






排序算法的概念
-
排序的概念
排序是计算机内经常进行的一种操作,其目的是将一组“无序”的记录序列调整为“有序”的记录序列。可以将数据按某字段规律排列,所谓的字段就是数据节点的其中一个属性。比如一个班级的学生,其字段就包含学号、姓名、班级、分数等等,我们既可以针对学号排序,也可以针对分数排序。
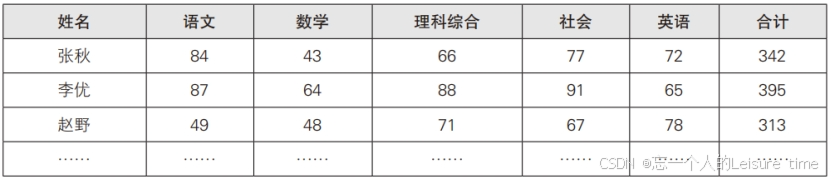
比如上图是某一次模拟考试的成绩表,老师要想知道考生的各科排名和综合排名,就需要按照各科成绩和总成绩的高低顺序对各行数据进行排列。
-
稳定性说明
排序算法的稳定性是指在待排序的记录序列中如果存在多个具有相同的关键字记录,排序前和排序后这些关键字的相对位置如果没有发生变化,则说明算法是稳定的,否则就说明算法是不稳定的。
比如原序列中存在r[i] = r[j],且r[i]的位置在r[j]之前,而在排序后的序列中,r[i]的位置仍在r[j]之前,则称这种排序算法是稳定的。
注意:如果一个序列中的关键字都是不重复的,则排序的结果就是唯一的,那么排序算法的稳定性就无关紧要,但是如果一个序列中的关键字可以重复的话,则需要根据具体需求来考虑选择稳定的或者不稳定的算法。
