







今天,DeepSeek开源周的第三弹——DeepGEMM正式亮相!这个看似名字拗口的工具,其实是一个专为AI计算设计的“数学加速器”。简单来说,它能让AI模型的训练和推理(比如生成一段文字或一张图)速度更快,同时更省电。

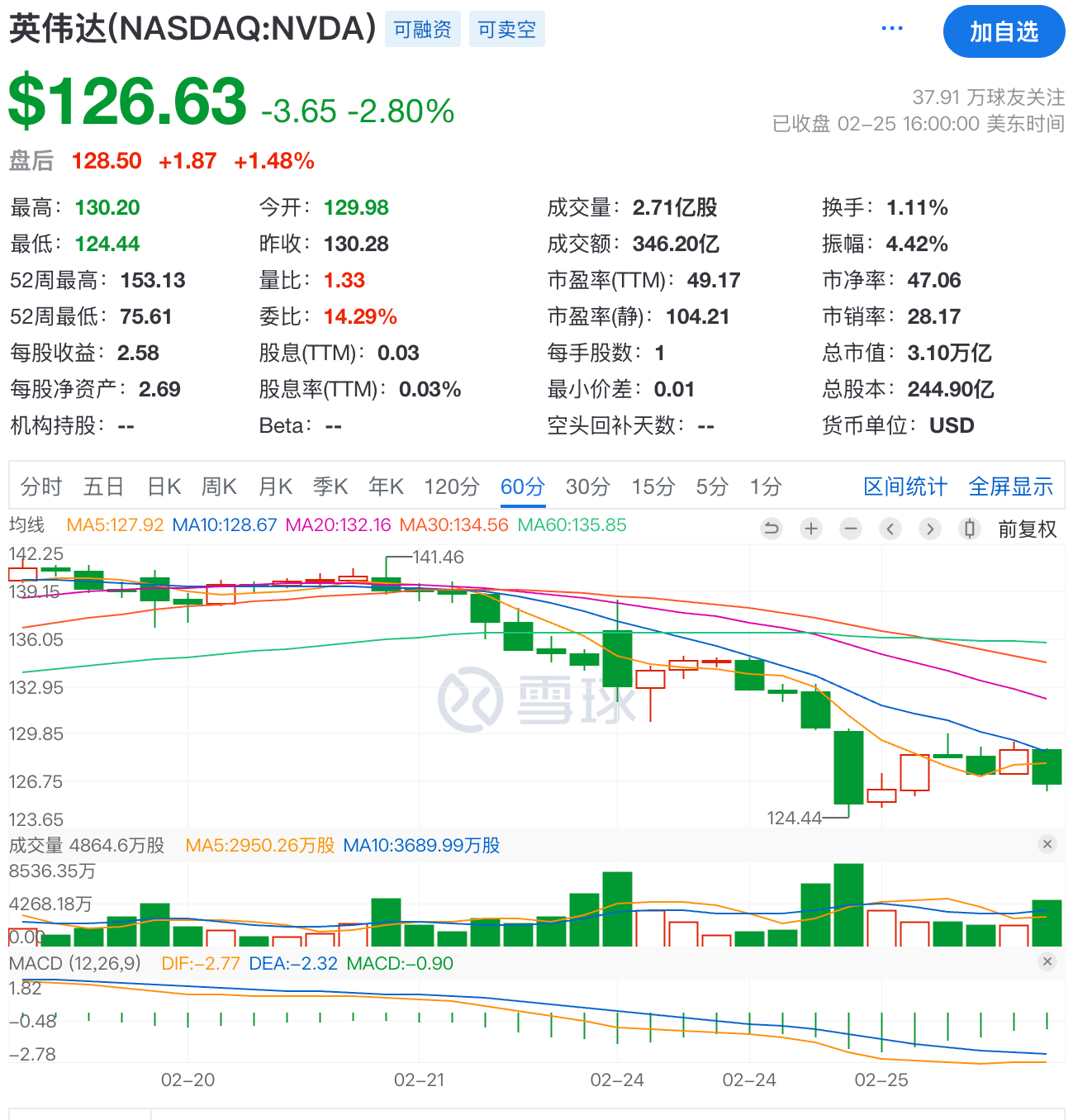
随着DeepSeek不断的开源代码,英伟达股价也在一路下跌,合理怀疑幻方量化又在做空英伟达。
为什么需要它?
AI模型的核心计算是“矩阵乘法”,就像做一道巨型数学题,需要处理海量数据。传统方法像是用32位或16位数字计算,虽然精确,但耗时长、占内存。而DeepGEMM用了FP8计算(相当于用8位数字),就像用更小的便利贴记笔记,虽然每张纸写的内容少了,但搬运和计算速度大幅提升,而且核心只有三百行代码。
不过,压缩计算会牺牲精度,为此DeepGEMM用了巧妙的“两步防错法”:
- 快速计算:先用FP8高速算出结果(允许小误差);
- 高精度汇总:定期转成32位数字仔细核对总和,避免误差积累。
省流评论…

已经有人开始抛售英伟达股票了

DeepGEMM的三大亮点
-
极致性能
在英伟达最新的Hopper架构GPU上,它的计算速度最高可达每秒1350万亿次浮点运算(TFLOPS),比专家手动优化的代码还要快,某些场景提速高达2.7倍。 -
轻装上阵
核心代码仅约300行,没有复杂的依赖项,像一本“精简版教程”,开发者能快速上手,还能自己动手优化。 -
灵活适配
支持两种主流计算模式:- 密集型计算(Dense):适合普通AI模型;
- 混合专家模式(MoE):适合更复杂的模型(比如需要动态调用不同“专家模块”的AI)。
对普通用户有什么影响?
- 更快的AI应用:比如生成图片、视频时,等待时间更短;
- 更省电:手机、电脑跑AI时更不容易发烫;
- 更低成本:企业用AI的算力开销可能降低。
技术宅专属细节
- 即时编译(JIT):安装时不用预编译代码,运行时根据硬件“现编现用”,灵活省资源;
- 专为Hopper GPU优化:利用英伟达最新显卡的硬件特性榨干性能;
- 开源社区友好:代码简洁清晰,欢迎开发者提交优化方案。
结语
DeepGEMM像一颗棱角分明的钻石——用数学之美切割冗余,让最基础的矩阵乘法焕发新生。当开源社区开始卷"如何把300行代码写成艺术品",受益的终将是每一个等待AI响应的人类。
项目地址:https://github.com/deepseek-ai/DeepGEMM
截止发版项目已经获得2000star了,热度持续飙升中!
我是洞见君,在这里不做AI焦虑的搬运工,只做你探索路上的提灯人。
关注后点击右上角"…"设为星标🌟,每周为你筛选真正值得读的AI干货,让重要更新永不迷路。
整理了这段时间验证过的AI工具包+实战信息差+DeepSeek资料库(持续更新中),放在了洞见AI世界知识库,关注公众号,扫描下方二维码备注"知识库"免费获取,希望能帮你绕过80%的人正在经历的信息泥潭。

















 773
773

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









