







在前期的博文中我们一起讨论了逻辑回归,聚类回归等分类方法,本次博文和大家一起讨论决策树,异常检测,数据降维等算法。
1 决策树
决策树顾名思义就是对实例进行分类的树形结构,通过多层判断区分目标所属类别,其本质就是通过多层判断,从训练数据集中归纳出一组分类规则。由于它没有像聚类分析等算法那样的迭代计算,所以决策树算法具有计算量小,运算速度快,易于理解,可清晰查看各属性的重要性。但同时由于各个判断的分散,该算法容易忽略属性的相关性,当样本类别分布不均匀时,容易影响模型表现。
它的目标是根据训练数据集构建一个决策树模型,使它能够对实例进行正确的分类,常见的方法有ID3,C4.5,CART等
ID3:
利用信息熵原理选择信息增益最大的属性作为分类属性,递归地拓展决策树的分支,完成决策树的构造。其中信息熵entropy是度量随机变量不确定性的指标,熵越大,变量的不确定性就越大,假定当前样本集合D中第K类样本所占的比例为pk,则D的信息熵为
ent(D)的值越小,变量的不确定性越小。Pk=1时,ent(D)=0。根据信息熵,可以计算属性a进行样本划分带来的信息增益:
V为根据属性a划分出的类别数,D为当前样本总数,Dv为类别v样本数。目标是划分样本分布不确定性尽可能小,即划分信息熵小,信息增益大。这个公式如果pk=1时Ent(D)=0,表示熵最小确定性最高,同样如果pk=0,Ent(D)=0,确定性也是最高的。
案例:对于一个新专业自己能否学好,设计了从兴趣,是否有学习动力,是否有时间等几个维度来判断,通过信息采集得到下面表格:
| ID | 学习动力 | 是否有提升需求 | 是否感兴趣 | 是否有时间 | 类别 |
| 1 | 一般 | 否 | 否 | 有 | 否 |
| 2 | 一般 | 否 | 是 | 无 | 否 |
| 3 | 很强 | 是 | 是 | 有 | 是 |
| 4 | 一般 | 否 | 否 | 有 | 否 |
| 5 | 一般 | 否 | 否 | 无 | 否 |
| 6 | 一般 | 是 | 否 | 无 | 否 |
| 7 | 一般 | 是 | 是 | 有 | 是 |
| 8 | 一般 | 是 | 是 | 有 | 是 |
| 9 | 很强 | 是 | 是 | 有 | 是 |
| 10 | 弱 | 是 | 否 | 无 | 否 |
如何设计决策树?需要求解信息增益。
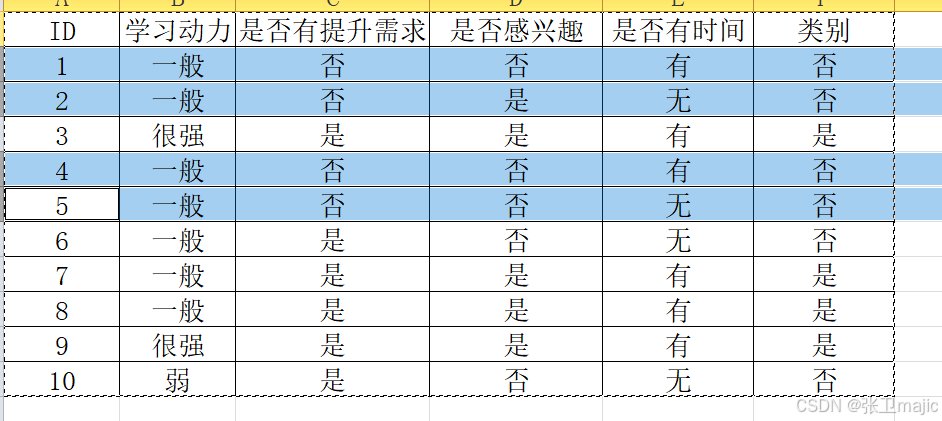
此处注意提升为否是类别为否的概率为1,为是的概率为0,故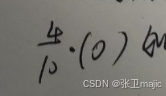
此处注意算法。
用同样的方法可以计算各个因素的信息增益。计算结果如下:
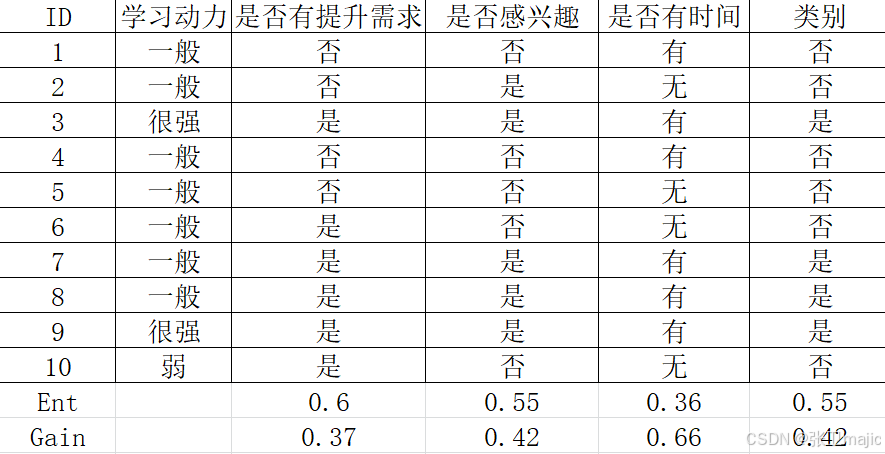
从而确定决策树的节点次序。
决策树算法看起来很多公式挺唬人,其实道理也很见到那就是判断哪个因素对最终结果的影响最大,当然要考虑正面和负面两个维度,因此数学家就用上面公式反映了这个意图而已,请深刻体会。
决策树的难点也就是确定增益来确定分支顺序。