排序算法的种类
根据不同的设计思想可以把算法分为很多种,常见的有插入类、交换类、以及选择类三种。
插入类排序
插入类排序是指在一个已经排好序的序列中插入一个新元素,也就是从一个未排序的无序序列中取出一个元素,然后插入到已经排好序的序列中,直到所有的元素都插入完成,就得到了一个新的有序序列,常见的插入类排序算法有:直接插入排序。

比如上图中四位小朋友打算排队坐车,此时老师要求大家按照身高有序排队,此时小明、小亮、小雷已经排好队,但是小美来晚了一会,由于小美的身高比小亮高,但是比小雷低,所以小美需要插入到小亮的身后,此时就形成一个新的有序序列。
交换类排序
交换类排序算法的核心是“
交换”,也就是每一轮排序都是通过一系列交换动作实现的,最终让元素排列到合适的位置上。常见的交换类排序算法有:冒泡排序、快速排序。
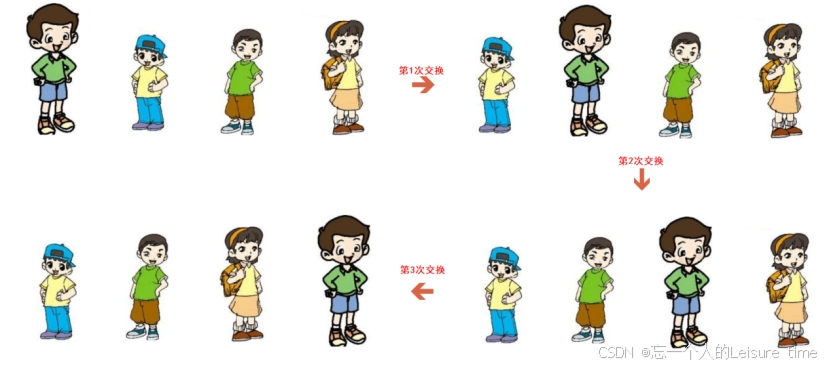
