






1.需求
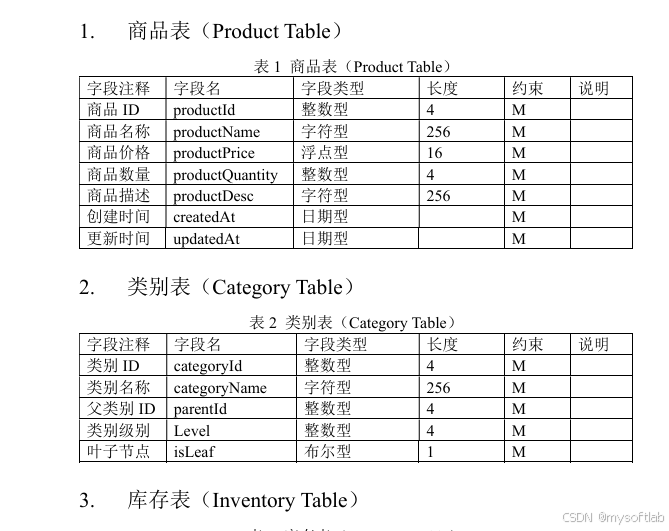
最近客户接到一个任务,需要编写一份标准接口文档,任务发起方给到客户一个PDF文件,文件里面有好几十个大表,每个表字段都不少,最少的表字段数超过20个,最长的字段数超过50个,任务发起方要求给这些表都编写一个接口调用示例,生成接口数据Json串,将这些数据库表字段名为key,然后按照实际业务填充Value。由于客户那边人比较少,他们觉得工作量巨大,因此就将这个任务甩给了我们,谁让我们是供应商呢,脏活苦活都得我们干。我一看文档头都大了,这么多表,一个一个复制粘贴,得啥时候能整完,而且复制粘贴的过程中难免会出错,因此我想通过技术手段来完成这个任务,因此就有了此文。出于商业保密,文中用到的PDF文件都是我自己编写的测试文件,测试文件内容是这样的:
2.技术路线
首先想到的是直接使用开源PDF库去读取PDF文件,但是试验了一下,这些开源的PDF库都无法识别表格数据,如果要基于规则自己去解析,那肯定慢且低效。搜索了一圈,C#生态圈都没有比较好的解决方案。
后来转变思路,先使用工具将PDF转换为WORD文档,然后再使用开源库去读取WORD文档中的表格,那就容易得多了。PDF转WORD文档的工具很多,在线转换的和收费的都很多,由于PDF文档数据涉及到客户的商业机密,因此网上的在线PDF转换网站肯定是不能用了,百度网盘提供这个功能,不过需要开通会员,而且也有保密的问题,后面通过搜索发现了python有一个很好用的开源工具pdf2docx,使用这个工具就可以将PDF转换为DOCX了,注意该开源工具使用的是AGPL授权,因此无法基于商业目的使用。
现在WORD文件有了,我们需要一个C#的库来读取WORD文档中的表格,这里我推荐使用NPOI,NPOI是Java版POI的翻译版本,是一个非常流行的C# Excel和WORD操作工具库。
3.实现细节
3.1 PDF转DOCX
如果你没有使用过python,那么建议你先安装一下python环境,需要自行搜索,网上有很多教程。如果你已经安装了python环境,那么直接运行以下命令即可安装pdf2docx:
pip install pdf2docx
如果大家python使用比较多,建议大家使用miniconda来管理多个python环境,如果你是用miniconda或者conda进行安装的,在使用pdf2docx工具时,一定要激活安装pdf2docx时的虚拟环境,我这里就是因为时间太长了,忘了在哪个环境安装的导致命令出错:

切换一下环境就好了:
conda activate Excel
再次运行:
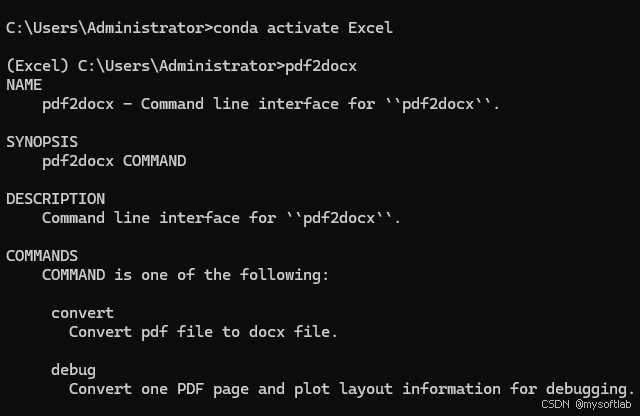
可以正常识别pdf2docx命令了,我们使用以下命令来将pdf转换为docx:
pdf2docx convert test.pdf test.docx --start=0 --end=1
我们使用pdf2docx的convert命令,第一个参数是待转换的pdf名称,第二个参数是转换输出的docx的名称,第三个参数–start是指定转换的起始页索引,–end是转换结束的结束页索引,注意运行这个程序需要将控制台的工作目录切换到pdf所在的文件夹,运行结果如下:
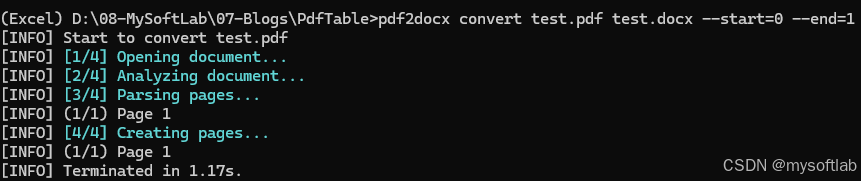
由于我们测试PDF文件比较小,所以转换很快就完成了,如果你的PDF页码很多,结构复杂,整个转换过程可能持续好几分钟,客户给到的PDF转换时间就1分多钟。看一下转换后的docx文件:

3.2 DOCX文件表格提取
对于docx文件内的表格提取,我们使用NPOI库来完成,解析时我们需要格外注意有的表格不在单个页面,而是分布在两个页面甚至是多个页面,因此我们需要判断表格是否有表头来决定解析的这个表格是需要追加到上个表格还是新生成一个表格,解析相关代码如下:
internal class Program
{
/// <summary>
/// 上次解析后的表格
/// </summary>
static ParsedTable _lastTable;
/// <summary>
/// 所有解析后的表格List
/// </summary>
static List<ParsedTable> _parsedTables = new List<ParsedTable>();
/// <summary>
/// 判断表格是否有表头
/// </summary>
/// <param name="table">表格</param>
/// <returns></returns>
static bool HasTableHeader(XWPFTable table)
{
if(table.Rows.Count > 0)
{
var headerRow = table.Rows[0];
var cells = headerRow.GetTableCells();
if(cells.Count > 2)
{
var firstCellText = cells[0].GetText().Trim();
var secondCellText = cells[1].GetText().Trim();
if(firstCellText.Contains("字段注释") && secondCellText.Contains("字段名"))
{
return true;
}
}
}
return false;
}
/// <summary>
/// 解析一行
/// </summary>
/// <param name="row"></param>
/// <returns></returns>
static ParsedRow ParseRow(XWPFTableRow row)
{
var cells = row.GetTableCells();
var commentCell = cells[0].GetText().Trim();
var nameCell = cells[1].GetText().Trim();
var typeCell = cells[2].GetText().Trim();
var lenCell = cells[3].GetText().Trim();
var constrainCell = cells[4].GetText().Trim();
var descCell = cells[5].GetText().Trim();
if(string.IsNullOrEmpty(nameCell))
{
return null;
}
return new ParsedRow()
{
FieldComment = commentCell,
FieldName = nameCell,
FieldType = typeCell,
FieldLength = lenCell,
Constrain = constrainCell,
Description = descCell
};
}
/// <summary>
/// 解析给定的表格所有行
/// </summary>
/// <param name="table"></param>
/// <param name="startIndex"></param>
/// <returns></returns>
static ParsedRow[] ParseAllRows(XWPFTable table, int startIndex)
{
List<ParsedRow> parsedRows = new List<ParsedRow>();
var rows = table.Rows.Skip(startIndex).ToArray();
foreach (var row in rows)
{
var parsedRow = ParseRow(row);
if(parsedRow != null)
{
parsedRows.Add(parsedRow);
}
}
return parsedRows.ToArray();
}
static void ParseTable(XWPFTable table)
{
bool hasHeader = HasTableHeader(table);
if (hasHeader)
{
// 新的表格
var parsedTable = new ParsedTable();
// 解析所有行
parsedTable.AppendRows(ParseAllRows(table, 1));
_parsedTables.Add(parsedTable);
_lastTable = parsedTable;
}
else
{
// 上次未解析完遗留的表格
var parsedRows = ParseAllRows(table, 0);
_lastTable.AppendRows(parsedRows);
}
}
/// <summary>
/// 判断表格是否合法
/// </summary>
/// <param name="table"></param>
/// <returns></returns>
static bool CheckTableValid(XWPFTable table)
{
if(table.Rows.Count == 0)
{
return false;
}
var firstRow = table.Rows[0];
return firstRow.GetTableCells().Count == 6;
}
static void Main(string[] args)
{
using (var fs = new FileStream("test.docx", FileMode.Open, FileAccess.Read))
{
XWPFDocument doc = new XWPFDocument(fs);
// 获取所有表格
var tables = doc.Tables;
foreach (var table in tables)
{
// 首先判断table是否合法
if(CheckTableValid(table))
{
ParseTable(table);
}
}
foreach (var table in _parsedTables)
{
Console.WriteLine(table.ToJson());
Console.WriteLine("=====================================");
}
}
}
}
ParsedRow类的定义如下:
/// <summary>
/// 解析后的行
/// </summary>
public class ParsedRow
{
/// <summary>
/// 字段注释
/// </summary>
public string FieldComment { get; set; }
/// <summary>
/// 字段名
/// </summary>
public string FieldName { get; set; }
/// <summary>
/// 字段类型
/// </summary>
public string FieldType { get; set; }
/// <summary>
/// 长度
/// </summary>
public string FieldLength { get; set; }
/// <summary>
/// 约束
/// </summary>
public string Constrain { get; set; }
/// <summary>
/// 说明
/// </summary>
public string Description { get; set; }
}
ParsedTable类定义如下:
/// <summary>
/// 解析后的表格
/// </summary>
internal class ParsedTable
{
/// <summary>
/// 解析完的行
/// </summary>
public List<ParsedRow> Rows { get; set; } = new List<ParsedRow>();
/// <summary>
/// 追加解析完毕的行
/// </summary>
/// <param name="rows"></param>
public void AppendRows(ParsedRow[] rows)
{
Rows.AddRange(rows);
}
public string ToJson()
{
JObject keyValuePairs = new JObject();
foreach (var row in Rows)
{
if(row.FieldType == "字符型")
{
keyValuePairs.Add(row.FieldName, "");
}
else if(row.FieldType == "日期型")
{
keyValuePairs.Add(row.FieldName, "2024-11-18 00:00:00");
}
else if(row.FieldType == "浮点型")
{
keyValuePairs.Add(row.FieldName, 0.0);
}
else if (row.FieldType == "整数型")
{
keyValuePairs.Add(row.FieldName, 0);
}
else
{
keyValuePairs.Add(row.FieldName, "");
}
}
return JsonConvert.SerializeObject(keyValuePairs, Formatting.Indented);
}
}
3.3 Json串生成
Json串生成,使用Newtonsoft.Json库来输出json串,在ParsedTable编写一个ToJson函数,将解析得到的表格按照客户需求转换为Json字符串,以下是程序最终运行控制台输出的Json串:
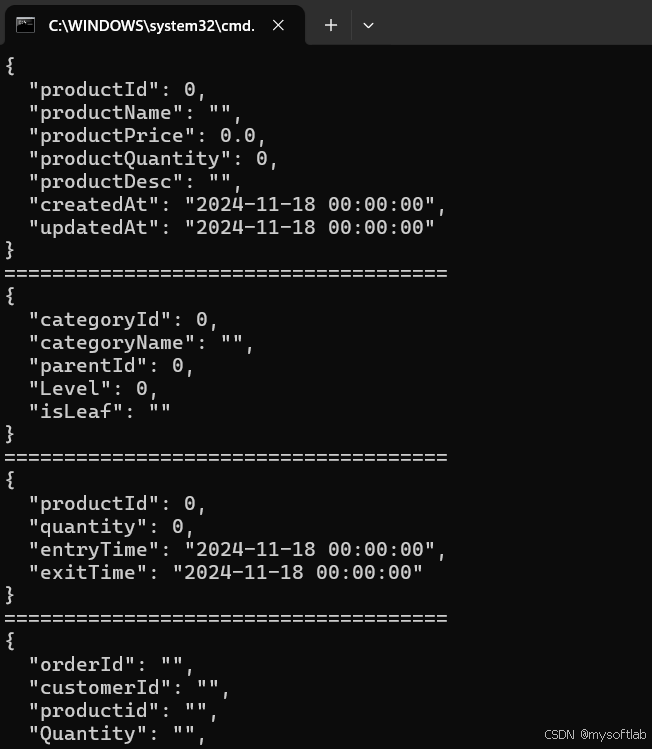
后续将每个表生成一个json文件,打包并发送给客户,客户自己再填充业务数据,至此,任务完成。
4.总结
本文提出了一种C#提取PDF中表格的思路,并给出具体实现代码,在实际使用过程中,可能需要对其中的一些代码进行微调,希望本文相关工作能够帮到大家,提高大家工作效率。

















 1659
1659

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









