






1. 什么是小提琴图?
小提琴图,外层为核密度图,内层为箱线图。形似小提琴,故名小提琴图。是一种用来显示数据分布情况的统计图表。
外层核密度图:它用来显示数据的密度分布,像是一个平滑的直方图,能帮助我们看出数据的分布情况。轮廓宽的地方说明这个数值范围内的数据比较多,窄的地方则表示数据比较少。
内层箱线图:它展示了一组数据的五个统计特征:下限、第一四分位数(Q1)、中位数、第三四分位数(Q3)和上限。外面的黑点显示离群值的存在和分布情况。
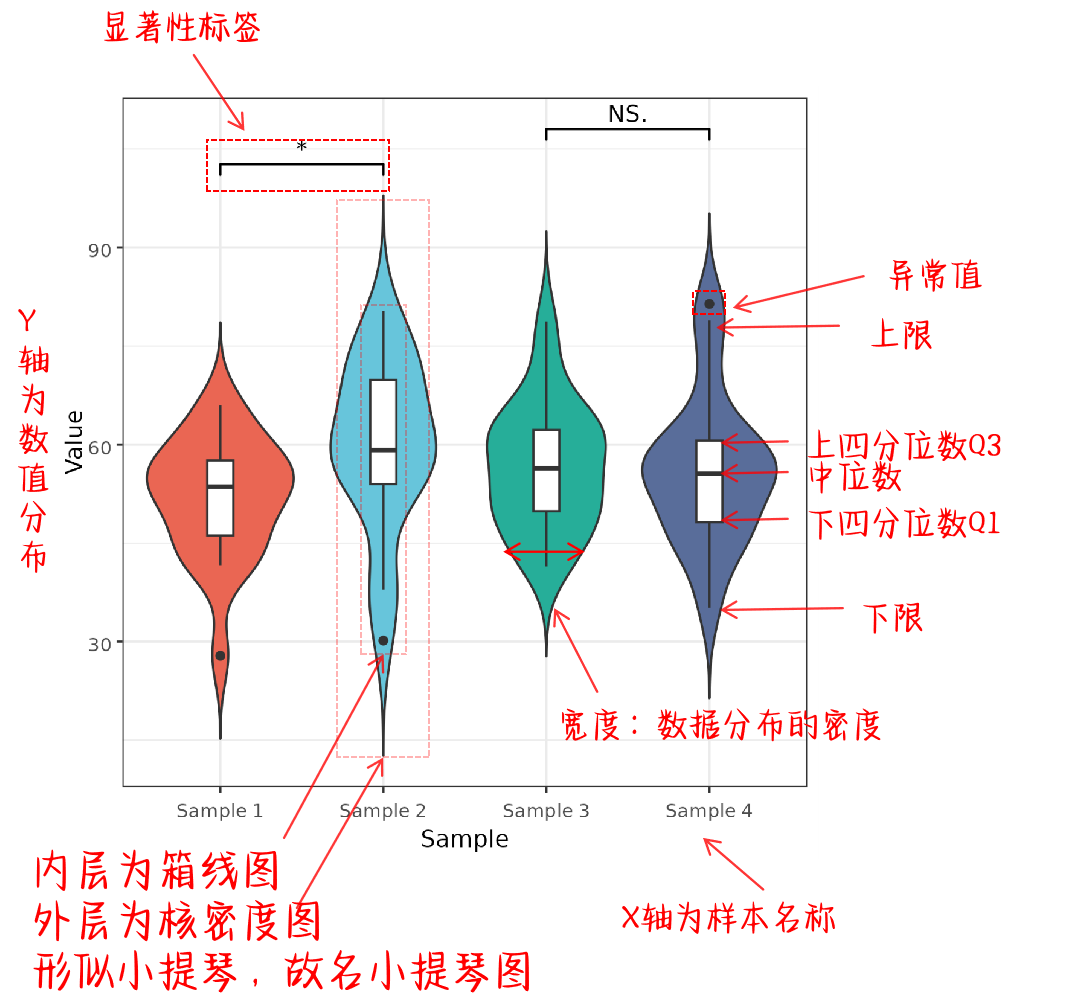
四分位数(quartile)是指在统计学中把所有数值由小到大排列并分成四等份,处于三个分割点位置的数值。四分位数也被称为四分位点,它是将全部数据分成相等的四部分,其中每部分包括 25%的数据,处在各分位点的数值就是四分位数。四分位数有三个,第一个四分位数是下四分位数,第二个四分位数就是中位数,第三个四分位数称为上四分位数,分别用 Q1、Q2、Q3表示
