







什么是贪心算法?
贪心算法是每次都选择在当前看来最优的解,从局部最优解体现全局最优解的一种算法,它与其它算法不同的是它往往没有固定的算法模板,但经过最近的学习还是可以总结几个经典问题的解决思路的
大致都有哪几个经典类型?有怎样的想法?
1.推公式类型
这类问题的关键是在确定是贪心算法后,按照交换前后的两种情况,推出不同的公式,从而确定为什么第一种比第二种更优,将问题对象排序即可。
这里举一个例子:
分析这个问题时首先考虑从局部入手,最重要的其实是排序出将要牵走的牛的先后顺序,设想:如果某一步中相邻两个奶牛的顺序交换不会对它们之前和之后的部分产生影响的话,那么我们就可以大胆的选取局部最优,从而在最终体现出全局最优,这也就体现出了贪心算法的核心。
此时,我们假设局部是第i头和第j头奶牛,交换它们被牵走的顺序,很明显不会对它们之前和之后的牛吃掉的花数产生影响,此时就可以大胆的贪心了!
即为:

此时我们只需要实现对应的排序函数,将该函数传给sort即可,函数如下:
//首先是有结构体类型的数组来存储每个奶牛的信息的
struct node
{
int t;
int d;
}a[i];
//实现比较函数
bool cmp(node& x,node& y)
{
return x.t * y.d < y.t * x.d;
}这就是推公式类型大致的一些想法。
2.线段覆盖问题
这类问题在确定贪心算法后,首先要对若干个目标区间进行排序,具体要如何排序,需要进行尝试,同时,后续的过程没有确定的方法,但往往排序确定了,后面的问题将迎刃而解!
同样,举一个例子:

这个问题中每个奶牛对应了不同的区间,那么我们的贪心策略就是按某种方式对这些区间进行排序,后面的过程即就是列举被排好序的所有的奶牛,再按某种涂抹防晒霜的顺序将防晒霜涂给他们即可。
要注意的的是,对于奶牛的耐晒区间我们可以对它们按左端点升序、降序,右端点升序、降序,不仅如此,对于防晒霜来说,也可以从高往低涂,和从高往低涂,所以共有8种排列方式,在这里我将举一个列举的例子来说明这个问题,如下:
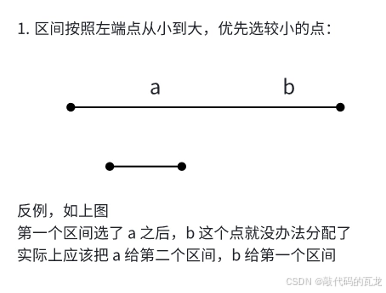
后面的所有列举都和上面这一种相同,要注意的是一定要判断重叠的情况,这很容易举出反例,在列举结束后,我们知道有两种方式可以解决问题:
1.左端点从大到小排列,防晒霜也从大到小排列
2.右端点从小到大排列,防晒霜也从小到大排列
上面两种方法异曲同工,我将举出第一种情况对应的比较函数:
//奶牛的信息依旧用结构体数组来存储,由于防晒霜也有两个参数,所以公用同一种结构体
struct node
{
int x;//奶牛的左端点和防晒霜的强度
int y;//奶牛的右端点和防晒霜的数量
}a[N],b[N];
//实现比较函数
bool cmp(node& x,node& y)
{
return x.x < y.x
}
//注意:由于防晒霜和奶牛都是按node中的x变量来从大到小比较大小,所以它们公用一个函数这就是线段覆盖问题的一些大致想法。
结语:
感谢各位亦菲,于晏来和我一起探讨,一起进步!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









