






近年来,语言模型和视觉语言模型在处理长文本和视频方面取得了显著进展。然而,现有模型大多受限于较短的序列长度,难以处理复杂的长篇内容。本文提出了一种能够处理百万级(1M)长度序列的模型,为长文本和长视频理解开辟了新天地,有望推动智能系统在更广泛领域的应用。
VLM通过大规模数据合成和预训练增强空间推理能力,3D-IntPhys结合隐式和显式3D表示实现复杂场景的物理预测。
极大地提升长文本和长视频的理解能力,为智能问答、视频分析和机器人视觉等领域的应用带来更强大的支持,推动人工智能向更智能、更高效的方向发展。
我整理了10种【具身智能】的相关论文,全部论文PDF版可以关注工棕号{AI因斯坦}
回复 “具身智能”领取~
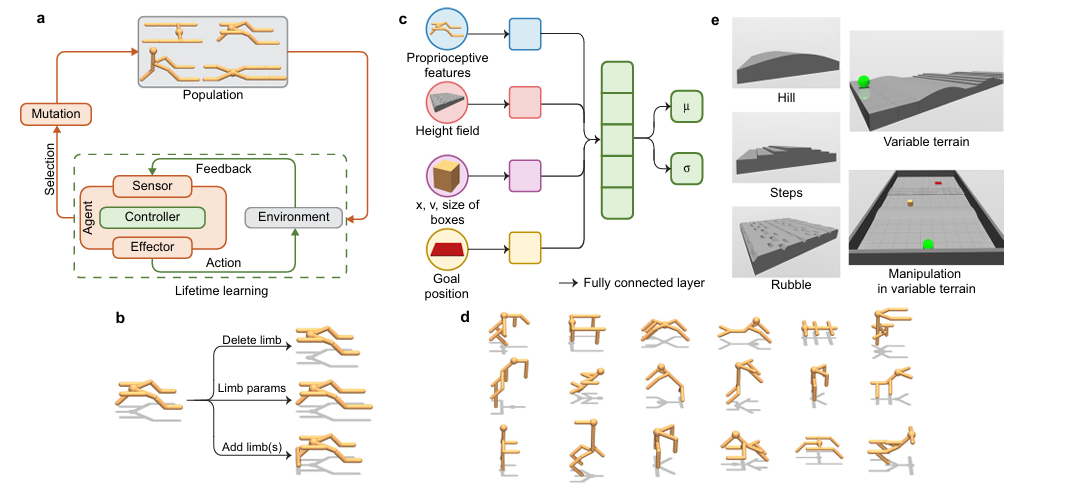
1.Embodied intelligence via learning and evolution
文章提出深度进化强化学习(DERL)框架,通过模拟进化和强化学习,研究环境复杂性、进化形态与智能控制学习能力的关系,揭示了形态智能和鲍德温效应等现象。
-
创新点
1.构建 DERL 计算框架,实现大规模模拟实验,突破传统研究局限。
2.提出评估形态智能的范式,量化形态对强化学习速度和性能的促进作用。
3.发现形态鲍德温效应,揭示其机制与能量效率、稳定性的关联。
-
研究结论
1.环境复杂性促进形态智能的进化,复杂环境中进化的形态能更好更快地学习新任务。
2.存在形态鲍德温效应,进化会选择学习速度更快的形态,加速学习进程。
3.能量效率和稳定性是形态智能和鲍德温效应的重要物理基础
全部论文PDF版可以关注工棕号{AI因斯坦}
回复 “具身智能”领取~
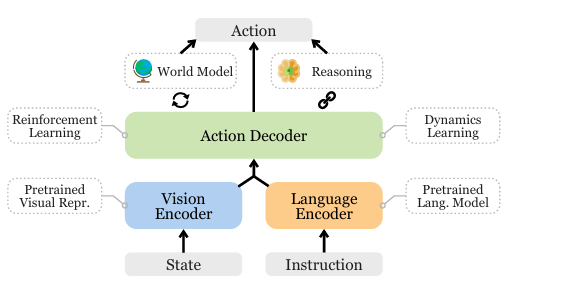
2.A Survey on Vision-Language-Action Models for Embodied AI
文章聚焦于具身人工智能中的视觉 - 语言 - 动作(VLA)模型,阐述其发展背景,提出分类体系,介绍相关模型、资源,讨论挑战与未来方向,为该领域研究提供全面综述。
-
创新点
1.首次对 VLA 模型进行全面调研,提出广义 VLA 定义及分类法,涵盖组件、控制策略和任务规划器。
2.总结训练和评估 VLA 模型所需资源,分析现有数据集、基准测试和模拟器的问题与应对方法。
3.探讨 VLA 面临的多方面挑战及未来发展方向,如安全、泛化能力、多模态融合等,为后续研究指明方向。
-
研究结论
1.VLA 模型在处理语言条件机器人任务方面展现潜力,但仍面临安全、数据稀缺、泛化能力不足等挑战。
2.现有数据集和基准测试存在局限性,需要开发更全面的基准测试和指标来评估 VLA 模型。
3.未来 VLA 研究应关注基础模型的发展、多模态融合、长周期任务框架优化及实时响应能力提升等方向。
全部论文PDF版可以关注工棕号{AI因斯坦}
回复 “具身智能”领取~
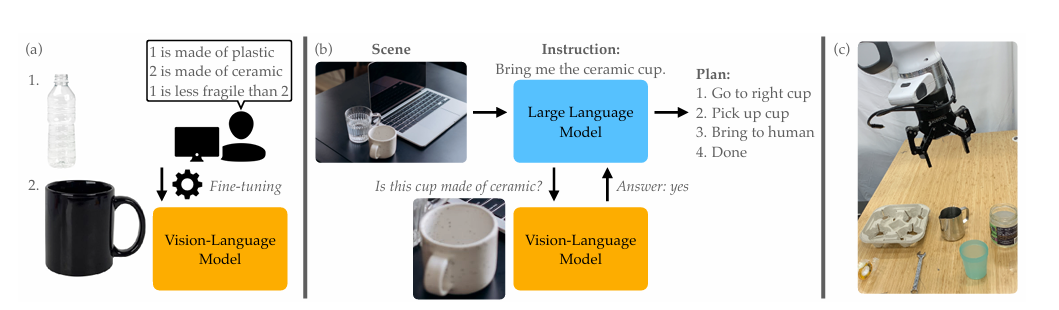
3.Physically Grounded Vision-Language Models for Robotic Manipulation
文章提出 PHYSOBJECTS 数据集,用于微调视觉语言模型(VLM)以提升其对物体物理概念的理解,将微调后的 VLM 融入机器人规划框架,在多方面实验中验证了方法的有效性。
-
创新点
1.构建 PHYSOBJECTS 数据集,包含大量真实家庭物体的物理概念注释,为训练 VLM 提供数据支持。
2.提出用该数据集微调 VLM 的方法,增强模型对物理概念的理解能力,包括对未见概念的泛化能力。
3.将物理概念理解能力集成到基于大语言模型的机器人规划框架中,提升机器人在相关任务中的规划性能。
-
研究结论
1.用 PHYSOBJECTS 数据集微调 VLM 可显著提高其物理推理能力,在测试准确性和泛化能力上均有提升。
2.融入微调后 VLM 的机器人规划框架,在涉及物理推理的任务中规划性能更好,真实机器人执行任务的成功率更高。
3.研究为拓展 VLM 在机器人领域的应用提供了方向,但模型仍存在不足,未来可通过改进数据和拓展概念等方式优化。
全部论文PDF版可以关注工棕号{AI因斯坦}
回复 “具身智能”领取~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









