







时间序列预测及预测方法汇报
目录
一、时间序列预测
二、相关方法
三、实际案例
四、总结展望
一、时间序列预测
1. 背景研究
- 概念
时间序列预测:时间序列预测就是利用过去一段时间内某事件的序列特征来预测未来一段时间内该事件序列目标值。 - 和回归的区别:
这是一类相对比较复杂的预测建模问题,和回归分析模型的预测不同,时间序列模型是依赖于事件发生的先后顺序的,同样大小的值改变顺序后输入模型产生的结果是不同的。 - 类别
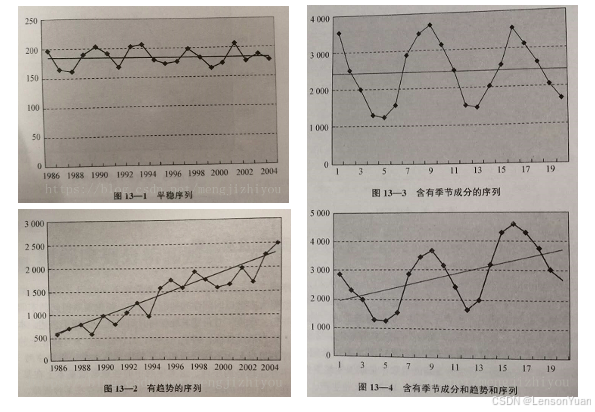
时间序列可以分为平稳序列,即不存在某种趋势、季节性的方差和均值不随时间变化的序列,以及非平稳序列。
2. 数据示例
-
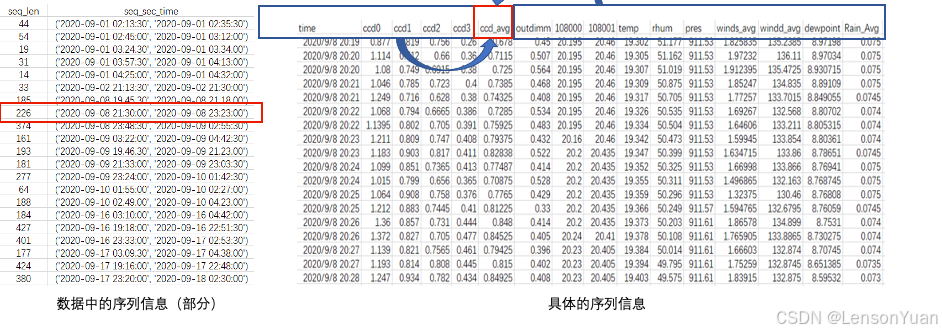
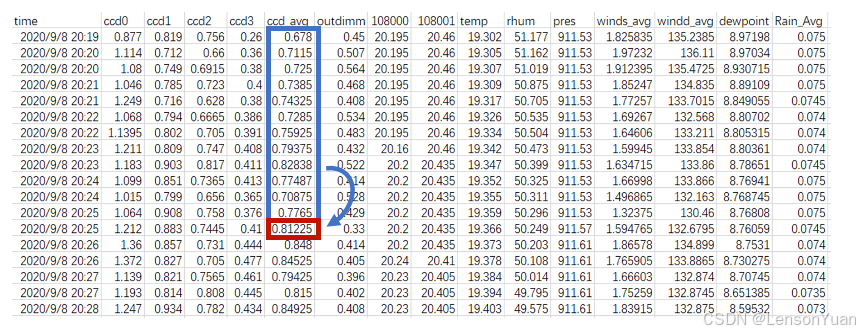
现有数据
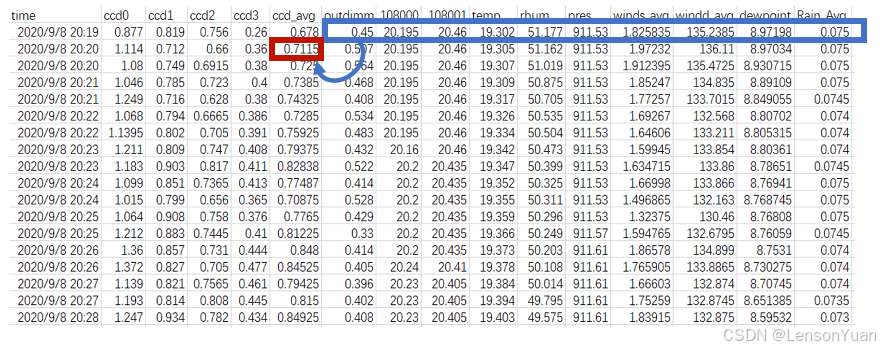
主要数据:时间、观测值、目标观测值、传感器特征和天气特征
数据示例:
-
我们以一个银行贷款的申请流程为示例。假如这是一个正在执行的流程,并且已经执行到了银行审查申请阶段。
对于这个正在执行中的业务流程实例,如果能够准确的预估其剩余执行时间,那么对于银行或者申请人来说都有一定的意义。比如对于银行来说,可以采取更为有效的资源调度等执行策略,以提升业务系统的整体性能。由此可见,剩余时间预测是业务流程性能优化的重要手段。
二、相关方法
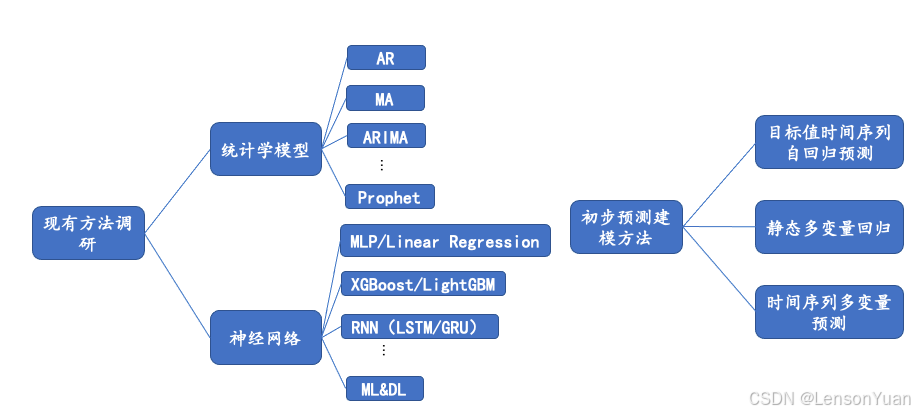
1. 时间序列预测方法
统计学方法:基本要求是平稳,处理平稳序列,一般针对均值的单序列拟合预测
AR模型称为自回归模型(Auto Regressive model);MA模型称为移动平均模型(Moving Average model);ARMA称为自回归移动平均模型(Auto Regressive and Moving Average model);ARIMA模型称为差分自回归移动平均模型。