决策树案例使用sklearn中自带的数据iris数据进行演示
读取数据
读取包,并显示数据
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from sklearn.cluster import KMeans
from sklearn.neighbors import KNeighborsClassifier
from sklearn.cluster import MeanShift,estimate_bandwidth
from sklearn import datasets
iris=datasets.load_iris()
print((iris.data))
for sj in iris.data:
print(sj);
要对数据进行模型训练,需要加载tree包,from sklearn import tree,然后构造算法,明确分类用ID3算法,使用信息熵。
criterion='entropy', 参数决定使用ID3算法
min_samples_leaf=5,最小5层,即决定划分的层数。这个层数过多会导致过拟合。
然后通过tree.plot_tree方法可以将分类可视化。
tree.plot_tree(mytree,filled='true',feature_name=['SepalLength','SepalWidth','PetalLength','PetalWidth'],class_names=['lei1','lei2','lei3'])
这里传递参数告诉生成树以及要不同的类别颜色填充以及特征依赖的特征--这些要符合数据中的字段名,后面的classname可以是自己定义。
iris=datasets.load_iris()
mytree=tree.DecisionTreeClassifier(criterion='entropy',min_samples_leaf=5)
mytree.fit()
tree.plot_tree(mytree,filled='true',feature_name=['SepalLength','SepalWidth','PetalLength','PetalWidth'],class_names=['lei1','lei2','lei3'])
2 异常检测:
什么是异常
异常就是不同寻常,如果用数学描述的话就是发生了小概率事件,说到概率就要提及概率密度这个概念,概率密度:描述随机变量在某个确定的取值点附近的可能性函数。
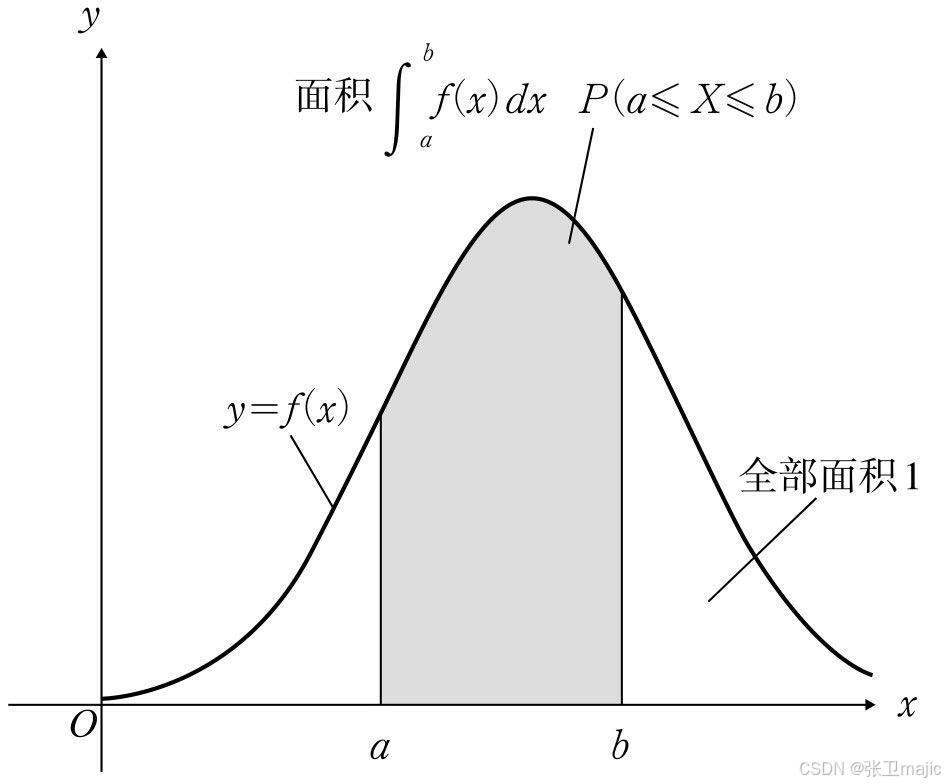
其中最常用的就是高斯密度函数,也成为正态分布函数:
PCA(principal components analysis)即主成分分析技术,又称主分量分析,旨在利用降维的思想,把多指标转化为少数几个综合指标。PCA(principal components analysis)即主成分分析技术,又称主分量分析,旨在利用降维的思想,把多指标转化为少数几个综合指标。