比如上图中四位小朋友打算排队坐车,此时小雷、小明、小亮、小美已经排好队,此时老师发现队列不整齐,老师观察到小雷的身高比小明高,所以要求小雷和小明的位置互换一下,然后老师又发现小雷的身高也比小亮高,所以要求小雷和小亮的位置互换一下,然后老师又发现小雷的身高也比小美高,所以要求小雷和小美的位置互换一下,这样一轮排序后,可以发现身高最高的小雷已经排在队伍的最后面,只要再经过几轮,就可以让整个队伍变得有序。
选择类排序
选择类排序算法的核心是“
选择”,也就是每一轮排序中都选出最小(最大)的元素,然后和序列的第一个元素的位置进行互换,这样最小的元素就到达指定位置,经过n轮后,就可以得到一个有序的序列。常见的选择类排序算法有:选择排序。
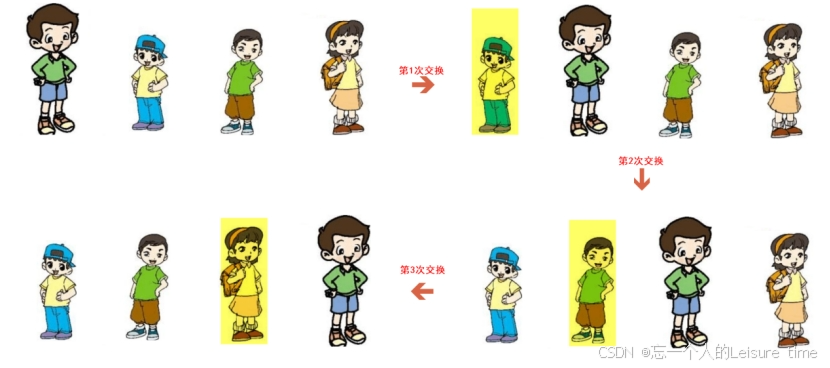
比如上图中四位小朋友打算排队坐车,此时小雷、小明、小亮、小美已经排好队,此时老师发现队列不整齐,老师观察到小明的身高最低,所以要求小明排在队伍的第一位,所以小雷和小明的位置互换一下,然后老师发现剩下的队伍中小亮的身高最低,所以小亮和队伍的第二位的位置互换一下,然后老师又发现剩下的队伍中小美的身高最低,所以小美和队伍的第三位的位置互换一下,这样n轮排序后,就可以让整个队伍变得有序。
-
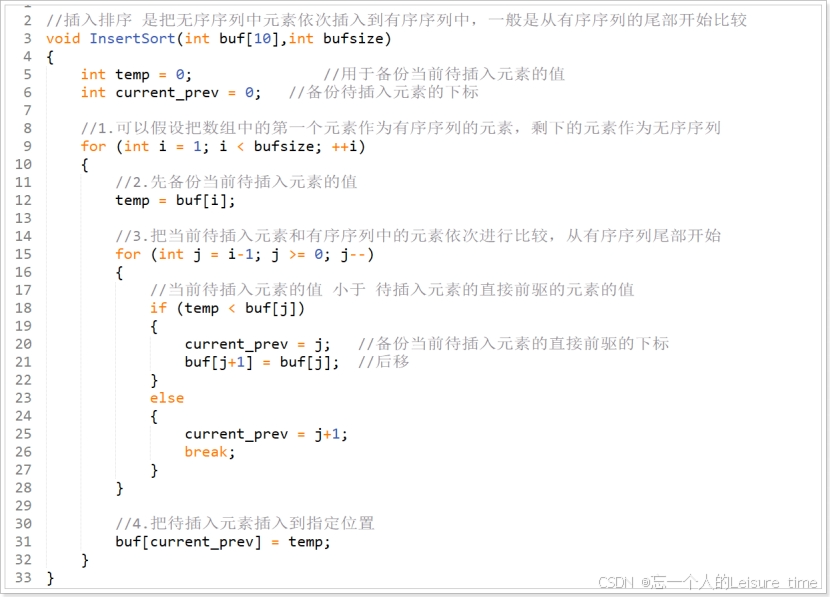
