






自DeepSeek模型以开源方式问世以来,大量的个人开发者和企业用户都在尝试紧抓这波技术变革带来的红利,重构原有的AI应用生态和创新AI应用场景,以提升通用、及行业应用场景的生产力。然而,DeepSeek的大规模应用,也需要高效、可靠的AI推理平台的支撑,如何将DeepSeek以更合理的模式部署到生产环境,成为关键需要解决的问题。
综合考虑了大模型的高并发、低延迟的响应要求,同时兼顾数据安全、隐私保护、资源可扩展、运维便利等方面的因素,总结出了以下4种部署模式,提供给各位企业用户作为实施DeepSeek落地的选择参考。
一、云平台托管模式
1. 模式简介
云平台托管是指将DeepSeek模型托管在专有云(专线接入的公有云)平台上,通过云平台提供的高性能智算资源实现模型的在线推理服务。
具体实现方案包括:
API网关接入:外部客户端通过RESTful API或gRPC等接口协议访问部署在云端的模型服务。
安全访问与数据加密:通过点对点专线对接模型服务和企业内应用;同时,云平台采用虚拟私有云(VPC)、安全组策略、访问控制列表(ACL)等手段确保数据传输和存储的安全性。
分布式计算与存储:采用分布式计算框架(如Kubernetes等)和存储系统(如HDFS等)来管理计算资源的并发效率和海量数据的访问效率,同时确保了资源的可扩展。
2. 主要特点
业务快速接入:现成的智算资源和DeepSeek各版本的私有化部署方案,能够快速的集成DeepSeek服务和提供业务接入。
降低运维成本:借助云平台的托管服务,企业不需要自行搭建和维护物理硬件设备,不涉及硬件的运维成本,只需管理好自有业务系统的运维。
资源可扩展:云平台提供分布式计算能力,可以根据访问流量的变化进行扩容或缩容,从而保证服务的稳定性。
技术支持与生态完善:云平台提供完善的技术支持、监控工具、日志分析以及安全管理等功能,确保系统易维护和问题可追踪。
3. 应用实践