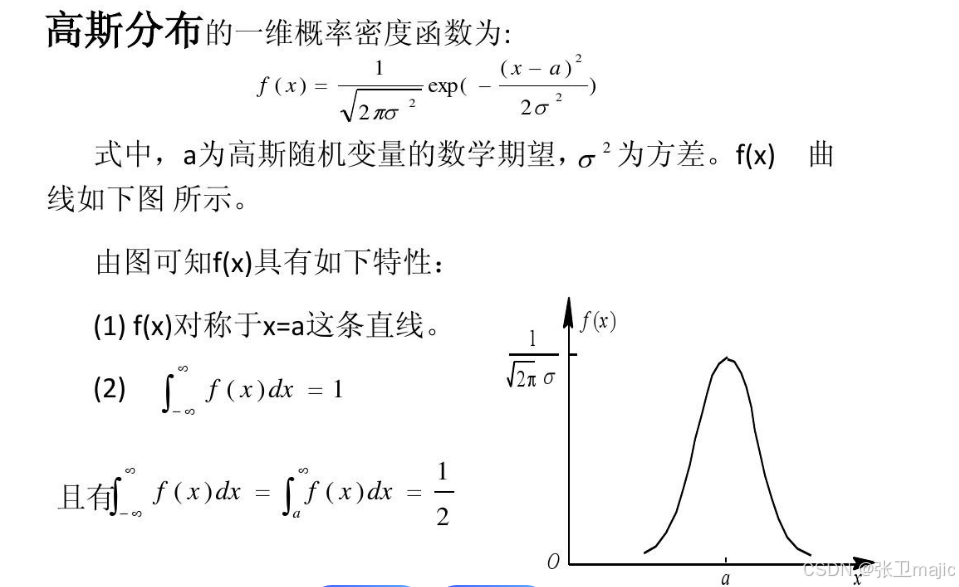
这个算法是为了解决在大量数据中找出异常数据。在历年数学建模中总有大量的异常数据,请注意结合高维密度函数进行分析和使用。
对应异常检测的计算要计算其均值μ和方差σ。利用工具包 from scipy.stats import norm

训练模型需要加载 from sklearn.covariance import EllipicEnvelope,使用前面读取的iris数据库中第一列数据构建正态分布图代码如下:
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from sklearn.cluster import KMeans
from sklearn.neighbors import KNeighborsClassifier
from sklearn.cluster import MeanShift,estimate_bandwidth
from sklearn import datasets
from sklearn import tree
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from scipy.stats import norm
iris=datasets.load_iris()
mytree=tree.DecisionTreeClassifier(criterion='entropy',min_samples_leaf=5)
x1=iris.data[:,0]
x1_mean=x1.mean()
x1_sigma=x1.std()
x1_range=np.linspace(0,20,300)
x1_normal=norm.pdf(x1_range,x1_mean,x1_sigma)
plt.plot(x1_range,x1_normal)
plt.show()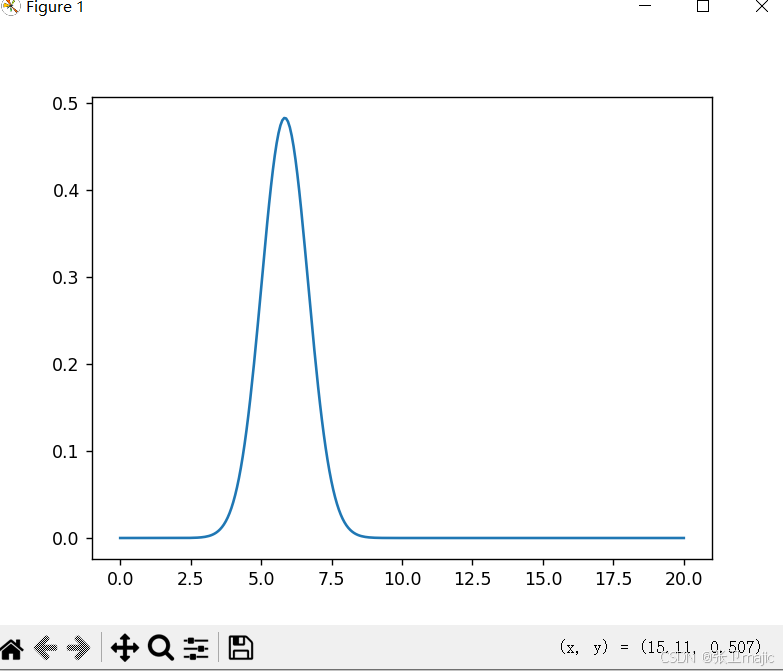
它是针对如果数据在概率密度极小的区域则判断为异常,在下次代码中给出各个属性即各个列的正态分布图。在sklean中可以直接用EllipticEnvelope包来监测异常。clf=EllipticEnvelope() clf.fit(data)
检测异常代码
利用sklean中的包可以很容易训练出模型,判断哪些是异常点:
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from sklearn.cluster import KMeans
from sklearn.neighbors import KNeighborsClassifier
from sklearn.cluster import MeanShift,estimate_bandwidth
from sklearn import datasets
from sklearn import tree