四分位距IQR:是Q3-Q1,也就是说上下四分位数的差值。
上下限:上下限并不是整个数据样本的最大值和最小值,而是上限 = 去除异常值的最大值(Q3+1.5IQR)和下限 = 去除异常值的最小值(Q1-1.5IQR) ,在上下限这里分别划出两条线段作为异常值的分界点。
那么在箱线图中,上下限之间就是数据样本的正常分布区间,超出上下限就定义为异常值。
显著性标签:常用来标注不同组之间的统计显著性差异。这些标签通常是通过统计测试(如 t 检验、ANOVA 等)得到的结果,表示不同组之间是否存在显著差异。显著性标签通常表现为星号(*)或者字母标记等,常见的规则如下:* (p < 0.05)表示显著差异。NS.表示不显著差异。
2. 绘图的数据准备
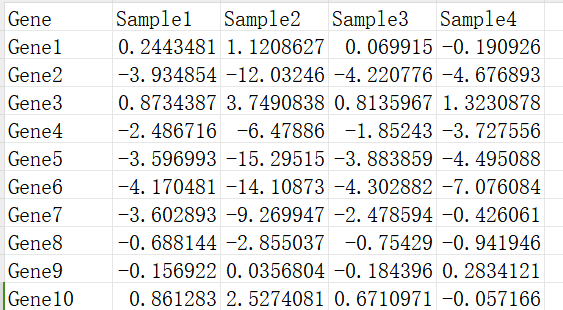