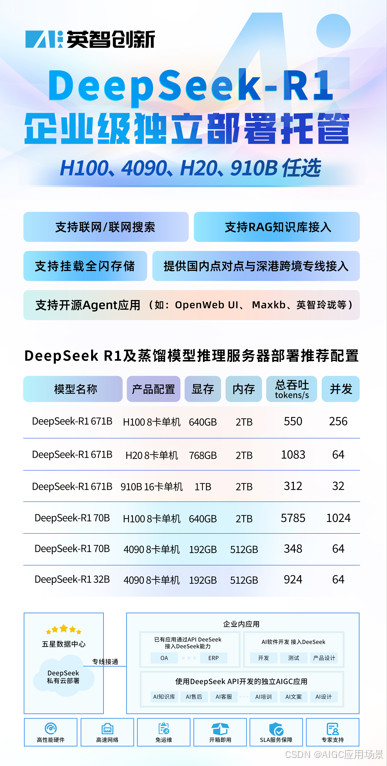
二、本地部署模式
1. 模式简介
本地部署是指将DeepSeek模型安装在企业内部数据中心或企业私有云环境中。此模式通常要求企业拥有自建的服务器集群和高性能计算设备,并配合内部网络进行数据传输与存储。
具体实现方案包括:
自有服务器集群搭建:在企业内部数据中心已有的高性能GPU服务器/服务器集群上部署DeepSeek模型服务,或者企业直接采购DeepSeek一体机/一体机集群。
内部API接口:通过内网IP或专用网络实现模型推理任务的调度和访问。
安全防护体系:由于运行在内网中,通常结合企业已有的安全体系(如防火墙、入侵检测系统等)保障数据安全与访问控制。
2. 主要特点
数据安全性高:所有数据均在内部网络中传输,避免了外部网络风险,有助于满足对数据隐私要求极高的企业应用场景。
资源自主可控:企业可以完全掌握硬件、软件和安全策略,便于根据企业需求进行定制化优化。
3. 应用实践
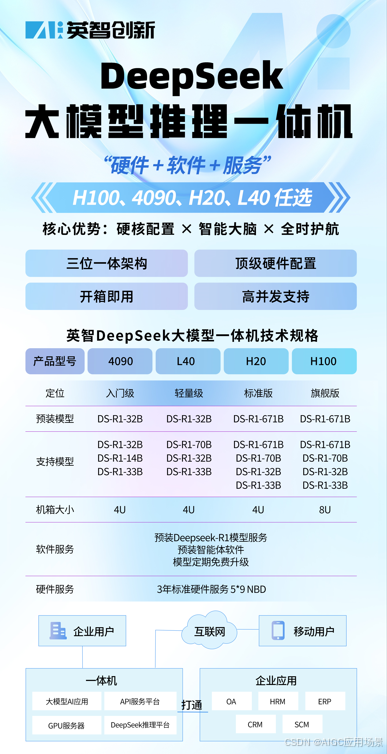
三、混合部署模式
1. 模式简介
混合部署是指将DeepSeek模型的不同参数版本,根据企业的业务场景需求和资源情况,分别选择部署在企业端或云端,以达到性能与安全的平衡。
具体实现方案包括:
分层架构设计:将DeepSeek中/小参数模型部署在企业内网环境或边缘节点,以处理前端需要实时响应的推理任务;将DeepSeek大参数/全参模型托管在专有云环境,以处理复杂场景的推理任务。
数据联动机制:边缘设备对数据做初步处理和本地推理,需要进一步处理的关键信息推送至云端,由云端模型进行二次推理和精细化分析。
2. 主要特点
兼顾实时性和精度:本地/边缘节点服务可以提供低延时的初步响应,而云端资源则可以提供更强大的推理能力和模型精度,两端能力互补,从而提高整体用户体验。
服务容错能力强:当本地/边缘节点服务出现故障时,云端系统可临时接管部分任务,整体服务具有较强的鲁棒性。