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from scipy.stats import norm
from sklearn.covariance import EllipticEnvelope
iris=datasets.load_iris()
mytree=tree.DecisionTreeClassifier(criterion='entropy',min_samples_leaf=5)
x1=iris.data[:,0]
x1_mean=x1.mean()
x1_sigma=x1.std()
x1_range=np.linspace(0,20,300)
x1_normal=norm.pdf(x1_range,x1_mean,x1_sigma)
x2=iris.data[:,1]
x3=iris.data[:,2]
x4=iris.data[:,3]
x2_mean=x2.mean()
x2_sigma=x2.std()
x3_mean=x3.mean()
x3_sigma=x3.std()
x4_mean=x4.mean()
x4_sigma=x4.std()
x2_normal=norm.pdf(x1_range,x2_mean,x2_sigma)
x3_normal=norm.pdf(x1_range,x3_mean,x3_sigma)
x4_normal=norm.pdf(x1_range,x4_mean,x4_sigma)
plt.plot(x1_range,x1_normal)
plt.plot(x1_range,x2_normal)
plt.plot(x1_range,x3_normal)
plt.plot(x1_range,x4_normal)
plt.show()
clf=EllipticEnvelope()
clf.fit(iris.data)
y_pre=clf.predict(iris.data)
print(y_pre,pd.value_counts(y_pre))
此处代码也打印了所有的四个维度的正态分布图,我没有截图,代码直接运行可以得到图,我只截取了获得的异常点预测:
并给出了统计结果
异常可视化
前面统计了各个属性维度的异常,为了直观显示出异常点,需要将其可视化,而可视化比较好的是在二维,而我们的维度是四维,这个是在第三点数据降维中体现,现在看如下代码:
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from sklearn.cluster import KMeans
from sklearn.neighbors import KNeighborsClassifier
from sklearn.cluster import MeanShift,estimate_bandwidth
from sklearn import datasets
from sklearn import tree
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from scipy.stats import norm