深度神经网络:RNN,CNN,以及他们和机器学习算法的组合模型。
2. 自回归
2.1 时间序列自回归
基于Prophet/ARIMA时间序列预测概念
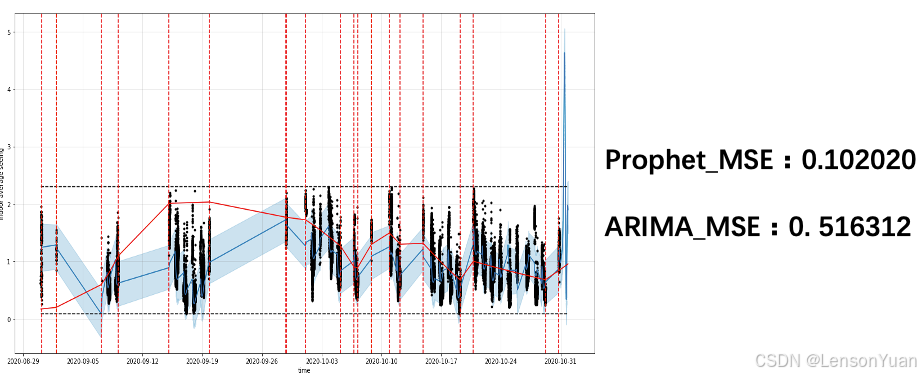
2.2 基于Prophet的时间序列预测
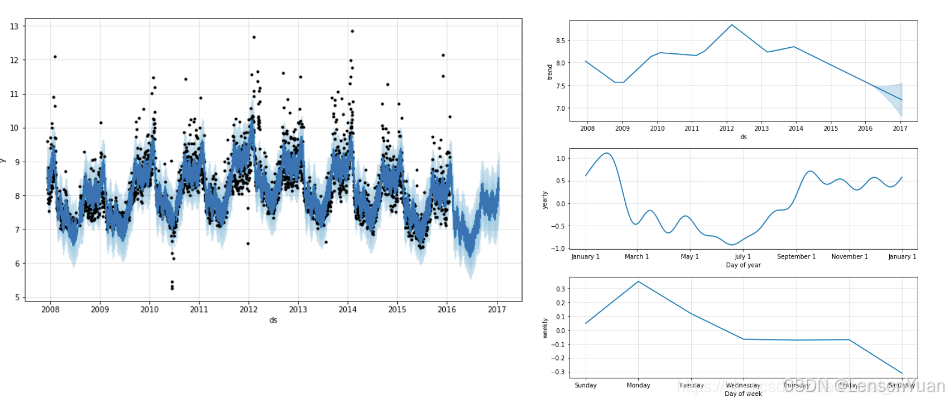
-
趋势特征是序列本身的趋势,周期特征,可以通过调节周期参数具体到年月日,有时也会收到节假日影响,比如黑色星期五、世界杯、NBA总决赛。此外还有突变点特征,我理解为噪声点,模型将不会将这些突变点信息学习进去
-
建模的过程,要求两列数据,ds就是日期,日期(YYYY-MM-DD)或者是具体的时间点(YYYY-MM-DD HH:MM:SS),y 列必须是数值变量,表示我们希望去预测的量。
-
接下来训练就是定义模型、喂给模型数据
-
预测之前定义forecast来决定预测数据的时间窗口,即多久的数据
最后得到预测数据之后,对于数据进行分析、可视化
2.3 时间序列预测-ARIMA
- 基于ARIMA的时间序列预测
1、ARIMA(p,d,q) :
(1)AR:利用目标观测值Y_𝑡与之前观测值之间的关系来预测目标观测值Y_𝑡 (观测值的线性组合+当前随机误差)。
Y_𝑡= 𝜑_1 𝑌_(𝑡−1)+𝜑_2 𝑌_(𝑡−2)+…+𝜑_𝑝 𝑌_(𝑡−𝑝)+𝑒_𝑡
(2)MA:利用目标观测值Y_𝑡与之前测试误差的关系来预测目标观测值Y_𝑡(随机误差线性组合+当前随机误差)。
Y_𝑡= 𝜀_1 𝑒_1+𝜀_2 𝑒_(𝑡−2)+…+𝜀_𝑝 𝑒_(𝑡−𝑝)+𝑒_𝑡
(3)I:当前观测值与之前观测值,作差。
2、建模步骤:
(1)序列平稳化(差分):确定差分阶数d。
(2)利用ACF、PACF图来识别阶数:确定AR的阶数p,MA的阶数q。
(3)模型诊断:看残差序列的自相关图来鉴别模型的预测误差是否为白噪声序列。是,则模型正确;否,则错误。 - 说明
