ci.infer(path=test_pic)
3.3 代码讲解:模型初始化
- caml_model_path: 就是我们训练好的CAML算法参数文件,源文件要在Google网盘下载。文件太大,后期看关注量决定是否上传到国内。
- CAML/timm/vit_base_patch16_clip_224.openai/open_clip_pytorch_model.bin,这个是timm库里模型文件所在本地位置。
CamlInfer类初始化时,会声明一些基础变量。重点是加载timm库的模型文件作为图像特征编码器,模型文件选择的问题具体介绍看上一篇文章。
self.feature_extractor = timm.create_model(timm_feature_model_name,
pretrained=True,
pretrained_cfg_overlay=dict(file=timm_feature_model_path),
img_size=224,
num_classes=0).eval()
这部分加载模型代码,就是离线加载。在pretrained_cfg_overlay里面指定了timm加载时从哪里找模型文件。而timm_feature_model_name是timm内置的模型列表里的,所以不能随意填写,要和本地文件对应。
# 提取timm模型的变换器
data_config = timm.data.resolve_model_data_config(self.feature_extractor)
self.transforms = timm.data.create_transform(**data_config, is_training=False)
这部分就是从加载的特征提取器里面,提取图像变换部分,塞入到transforms,便于对输入图片进行处理。
# 加载CAML模型
self.model = CAML(feature_extractor=self.feature_extractor,
fe_dim= dim,
fe_dtype= torch.float32,
train_fe= False,
encoder_size='large',
device= self.device,
label_elmes= True,
dropout= 0.0)
# Get the model and load its weights.
self.model.load_state_dict(torch.load(self.caml_model_path, map_location=self.device), strict=False)
首先,加载CAML的模型框架,包括特征提取器。第二步,就是往模型里面灌入模型权重。
self.model.to(torch.device(self.device))
self.model.eval()
把加载的模型和参数,放到显卡内存里,并启动torch.eval评估模式。
3.4 代码讲解:支持集Support Set加载
CAML模型、CLIP特征编码器等都已初始化加载,接下来,需要对支持集(support set)进行加载。方法为CamlInfer.load_support_set().
def load_support_set(self, support_path='caml_universal_eval_datasets/Aircraft_fewshot', way=5, shot=7):
"""
param path: Aircraft的格式支持集
param way: 不可以超过5,训练好的模型只支持<=5的少样本
"""
self.way = way
self.shot = shot
# 数据集 way*shot
data_path = project_path(support_path)
dataset = datasets.ImageFolder(data_path, loader=lambda x: image_loader(path=x, is_training=False, transform_type=self.transforms, pre=False))
# batch_size=None#一次性返回整个数据集; shuffle=None# 不需要随机打乱数据
infer_loader = torch.utils.data.DataLoader(dataset, batch_size=len(dataset), shuffle=None, num_workers=3, pin_memory=False)
# 一次性获取support支持集合
self.support_inputs, self.support_labels = next(iter(infer_loader))
self.support_inputs= self.support_inputs.to(self.model.device)
- support_path: 这个路径就是我们的支持集所在位置,格式是Aircraft数据集的格式。其实不用在乎格式,因为我已经做了改进。输入的支持集就是在路径下,按类别文件夹存放即可。如下示例,狗猪猫就是我的class, 每个类别下4张图。也就是3way-4shot:
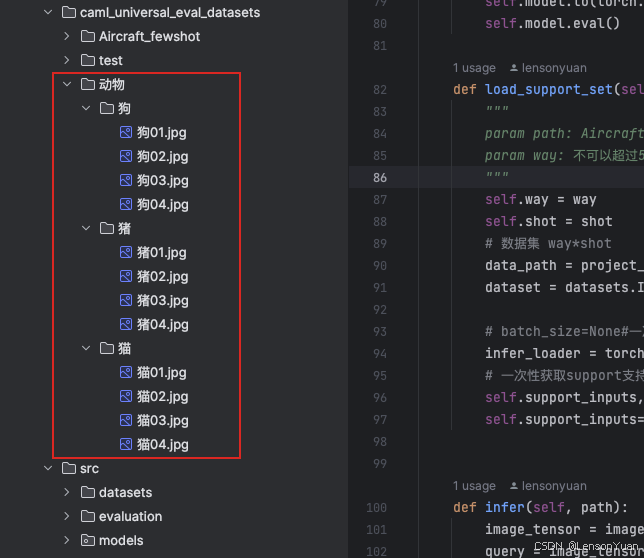
- datasets.ImageFolder(),就是对图片进行RGB三通道读取,并按transform进行图片变换后返回。
- infer_loader, 因为fewshot数据不多,借助torch的DataLoader直接一次加载到内存,不需要迭代器。这个就是我们入模的张量self.support_inputs, 张量对应的类别编号就是self.support_labels.