插入排序
插入排序是一种简单快速的排序算法,就是把一组无序的数据,以第一个数据为准,假设第一个数据是经过排序过的,把第二个数据和排好的数据进行比较,注意插入排序是从后向前进行比较,如果此时有一个新元素,则从已经排序的序列的尾部向前进行比较,如果排序过的序列的元素值大于新元素,则把新元素插入到该元素的前面。
插入排序的思路就是从右侧的未排序区域内取出一个数据,然后将它插入到已排序区域内合适的位置上。
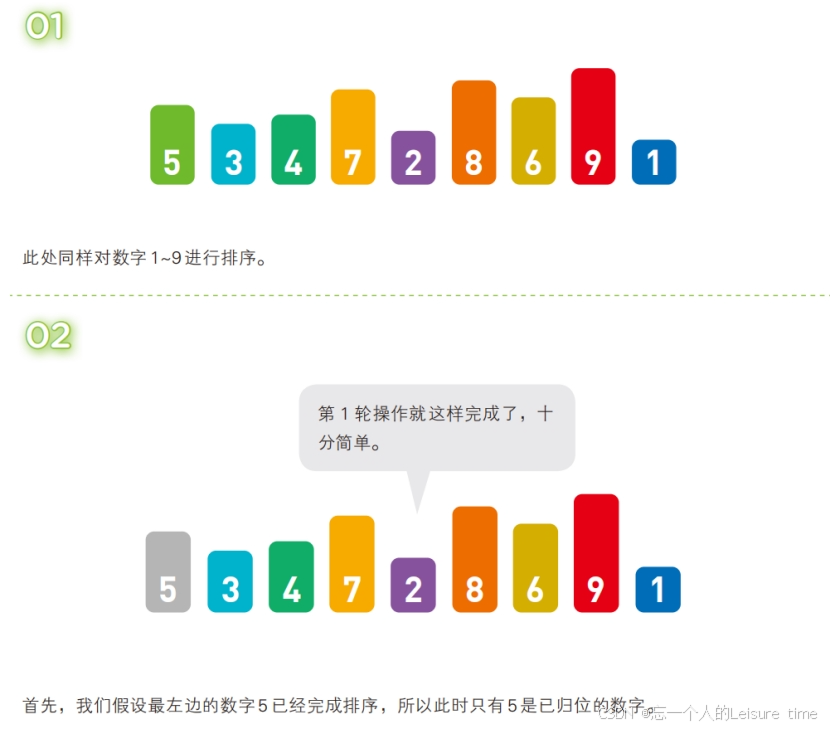
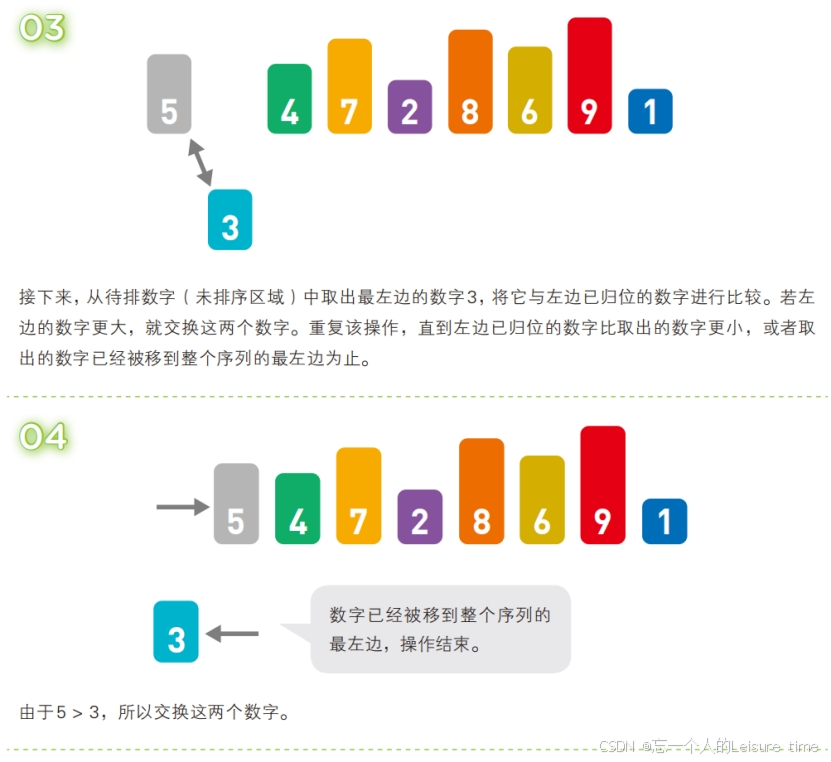

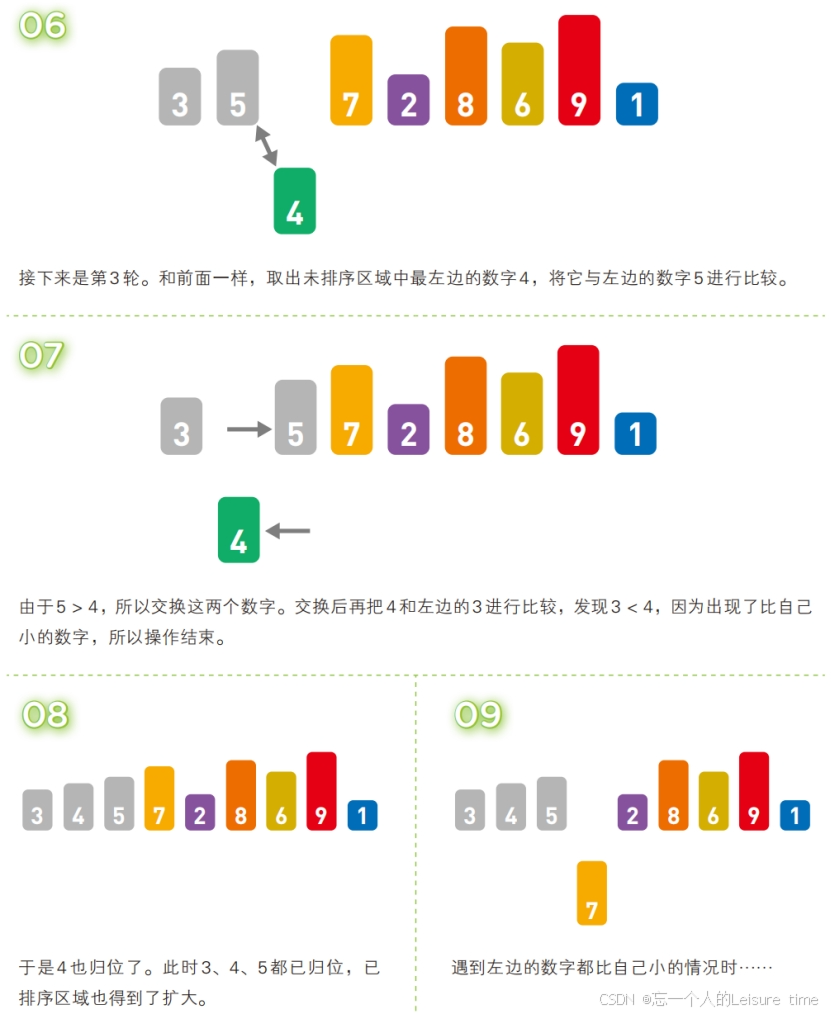
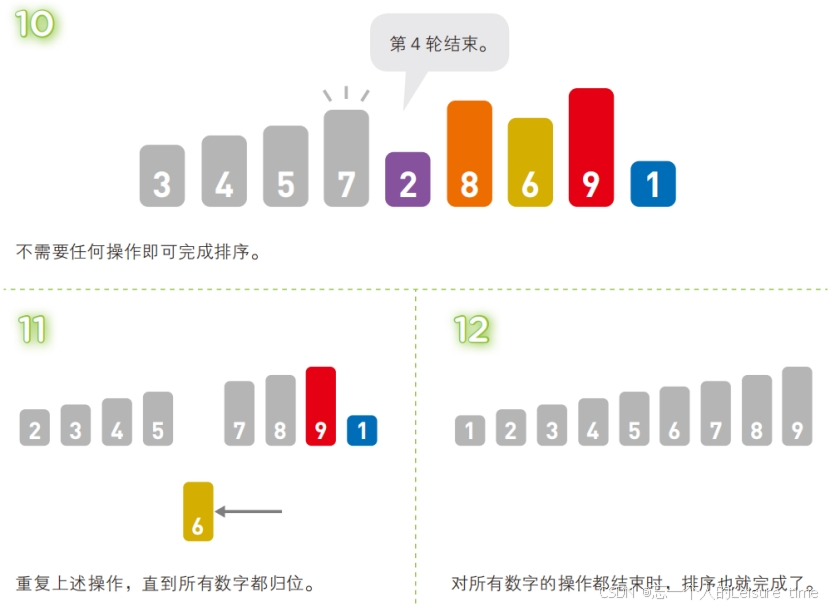
在插入排序中,需要将取出的数据与其左边的数字进行比较。就跟前面讲的步骤一样,如果左边的数字更小,就不需要继续比较,本轮操作到此结束,自然也不需要交换数字的位置。
