






感知机
美国学者Frank Rosenblatt在1957年提出来的。
给予输入x, 权重 w 和偏差b;感知机输出:
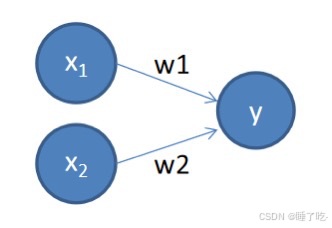
w成为权重:控制输入信号的重要性的参数
b称为偏置:偏置是调整神经元被激活的容易程度参数
感知机
二分类 (0 或 1)
Vs. 回归:输出实数
Vs. Softmax:输出的概率,多个分类
感知机应用:简单逻辑电路
与门
与非门
或门
感知机训练过程
异或门
感知局限性
感知机的局限性:感知机的局限性就是只能表示由一条直线分割的空间。
面对这种线性不可分的情况该怎么办呢?
用非线性的曲线划分出非线性空间
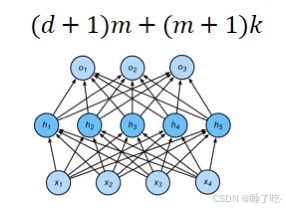
——多层感知机:最简单的深度神经网络
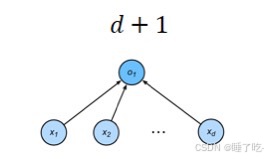
单隐藏层

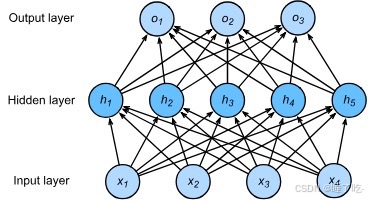
单隐藏层-单分类
输入:
隐藏层:
输出:
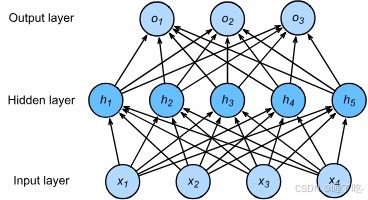
激活函数
激活函数在神经元中非常重要的。为了增强网络的表示能力和学习能力,激活函数需要具备以下几点性质:
(1) 连续并可导(允许少数点上不可导)的非线性函数。
(2) 激活函数及其导函数要尽可能的简单,有利于提高网络计算效率。
(3) 激活函数的导函数的值域要在一个合适的区间内,不能太大也不能太小,否则会影响训练的效率和稳定性。
总结
多层感知机使用隐藏层和激活函数来得到非线性模型常用激活函数是Sigmoid,Tanh,RELU使用Softmax来处理多分类超参数为隐藏层数和各个隐藏层大小
学习过程
学习的过程:
神经网络在外界输入样本的刺激下不断改变网络的连接权值乃至拓扑结构,以使网络的输出不断地接近期望的输出。
学习的本质:
对可变权值的动态调整
参数更新
前向传播(正向传播)
输入样本--输入层--各隐藏层--输出层
反向传播(误差反传)
输出层——各隐藏层——输入层
计算神经网络参数梯度的方法
修正各层单元的权值
训练误差和泛化误差
训练误差:模型在训练数据集上的误差
泛化误差: 模型在新数据集上的误差
示例:使用历年试真题准备将来的考试
再历年考试真题取得好成绩(训练误差)并不能保证未来考试成绩更好(泛化误差)
学生A 通过死记硬背学习在历年真题考试中取得好成绩
学生B理解并给出答案的解释
过拟合和欠拟合
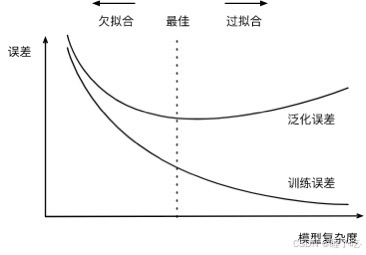
当学习器把训练样本学得"太好"了的时候,很可能已经把训练样本自身的一些特点当作了所有潜在样本都会具有的一般性质——过拟合;
对训练样本的一般性质尚未学好——欠拟合
模型复杂度的影响
数据复杂度的影响
多种因素很重要:
样本数量
每个样本中的特征数量
时间、空间结构
多样性


















 1838
1838

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