包含2个维度的数据,在组学数据中通常每一列是个样本,每一行是个基因。
注意受到数据中极大值的影响,箱线图可能会被压的很扁,可以做log转换或其他归一化方式。
示例数据可以在https://www.bioladder.cn/web/demoData.xlsx找到并下载。
3. 绘制小提琴图的方法
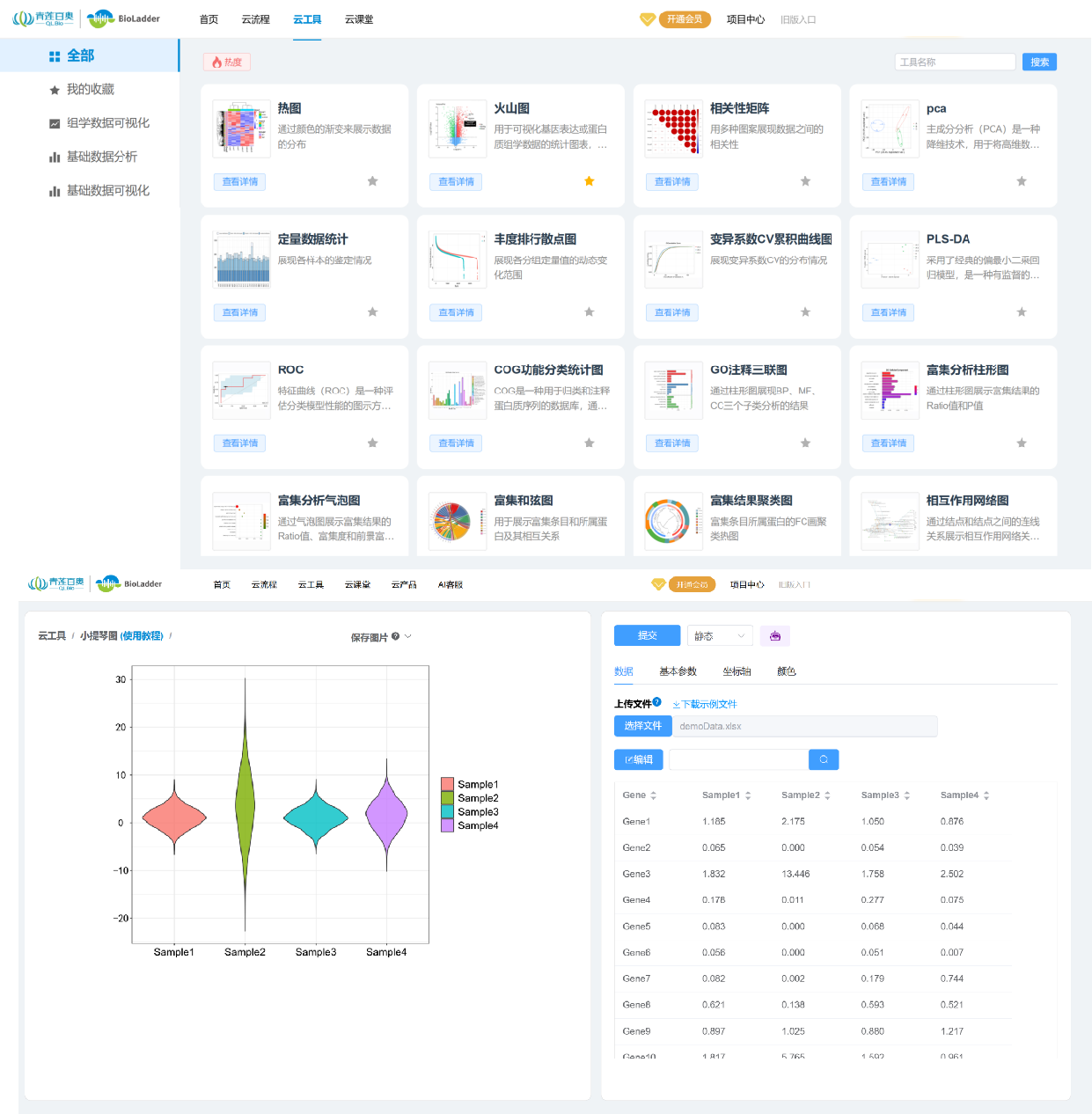
3.1. BioLadder v2.0 云平台在线绘图
BioLadder v2.0 是一个在线绘图平台,我们只需要上传数据,系统自动生成图表,不需要写代码,适合0代码基础的同学。网址:BioLadder v2.0-生物信息在线分析云平台
3.2. R语言绘制小提琴图
喜欢自己写代码的同学,也附上R语言代码可供参考。
3.2.1. 绘图
# 代码来源:https://www.r2omics.cn/
# 加载R包,没有安装请先安装 install.packages("包名")
library(tidyverse)