然而,如果取出的数字比左边已归位的数字都要小,就必须不停地比较大小,交换数字,直到它到达整个序列的最左边为止。具体来说,就是第 k 轮需要比较 k - 1 次。因此,在最糟糕的情况下,第 2 轮需要操作 1 次,第 3 轮操作 2 次……第 n 轮操作 n - 1 次,所以插入排序的最坏时间复杂度为 O(n2 ),也就是当序列的元素是按照从大到小输入的情况,所以直接插入排序算法适合序列基本有序的情景。
笔试题:设计一个程序,要求用户通过键盘依次输入10个随机整数,然后利用插入排序实现整数序列的升序排列,使用数组实现即可。
除了可以手动输入随机数之外,还可以使用系统函数srand()和rand()函数自动生成随机数。

srand函数和rand函数是C语言中的随机数生成函数,其中srand函数用于初始化随机数种子,而rand函数用于生成随机数。下面是一个生成10个随机数的程序:
#include
#include
#include
int main()
{
int i;
// 初始化随机数种子
srand(time(NULL));
// 生成10个随机数并输出
for (i = 0; i < 10; i++) {
printf("%d ", rand());
}
printf("\n");
return 0;
}
在程序中,我们使用了time函数获取当前时间作为随机数种子,然后将其传递给srand函数进行初始化。接着,我们使用for循环生成10个随机数,并使用printf函数输出。注意,由于rand函数生成的随机数范围比较大,因此我们使用%d格式控制符将其转换为整数输出。
如果打算生成在某些范围内的随机数,则只需要把rand函数每次生成的随机数对指定范围求余即可,比如生成10个在0~99范围的随机数,则程序如下:
#include
#include
#include
int main()
{
int i;
// 初始化随机数种子
srand(time(NULL));
// 生成10个随机数并输出
for (i = 0; i < 10; i++) {
printf("%d ",
rand()
%100); //生成的随机值对100求余的结果就是在0~99范围内
}
printf("\n");
return 0;
}
-
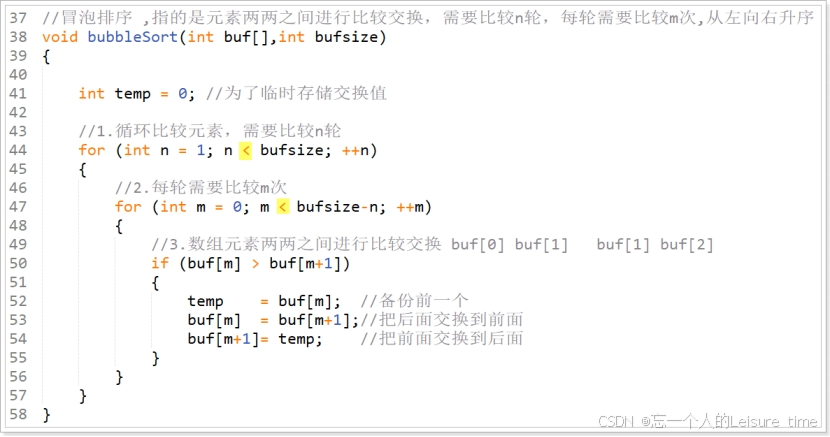
冒泡排序