from sklearn.covariance import EllipticEnvelope
iris=datasets.load_iris()
mytree=tree.DecisionTreeClassifier(criterion='entropy',min_samples_leaf=5)
x1=iris.data[:,0]
x1_mean=x1.mean()
x1_sigma=x1.std()
x1_range=np.linspace(0,20,300)
x1_normal=norm.pdf(x1_range,x1_mean,x1_sigma)
x2=iris.data[:,1]
x3=iris.data[:,2]
x4=iris.data[:,3]
x2_mean=x2.mean()
x2_sigma=x2.std()
x3_mean=x3.mean()
x3_sigma=x3.std()
x4_mean=x4.mean()
x4_sigma=x4.std()
x2_normal=norm.pdf(x1_range,x2_mean,x2_sigma)
x3_normal=norm.pdf(x1_range,x3_mean,x3_sigma)
x4_normal=norm.pdf(x1_range,x4_mean,x4_sigma)
#plt.plot(x1_range,x1_normal)
#plt.plot(x1_range,x2_normal)
#plt.plot(x1_range,x3_normal)
#plt.plot(x1_range,x4_normal)
clf=EllipticEnvelope()# conaminaion=0.1默认阈值
clf.fit(iris.data)
y_pre=clf.predict(iris.data)
zc=plt.scatter(iris.data[:,0][y_pre==1],iris.data[:,1][y_pre==1],marker="o")
yc=plt.scatter(iris.data[:,0][y_pre==-1],iris.data[:,1][y_pre==-1],marker="x")
plt.legend((zc,yc),("zc ","yc"))
print(y_pre,pd.value_counts(y_pre))
plt.show()
将异常点用X表示出来。效果如图(仅仅是第一二维度的值)

3 数据降维
在前面各种分析的时候,我们用的数据维度并不多,但是在一些实际问题中可能设计考虑的因素可能就比较多,这个时候就需要降低因素维度。
常见的数据降维方法有:
独立成分分析(ICA):ICA用于将混合信号分解为独立源信号,适用于音频信号处理、图像降噪等场景。
t-分布邻域嵌入(t-SNE):t-SNE适用于高维数据的可视化,通过保持数据点之间的相对距离关系,将高维空间中的数据映射到低维空间中。
自编码器(Autoencoder):自编码器是一种非线性降维方法,通过学习输入数据的压缩表示来进行降维,适用于深度学习领域。