成本与安全平衡:企业知识库,可以搭建在本地,以实现部分数据在本地处理、敏感数据不外传,在一定程度上降低安全风险;同时,通过合理分配推理任务,可降低对高性能硬件资源的依赖,优化成本。
四、容器化部署模式
1. 模式简介
容器化部署是指将DeepSeek模型服务封装为容器或微服务模块进行部署。
具体实现方案包括:
Docker容器化:将DeepSeek模型及其依赖环境打包成Docker镜像,实现一键部署。
Kubernetes编排:利用Kubernetes等容器编排工具,实现多实例部署、自动伸缩、故障恢复以及迭代更新等。
微服务通信:通过RESTful API、gRPC或消息队列等机制,将大模型服务与其他业务模块解耦,实现灵活调用和分布式协作。
2. 主要特点
高可移植性:容器化部署使得服务在不同环境间迁移时降低部署和配置的复杂性,提升了系统的跨平台兼容性和迁移效率。
灵活扩展和管理:借助Kubernetes等平台,可以动态调整副本数、监控容器健康状况,并实现自动故障恢复,保证服务稳定性。
降低开发与运维复杂性:微服务架构使得各个模块之间解耦,便于独立开发、测试和更新,提升团队开发效率,同时也便于后期系统的维护和监控。
个人开发者和初创企业
针对个人开发者和初创企业,在考虑成本投入和项目快速启动方面,可以选择另外一种方式,即:DeepSeek API公有云服务。
应用实践:https://api.baystoneai.com
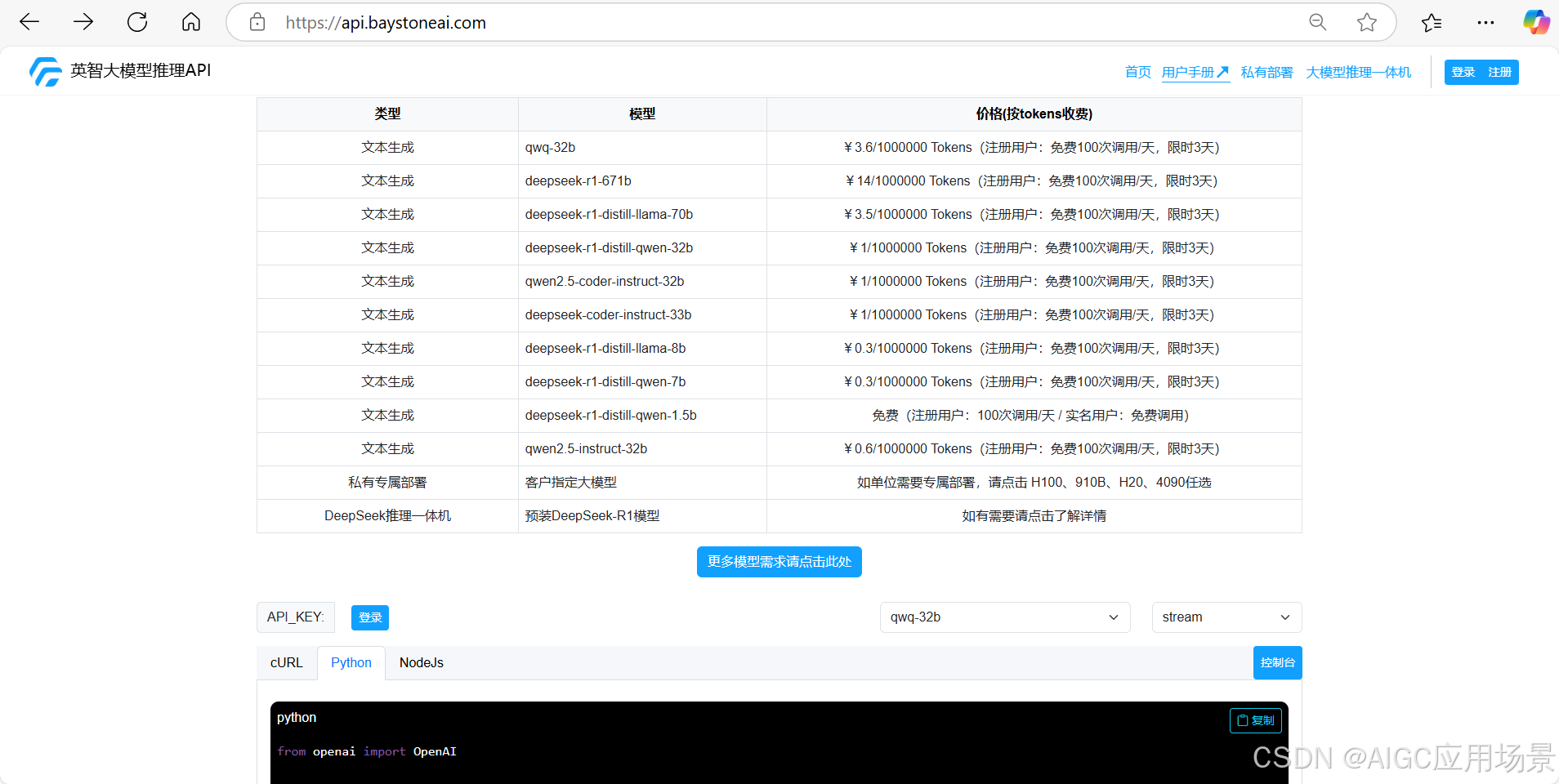
总结与建议
对于DeepSeek模型的企业级部署,企业需要根据自身业务特性、数据安全要求、预算成本、以及技术能力等综合考虑,选择最合适的部署方案。

















 2306
2306

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









