






Transformer架构自2017年提出以来,在自然语言处理(NLP)领域取得了巨大成功,如BERT、GPT等模型推动了语言理解的飞速发展。如今,Transformer技术在计算机视觉(CV)领域也展现出巨大潜力,如Swin Transformer等模型,为图像分类、目标检测等任务带来了新的突破,促进了视觉与语言的统一建模。
Swin Transformer通过引入层次化结构和移位窗口机制,解决了传统Transformer在视觉任务中计算复杂度高、难以处理高分辨率图像等问题,实现了线性计算复杂度,同时保持了强大的建模能力。
这种技术推动了视觉与语言任务的协同发展,为多模态应用提供了更强大的基础,有望进一步提升人工智能系统的性能和通用性。
我整理了10种【Transformer】的相关论文,全部论文PDF版可以关注工棕号{AI因斯坦}
回复 “T创新”领取~
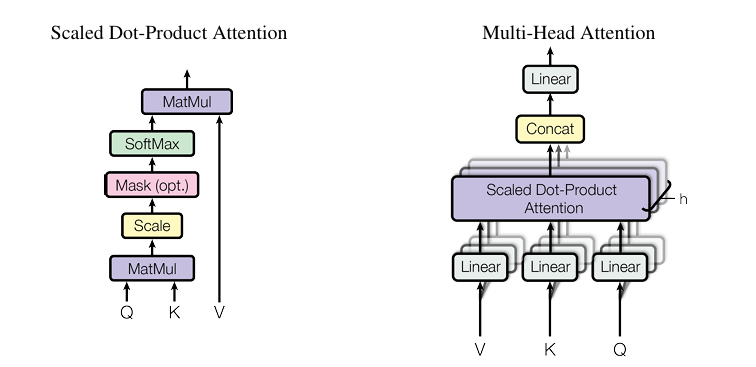
1.Attention Is All You Need
文章提出 Transformer 模型,摒弃循环和卷积,基于注意力机制构建。经实验验证,该模型在机器翻译任务上效果卓越,训练效率高,为序列转换模型发展提供新方向。
-
创新点
1.创新架构设计,Transformer 完全基于注意力机制,舍弃循环和卷积,使模型能更好捕捉长距离依赖关系。
2.提出缩放点积注意力和多头注意力机制,前者解决大维度下梯度消失问题,后者可让模型关注不同子空间信息
3.采用位置编码为模型注入序列顺序信息,且共享嵌入层和预 Softmax 线性变换权重矩阵,提升模型性能 。
-
研究结论
1.在 WMT 2014 英德和英法翻译任务中,Transformer 模型取得最领先的成绩,超越此前所有模型,且训练成本更低。
2.实验表明,模型的多头注意力机制、适当的模型规模和随机失活等组件对性能提升至关重要。
3.基于注意力机制的 Transformer 模型具有很大的应用潜力,未来可拓展到更多任务和模态 。
全部论文PDF版可以关注工棕号{AI因斯坦}
回复 “T创新”领取~
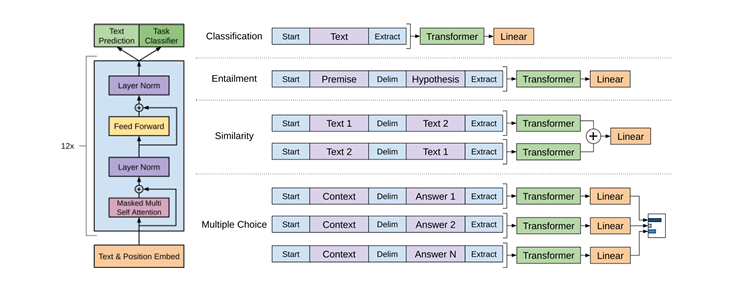
2.Improving Language Understanding by Generative Pre-Training
文章提出通过生成式预训练和判别式微调提升语言理解能力。在多任务实验中表现出色,验证了方法有效性,为自然语言处理领域提供新思路。
-
创新点
1.创新地采用两阶段训练框架,先在无监督语料库上进行生成式预训练,再针对特定任务微调,有效利用无监督数据提升模型性能。
2.设计任务特定的输入转换方式,将结构化输入转化为序列,减少模型架构修改,使预训练模型能更好地适应不同任务 。
3.利用 Transformer 架构捕捉长距离依赖,相较于 LSTM,在多种自然语言理解任务上表现更优,推动了语言模型发展 。
-
研究结论
1.该模型在 9 个数据集上取得最领先的成绩,在常识推理、问答、文本蕴含等任务上显著超越之前的方法,性能提升明显。
2.预训练层数对模型性能有积极影响,每增加一层都能带来一定提升,Transformer 架构有助于提升零样本学习能力。
3.辅助语言建模目标、预训练等对模型性能提升至关重要,证明了半监督学习方法在自然语言处理任务中的有效性 。
全部论文PDF版可以关注工棕号{AI因斯坦}
回复 “T创新”领取~
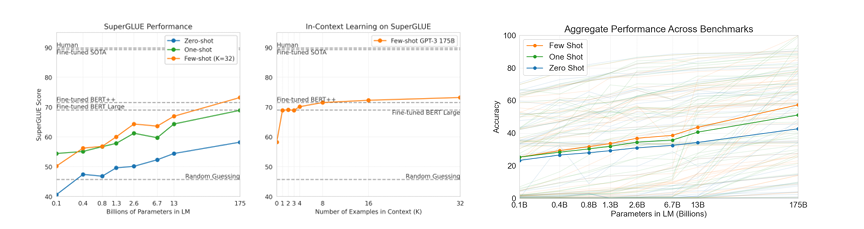
3.Language Models are Few-Shot Learners
文章训练了 1750 亿参数的 GPT-3 模型,验证其在少样本学习下的表现。研究发现模型性能随规模提升,在多任务上表现出色,但也存在局限性,为语言模型发展提供参考。
-
创新点
1.训练出具有 1750 亿参数的 GPT-3 模型,突破模型规模限制,探索语言模型性能随规模扩展的规律。
2.提出少样本学习模式,模型无需梯度更新,仅通过文本交互就能完成任务,拓展了语言模型应用方式。
3.对模型的公平性、偏见等方面进行分析,关注语言模型的社会影响,为后续研究提供新视角 。
-
研究结论
1.GPT-3 在零样本、一样本和少样本设置下,在多个 NLP 任务和基准测试中表现出色,部分结果接近或超越微调的最先进系统。
2.模型性能随规模扩大呈现可预测的提升趋势,但在一些涉及句子比较等特定任务上仍表现较弱。
3.GPT-3 存在生成文本的质量、偏见、能耗等问题,未来需结合其他方法改进,同时要关注其社会影响 。
全部论文PDF版可以关注工棕号{AI因斯坦}
回复 “T创新”领取~
顶会投稿交流群来啦!
欢迎大家加入顶会投稿交流群一起交流~这里会实时更新AI领域最新资讯、顶会最新动态等信息~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