奇异值分解(SVD):SVD通过分解矩阵的奇异值和奇异向量来进行降维,适用于图像处理和推荐系统。
多维缩放(MDS):MDS保持数据点之间的距离关系,适用于需要保持数据点之间相对距离的场景。
统一流形逼近和投影(UMAP):UMAP适用于处理复杂的高维数据,通过流形逼近技术进行降维。
ISOMAP:ISOMAP也是一种基于流形的降维方法,适用于具有复杂拓扑结构的高维数据。
核PCA(Kernel PCA):核PCA结合了PCA和核方法,适用于处理非线性关系的数据。
随机投影:随机投影通过随机生成投影矩阵进行降维,适用于大规模高维数据。
特征选择:特征选择通过选择最具代表性的特征进行降维,适用于处理具有冗余特征的数据集。
这些方法各有优缺点,适用于不同的数据类型和应用场景。选择合适的降维方法可以提高数据处理效率,减少计算资源的需求,并提升模型的性能。
在此主要介绍PCA(principal components analysis)即主成分分析技术,又称主分量分析,旨在利用降维的思想,把多指标转化为少数几个综合指标。其主要工作过程是
1)原始数据处理,需要将均值μ=0,σ=1
2)计算协方差矩阵特征向量、及数据在各特征向量投影后的方差
3)根据需求确定降维维度k
4)选取k维特征向量,计算数据在其形成空间的投影。
利用sklearn中提供的包可以比较方便的处理数据,降维等。
引入预处理包,from sklearn.preprocessing import StandardScaler
代码如下:
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from sklearn.cluster import KMeans
from sklearn.neighbors import KNeighborsClassifier
from sklearn.cluster import MeanShift,estimate_bandwidth
from sklearn import datasets
from sklearn import tree
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from scipy.stats import norm
from sklearn.covariance import EllipticEnvelope
iris=datasets.load_iris()
data=iris.data
km=KMeans(n_clusters=3,random_state=0)
km.fit(data)
km_yc=km.predict(data)
print(km_yc);
print(pd.value_counts(km_yc))
x_norm=StandardScaler().fit_transform(data)#将数据标准化
print(x_norm)
#对比标准化后的数据
fig1=plt.figure(figsize=(20,5))