使用ARMA模型进行预测时候,要求时间序列必须是平稳的,即事件序列中没有趋势、季节、循环成分,其观测值的平均数不随着时间的变化而变化。而现实中许多序列都是非平稳的,经过差分之后就可以消除非平稳性(趋势、季节因素),差分(difference)即当前观察值减去前面的观察值。平稳化之后,就可以使用ARMA进行预测了。
阶数确定的方法,观察时间序列的自相关图和偏自相关图。
AR阶数的确定:自相关图指数衰减或者正弦衰减到0(拖尾),偏自相关图在置信区间内有p个明显的峰值(截尾),则阶数为p
MA阶数的确定过程,同AR。
白噪声序列的特点表现在任何两个时点的随机变量都不相关,序列中没有任何可以利用的动态规律,因此不能用历史数据对未来进行预测和推断。
3. 时间序列预测-静态多变量回归
静态多变量回归:为什么称之为静态呢,就只是训练出一个回归器,喂进去X,出来y,没有用到y本身的历史数据。
3.1 时间序列多变量预测——基于GRU/LSTM
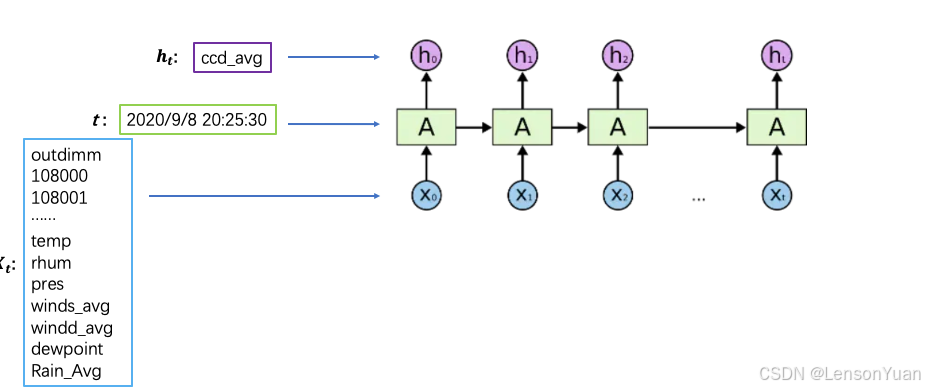
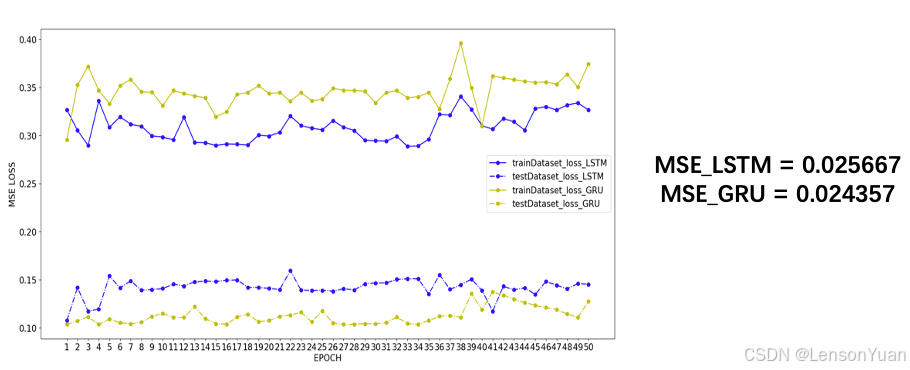
3.2 时间序列多变量预测——DL&ML

4 预测方法总结
三、实际案例
3.1 时间序列预测-辽宁省感染性腹泻发病预测
3.1.1 背景
-
我国其他感染性腹泻年发病数约为130万例,年发病率约为95.0/10万,发病率位于我国法定丙类传染病报告前3位。
-
预测模型在传染病预测中得到广泛应用,如灰色模型、指数曲线模型以及ARIMA模型。
-
ARIMA模型是时间序列预测领域的经典模型,应用广泛,综合考虑了序列的趋势变化、周期变化及随机干扰,是一种实用性强、精确度较高的短期预测方法。
-
使用方便,可以借助软件或者程序接口,方便修改、调参。
3.1.2 需求透视
输入:2007年1月至2017年12月国家人口与健康科学数据中心健康及发病率等维度数据。