3.5 代码讲解:推理过程
def infer(self, path):
image_tensor = image_loader(path=path, is_training=False, transform_type=self.transforms, pre=False)
query = image_tensor.unsqueeze(0)
query = query.to(self.model.device)
with torch.no_grad():
max_index, probabilities = self.model.meta_infer(self.support_inputs, support_labels=self.support_labels, query_tensor=query)
tensor_rounded = torch.round(probabilities * 100) / 100
print(f'{self.way}-way-{self.shot}-shot acc: {tensor_rounded} - category: {max_index}')
- 输入的path就是待推理的本地图片,一样的,需要做相同的图片预处理和特征编码,得到image_tensor.
- 支持集shap就是Tensor(63, 3, 224, 224), 其中,63就是样本数、3是RGB通道数、224是图片的像素加载。因为要一一对应,那查询集应该要格式为Tensor(1, 3, 224, 224),所以才query = image_tensor.unsqueeze(0),在一维处展开。
- self.model.meta_infer() ,这个就是推理部分啦。代码放在了CAML.py文件中,在类CAML新增方法meta_infer(),代码如下:
def meta_infer(self, inp, support_labels, query_tensor):
"""For evaluating typical Meta-Learning Datasets."""
# 提取特征向量(假设 inp 是 support set)
support_features = self.get_feature_vector(inp) # 划分 support set
query_features = self.get_feature_vector(query_tensor) # 划分query set
# Reshape query and support to a sequence.
support = support_features.unsqueeze(0)
query = query_features.unsqueeze(0)
feature_sequences = torch.cat([query, support], dim=1) # 拼接两个特征,变成上下文。
# 输入上下文, 使用 Transformer 编码器进行推理
logits = self.transformer_encoder.forward_imagenet_v2(feature_sequences, support_labels, way=None, shot=None)
# 添加 softmax 操作,输出概率分布
probabilities = torch.softmax(logits, dim=1)
_, max_index = torch.max(logits, 1)
# 返回概率分布和预测结果
return max_index, probabilities
这部分代码我就不过多讲了,在上一篇文章已经提过了,大概就是把支持集和查询集进行上下文拼接,之后用模型进行推理,得出类别概率。
本人实验代码下载
【资源下载点此处】:https://download.youkuaiyun.com/download/A15216110998/90592653
此资源为源码包,是本人在攻克小样本学习问题上,花了一个月进行改进与分析后的代码,安装环境后,可以直接运行caml_infer_main.py。
截图如下:运行caml_infer_main.py即可。
环境是python3.7,两个模型文件在对应的.txt中有说明,下载替换即可。
四 、结语
本人通信工程专业,研究生长期从事传感器网络数据算法的研究。在人工智能,尤其是数据挖掘、NLP、CV等领域深耕10多年,欢迎关注Star,遇见更多实践好文。
关于CAML算法的改进与推理实现,是本人投入个把月进行完成的,包括在源代码理解上咨询原作者、不断调试试验等。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