冒泡排序也被称为起泡排序,该排序算法的原理就是经过一系列的
交换实现的,也就是用第一个元素和第二个元素进行比较,如果第一个元素的值大于第二个元素则两者位置互换,否则不交换。然后第二个元素和第三个元素比较.......最后序列中最大的元素被交换到了序列的尾部,这样就完成了一轮交换,经过n轮交换之后,就可以得到一个有序序列。
当然,除了从左向右交换的方案外,另外一种冒泡排序就是重复“从序列右边开始比较相邻两个数字的大小,再根据结果交换两个数字的位置”这一操作的算法,也就是从右往左交换。在这个过程中,数字会像泡泡一样,慢慢从右往左“浮”到序列的顶端,所以这个算法才被称为“冒泡排序”。

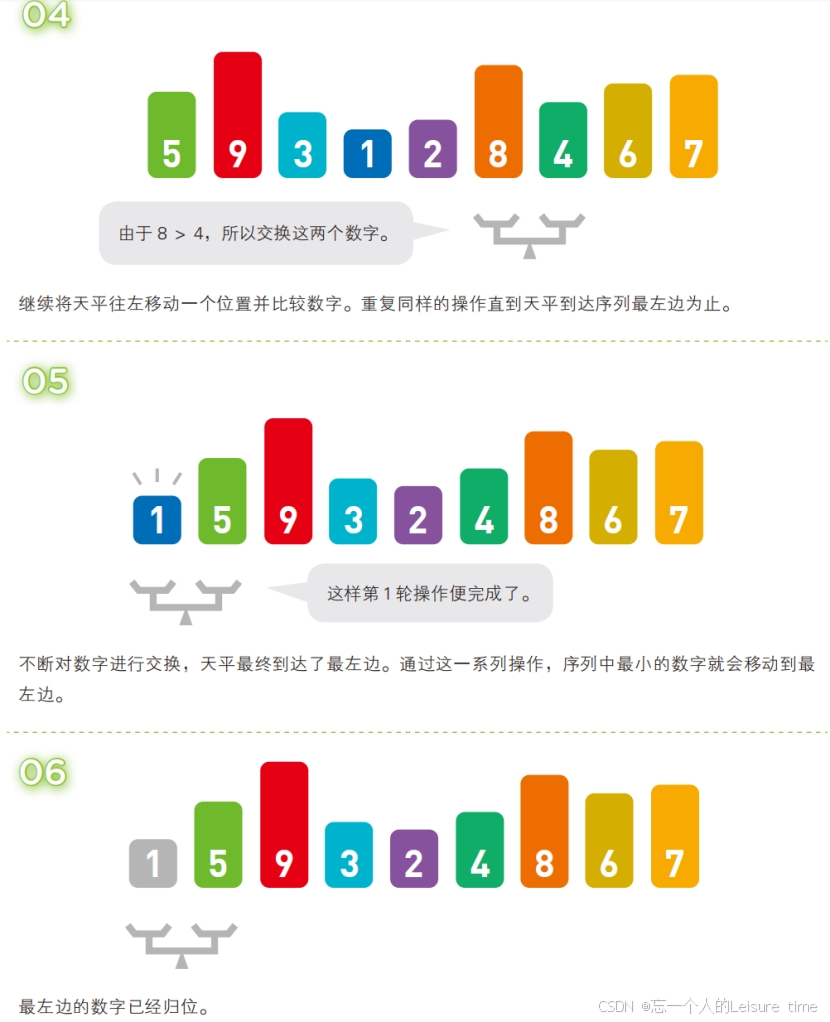
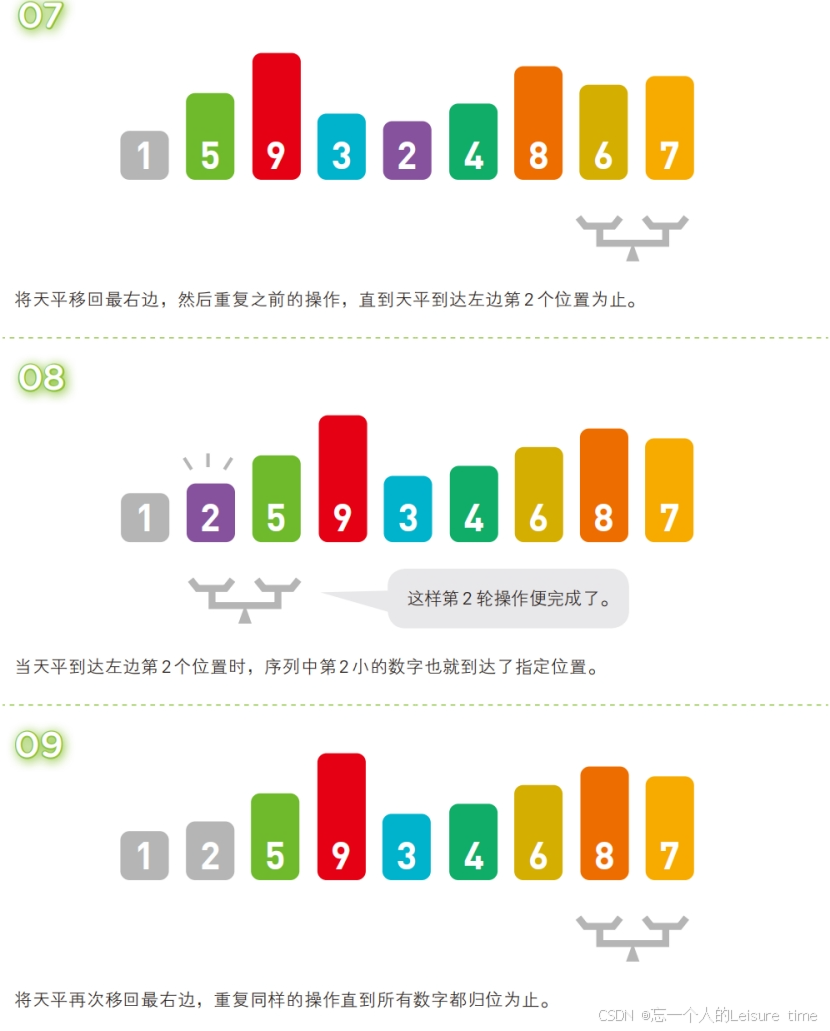

在冒泡排序中,第 1 轮需要比较 n - 1 次,第 2 轮需要比较 n - 2 次……第 n - 1 轮需要比较 1 次。因此总的比较次数为 (n - 1) +(n - 2) +…+1 ≈ n2 /2。这个比较次数恒定为该数值,和输入数据的排列顺序无关。
