







在大规模模型训练与推理领域,通信效率一直是制约性能的关键瓶颈。今天,我们怀着激动的心情宣布:DeepSeek开源周第二弹迎来里程碑式突破——DeepEP(DeepSeek Efficient Parallel)正式开源!这是全球首个专注于MoE(Mixture of Experts)模型训练与推理的高性能通信库,旨在为开发者提供极致的效率优化与灵活的资源控制!
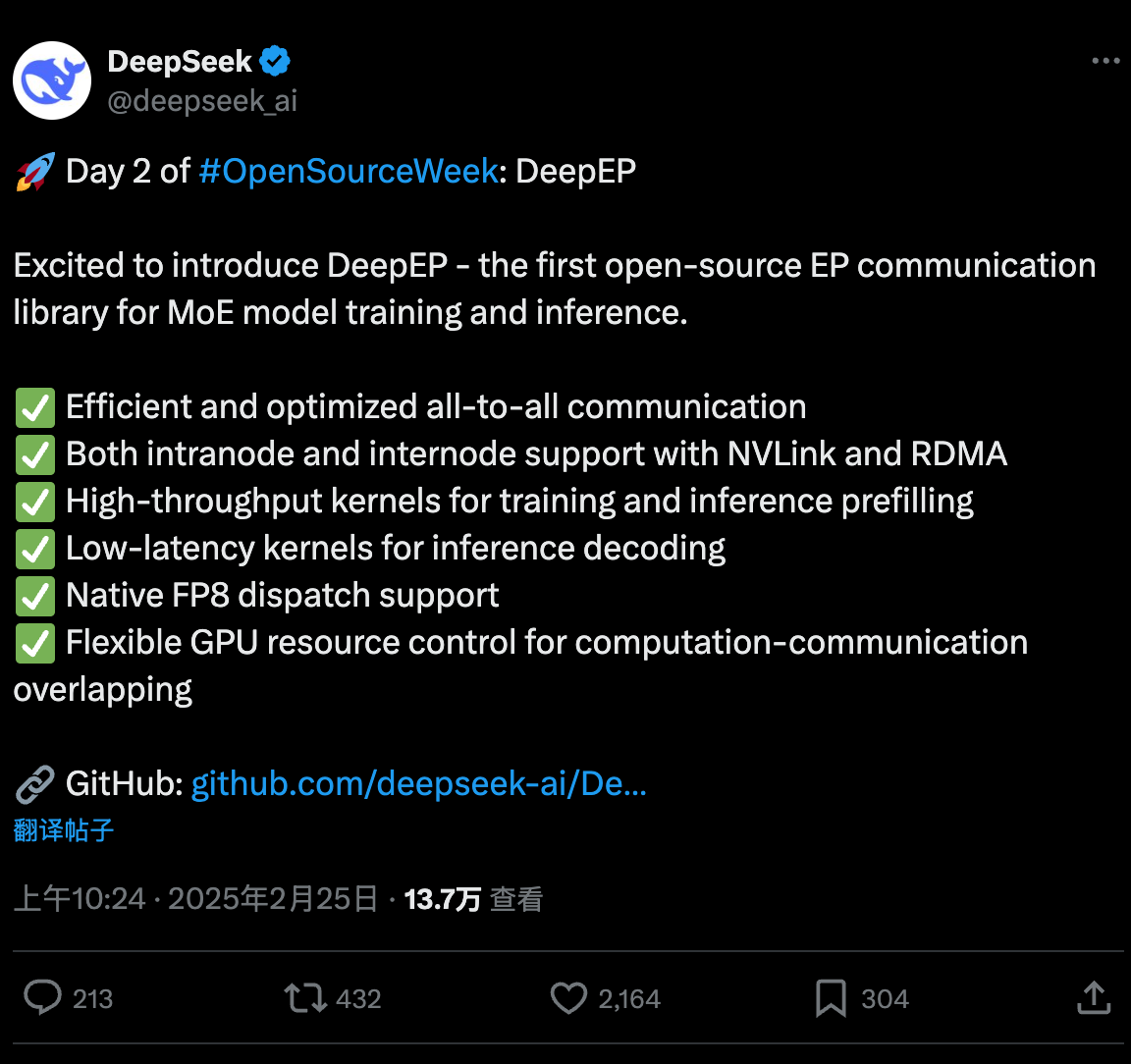
项目地址:https://github.com/deepseek-ai/DeepEP
截止小编发文,项目star数已经来到了1800,而昨天开源的FlashMLA短短24小时star数已经来到了8400,火的一塌糊涂。
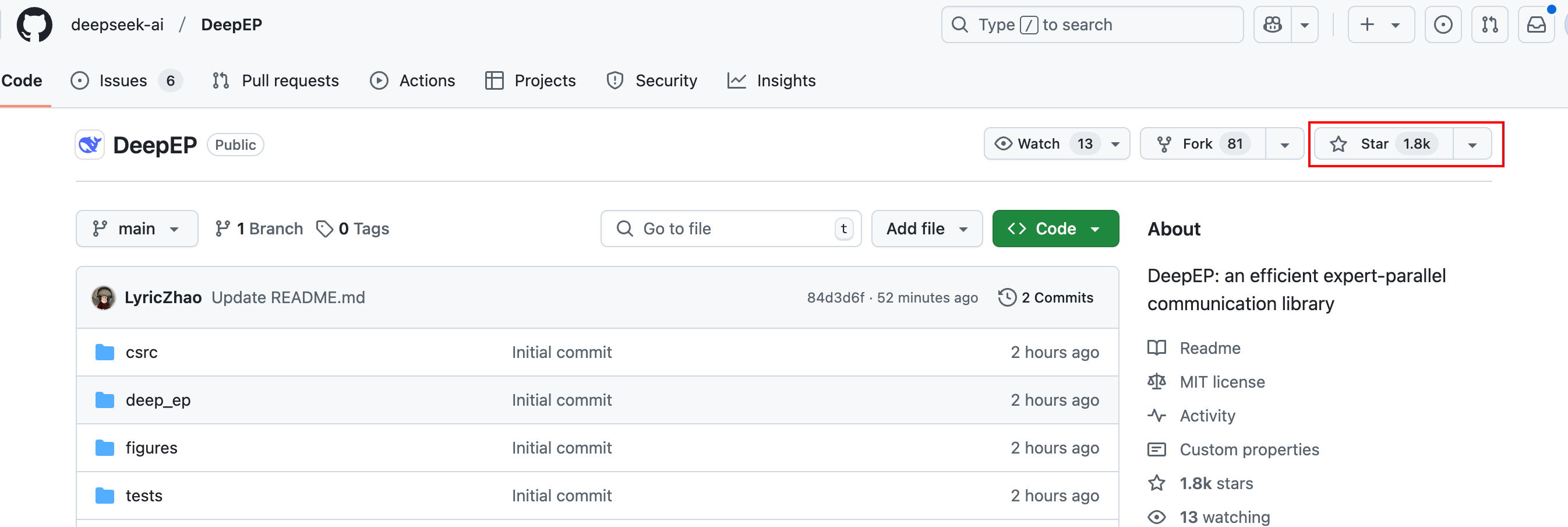
有人评论说最近这些天好像过了一百年似的