plt.subplot(121)
plt.hist(data[:,0],bins=100)
plt.subplot(122)
plt.hist(x_norm[:,0],bins=100)
plt.show()处理后的数据对比如下图:
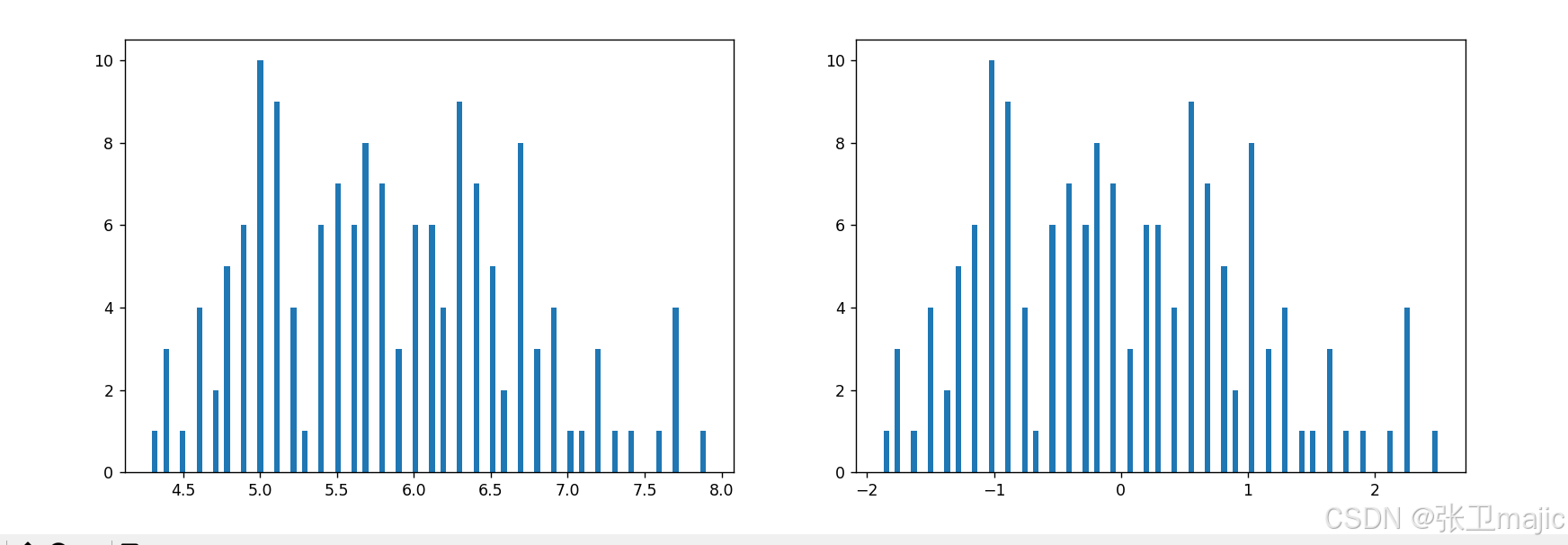
从途中可以看出处理后数据的均值为0,相当于标准化正态分布。
引入PCA包,from sklearn.decomposition import PCA,
通过pca包提供的数据变换,计算主要成分。
x_pca=pca.fit_transform(x_norm)
var_ratio=pca.explained_variance_ratio_
完整代码如下:
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from sklearn.cluster import KMeans
from sklearn.neighbors import KNeighborsClassifier
from sklearn.cluster import MeanShift,estimate_bandwidth
from sklearn import datasets
from sklearn import tree
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from scipy.stats import norm
from sklearn.covariance import EllipticEnvelope
iris=datasets.load_iris()
data=iris.data
km=KMeans(n_clusters=3,random_state=0)
km.fit(data)
km_yc=km.predict(data)
print(km_yc);
print(pd.value_counts(km_yc))
x_norm=StandardScaler().fit_transform(data)#将数据标准化
#对比标准化后的数据
fig1=plt.figure(figsize=(20,5))
plt.subplot(121)
plt.hist(data[:,0],bins=100)
plt.subplot(122)
plt.hist(x_norm[:,0],bins=100)
plt.show()
#PCA
pca=PCA(n_components=4)
x_pca=pca.fit_transform(x_norm)
var_ratio=pca.explained_variance_ratio_
plt.pie(var_ratio)
plt.show()
得到对比如下:
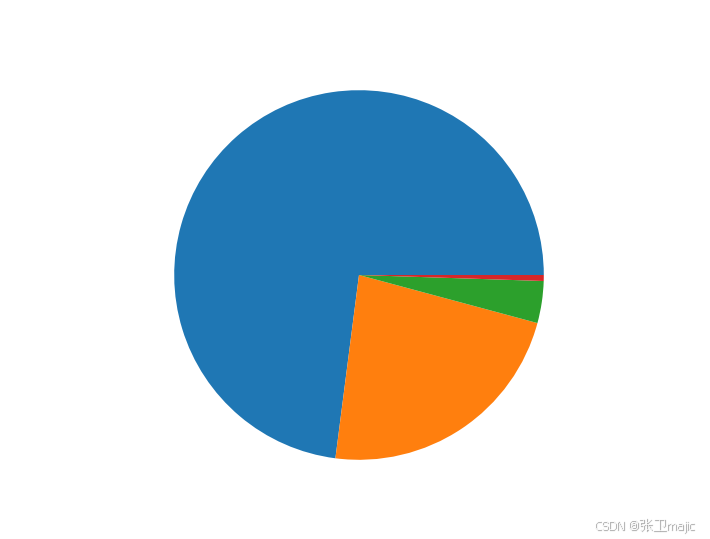
我们要选择方差比较大的因素。方差小证明相关性比较高,此处要比较差别大的。使用第一二个方差比较大的属性对iris进行分类。完整代码如下:
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from sklearn.cluster import KMeans
from sklearn.neighbors import KNeighborsClassifier
from sklearn.cluster import MeanShift,estimate_bandwidth
from sklearn import datasets
from sklearn import tree
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from scipy.stats import norm
from sklearn.covariance import EllipticEnvelope
iris=datasets.load_iris()
data=iris.data
km=KMeans(n_clusters=3,random_state=0)
km.fit(data)
km_yc=km.predict(data)
print(km_yc);
print(pd.value_counts(km_yc))
x_norm=StandardScaler().fit_transform(data)#将数据标准化
#对比标准化后的数据
fig1=plt.figure(figsize=(20,5))
plt.subplot(121)
plt.hist(data[:,0],bins=100)
plt.subplot(122)
plt.hist(x_norm[:,0],bins=100)
plt.show()
#PCA
pca=PCA(n_components=4)
x_pca=pca.fit_transform(x_norm)
var_ratio=pca.explained_variance_ratio_
lei1=plt.scatter(x_pca[:,0][km_yc==0],x_pca[:,1][km_yc==0])
lei2=plt.scatter(x_pca[:,0][km_yc==1],x_pca[:,1][km_yc==1])
lei3=plt.scatter(x_pca[:,0][km_yc==2],x_pca[:,1][km_yc==2])
plt.legend((lei1,lei2,lei3),('lei1','lei2','lei3'))
plt.show()上述代码分析效果如下:
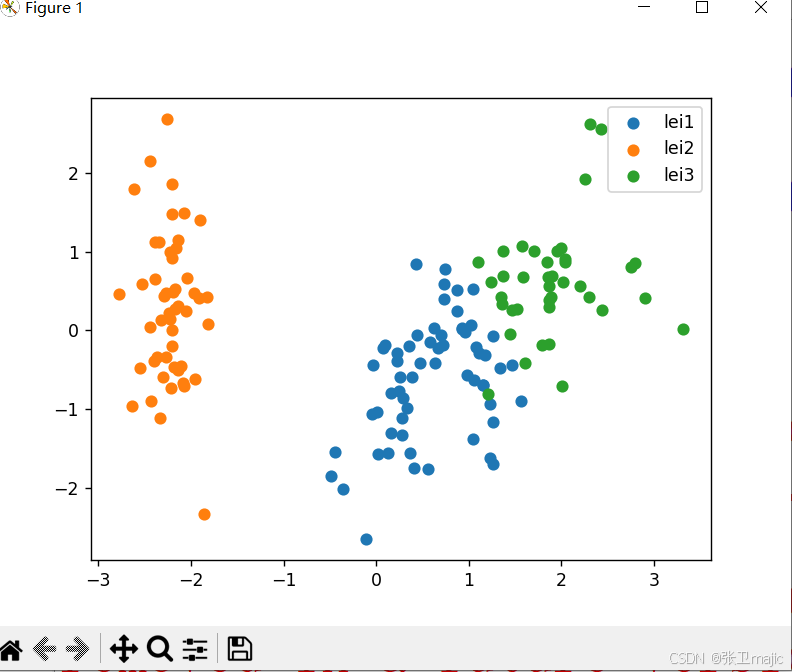
本次文章综合讲解了决策树,异常检测,数据降维等方法,三者综合起来对sklearn中iris数据集进行数据降维,验证异常点,并选出方差显著的第一二属性进行分类。最后代码可以完整演示。
未来一起努力,加油!感谢您的关注!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