输出:构建预测模型,有效预测辽宁省其它感染性腹泻发病率和挖掘发病规律,为发病高峰的防控工作和医疗资源的配置提供科学依据。
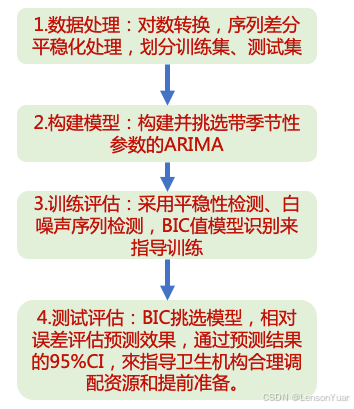
3.1.3 解决方案
1.数据处理:对数转换,序列差分平稳化处理,划分训练集、测试集
2.构建模型:构建并挑选带季节性参数的ARIMA
3.训练评估:采用平稳性检测、白噪声序列检测,BIC值模型识别来指导训练
4.测试评估:BIC挑选模型,相对误差评估预测效果,通过预测结果的95%CI,來指导卫生机构合理调配资源和提前准备。
说明
- 用到了一阶差分和一阶季节差分
- 模型选择问题在模型复杂度与模型对数据集描述能力(即似然函数)之间寻求最佳平衡。
- 模型选择方法BIC,贝叶斯信息准则,bic = kln(n)-2ln(L),k为模型参数个数,模型越复杂,k越大;n为样本数量;L为似然函数。k*ln(n)惩罚项在维度过大且训练样本数据相对较少的时候,可以有效避免维度灾难。
应用价值
3.2 时间序列预测-鄂尔多斯某煤矿井下工作面矿压预测
略略略~
四、总结展望
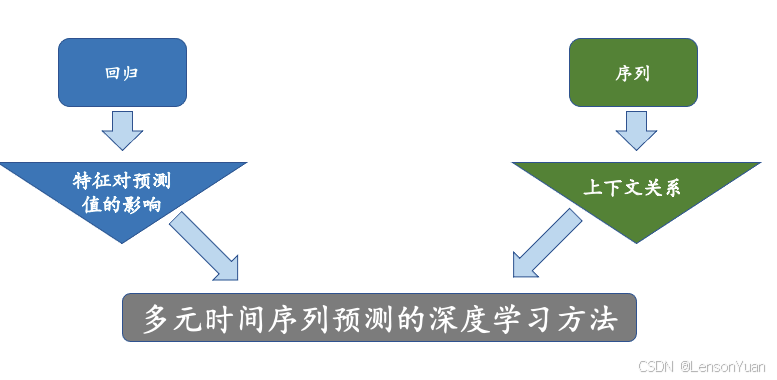
- 总结
对时间序列进行预测任务进行了当前主要方法的调研,包括传统的时间序列预测方法(ARIMA、Prophet),机器学习方法(MLP、XGBoost、LightGBM),深度学习方法(LSTM、GRU、RNN&XGBoost),发现同时考虑目标值历史信息和序列特征信息的组合模型,可以更好的预测目标值。 - 下一步工作
继续着手项目组现有数据进行实验,调参,评估,寻找最优实验结果。
继续查阅最新的关于多变量时间序列预测任务的论文,学习最新的预测方法,对公司当前业务场景下的模型进行优化调整。
今天的分享就到这里,本文根据本人技术分享ppt进行的撰写的。ppt原版请转到个人空间下载。【点击此处下载】



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