# 读取箱线图数据文件
df = read.delim("https://www.r2omics.cn/res/demodata/boxplot.txt",# 将此处换成你自己电脑里的文件
header = T # 指定第一行是列名
)
# 把数据转换成ggplot常用的类型(长数据)
df = df %>%
pivot_longer(-1,names_to = "Sample",values_to = "Value")
# 绘图
p = ggplot(df,aes(x=Sample,y=Value,fill=Sample))+
# stat_boxplot(geom = "errorbar", # 添加误差线
# width=0.3)+
geom_violin(alpha = 1, # 透明度
trim = T, # 是否修剪尾巴,即将数据控制到真实的数据范围内
scale = "count", # 如果“area”(默认),所有小提琴都有相同的面积(在修剪尾巴之前)。如果是“count”,区域与观测的数量成比例。如果是“width”,所有的小提琴都有相同的最大宽度。
)+
theme_bw()+ # 主题
theme(
axis.text.x = element_text(angle = 90,
vjust = 0.5
) # x轴刻度改为倾斜90度,防止名称重叠
)
p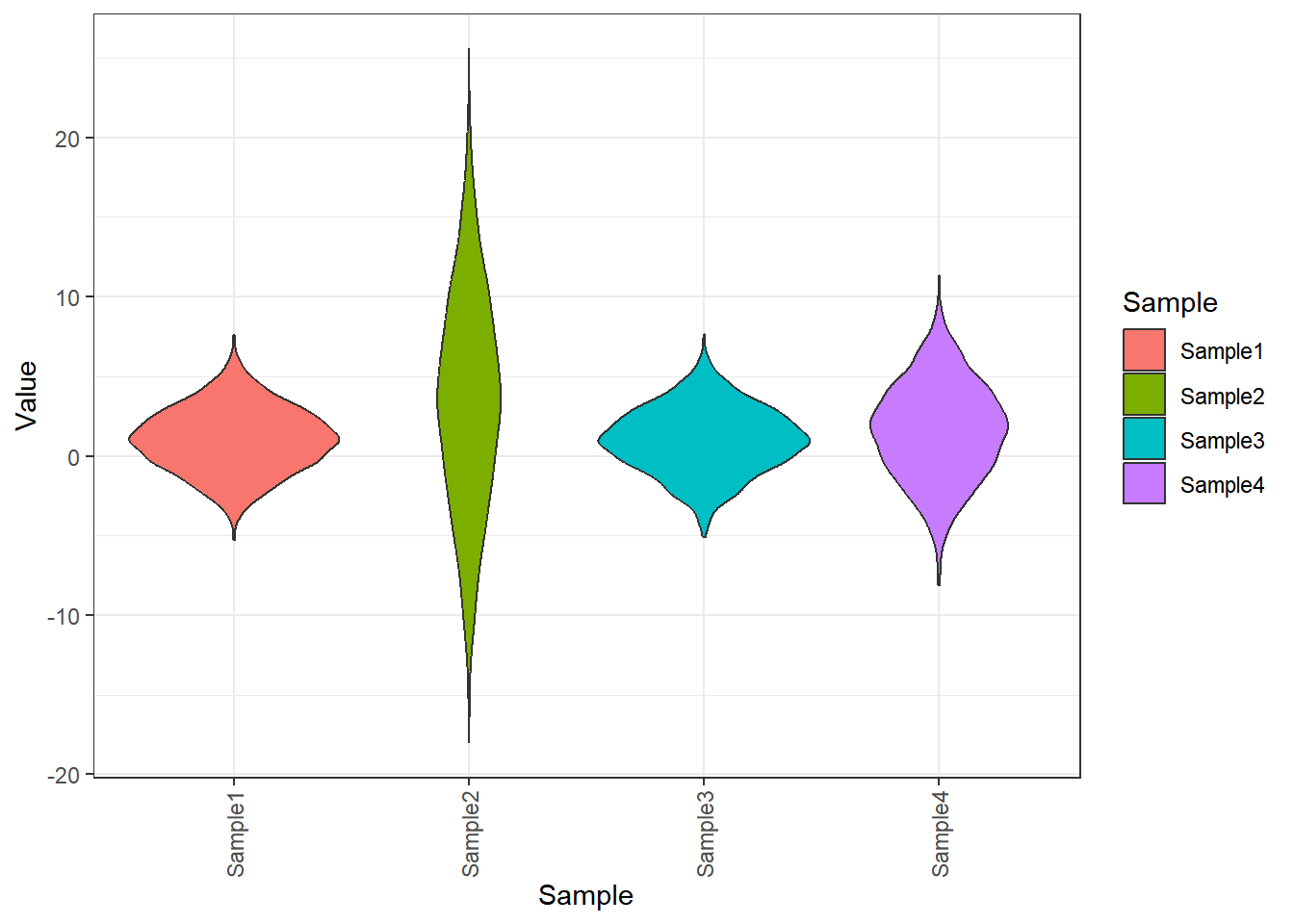
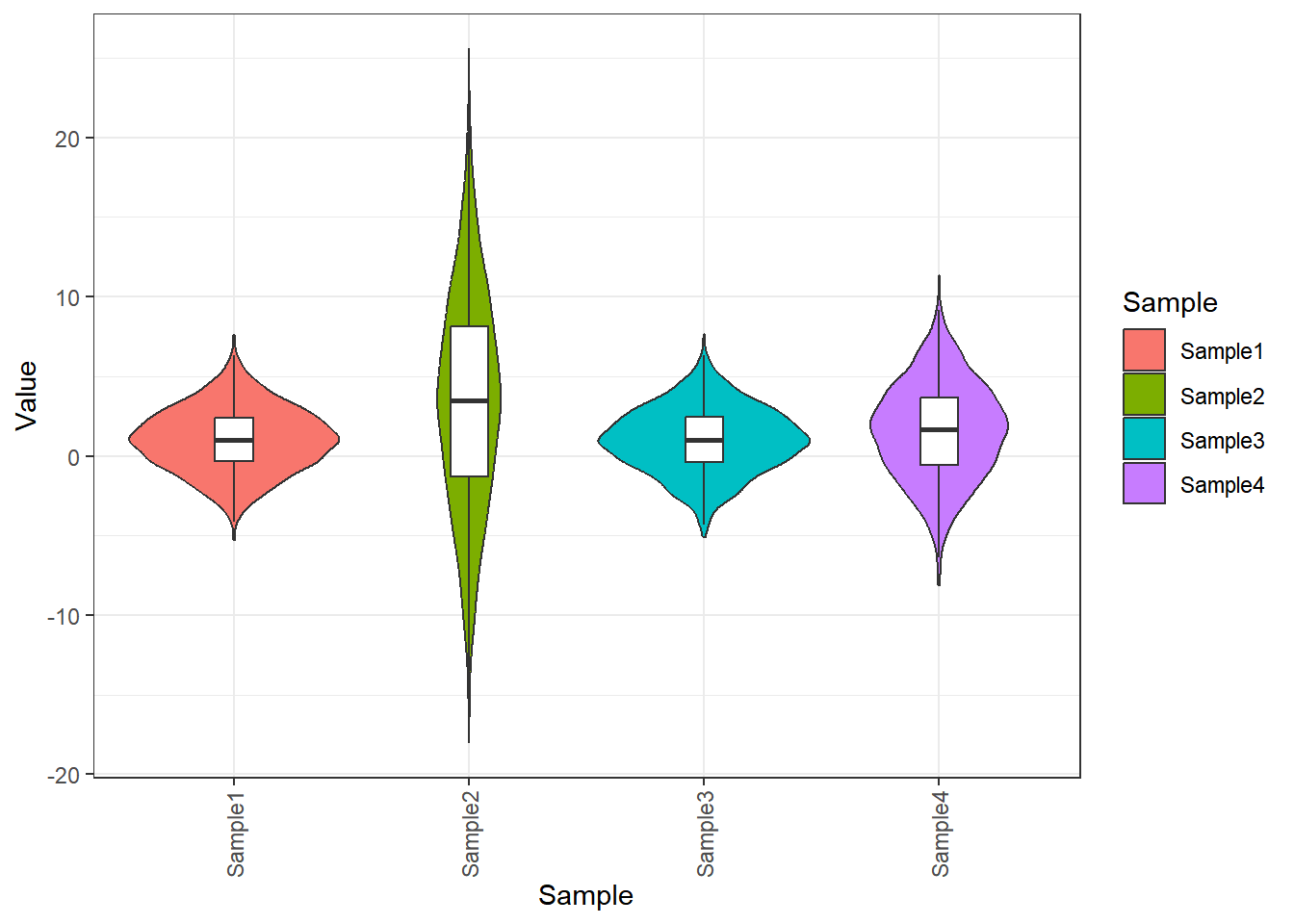
3.2.2. 箱线图和小提琴图合并
# 其实就是在小提琴的图层下再画一个箱线图
p +
geom_boxplot(width=0.16,
fill="white",
outlier.alpha = 0
)
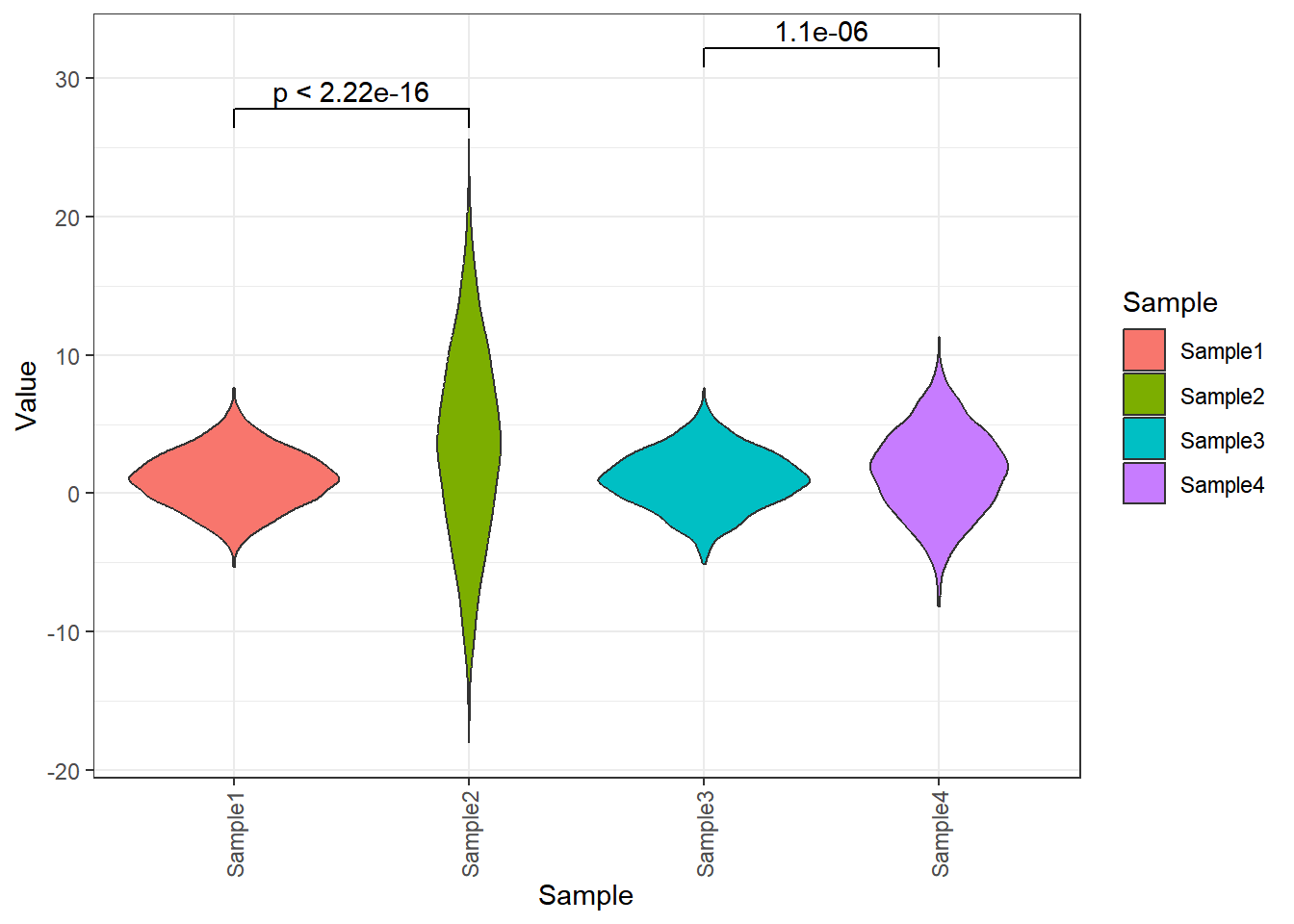
3.2.3. 添加显著性标签
library(ggsignif) # 用于添加显著性标签
p + geom_signif( # 添加显著性标签
comparisons=list(c("Sample1","Sample2"),c("Sample3","Sample4")), # 选择你想在哪组上添加标签
step_increase = 0.1,
test="t.test", # "t 检验,比较两组(参数)" = "t.test","Wilcoxon 符号秩检验,比较两组(非参数)" = "wilcox.test"
test.args = list("var.equal" = T), # 等方差
map_signif_level=F # 标签样式F为数字,T为*号
)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