还有人评论这才是真正的开源AI

🌟 DeepEP 核心亮点速览
-
✅ 全交换通信(All-to-All)效率革命
专为MoE模型设计,针对All-to-All通信模式深度优化,突破传统通信库的带宽限制,实现超低延迟与超高吞吐,轻松应对千亿参数级模型训练。 -
✅ 跨节点+节点内无缝支持
基于NVLink高速互联与RDMA远程直接内存访问技术,无论是单机多卡还是跨节点集群,均能发挥极致性能,支持超大规模分布式训练。 -
✅ 训练推理双场景优化
- 训练场景:高吞吐预填充(Prefilling)内核,加速数据预处理与模型前向传播。
- 推理场景:超低延迟解码(Decoding)内核,响应速度提升数倍,实时推理体验更流畅。
-
✅ 原生FP8支持,算力利用率拉满
率先集成FP8数据格式通信调度,显著降低显存占用与通信开销,让AI硬件的算力潜能彻底释放! -
✅ 计算-通信重叠,资源分配更智能
动态调控GPU计算与通信资源占比,实现零空闲等待的流水线并行,训练效率提升高达30%!
更多信息请参见 GitHub 代码库。
DeepSeek的列车不会停止!

最后,你觉得DeepSeek第三弹会开源什么内容呢,让我们一起期待吧!
我是洞见君,在这里不做AI焦虑的搬运工,只做你探索路上的提灯人。
关注后点击右上角"…"设为星标🌟,每周为你筛选真正值得读的AI干货,让重要更新永不迷路。
整理了这段时间验证过的AI增效工具包和实战信息差(持续更新中),放在了洞见AI世界知识库,扫描下方二维码备注"知识库"免费获取,希望能帮你绕过80%的人正在经历的信息泥潭。

















 2522
2522

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