不过,交换数字的次数和输入数据的排列顺序有关。假设出现某种极端情况,如输入数据正好以从小到大的顺序排列,那么便不需要任何交换操作;反过来,输入数据要是以从大到小的顺序排列,那么每次比较数字后都要进行交换。因此,冒泡排序的时间复杂度为 O(n2)。
注意:设计冒泡排序算法的时候排序结束的条件应该是一轮排序过程中没有发生元素交换。
练习:设计一个程序,要求用户通过键盘依次输入10个随机整数,然后利用冒泡排序实现整数序列的升序排列。
-
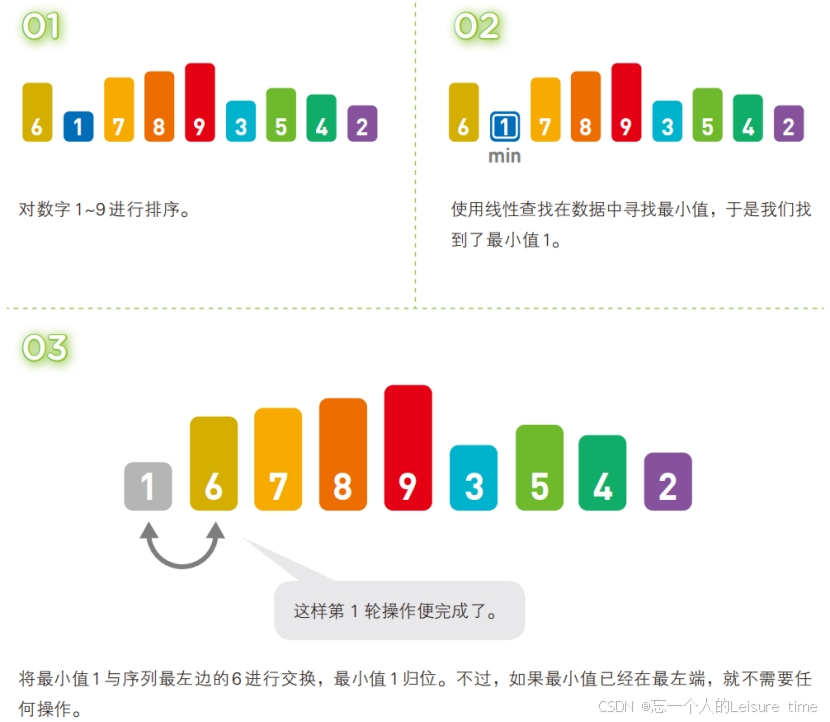
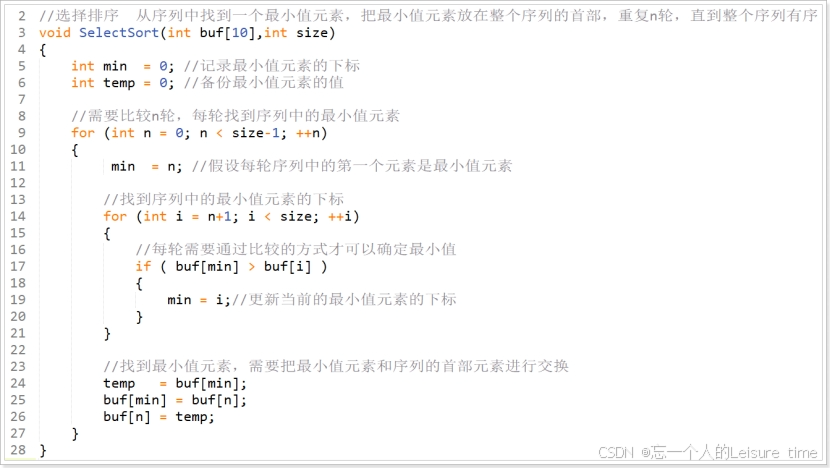
选择排序
选择排序的主要动作就是“
选择”,排序原理其实就是从未排序的数列找到最小的元素,放在已排序数列的开始位置,然后再从未排序的数列找到最小的元素,然后再放置已排序数列的末尾。
选择排序就是重复“从待排序的数据中寻找最小值,将其与序列最左边的数字进行交换”这一操作的算法。在序列中寻找最小值时使用的是
线性查找。
线性查找是一种在数组中查找数据的算法,线性查找的操作很简单,只要在数组中从头开始依次往下查找即可。
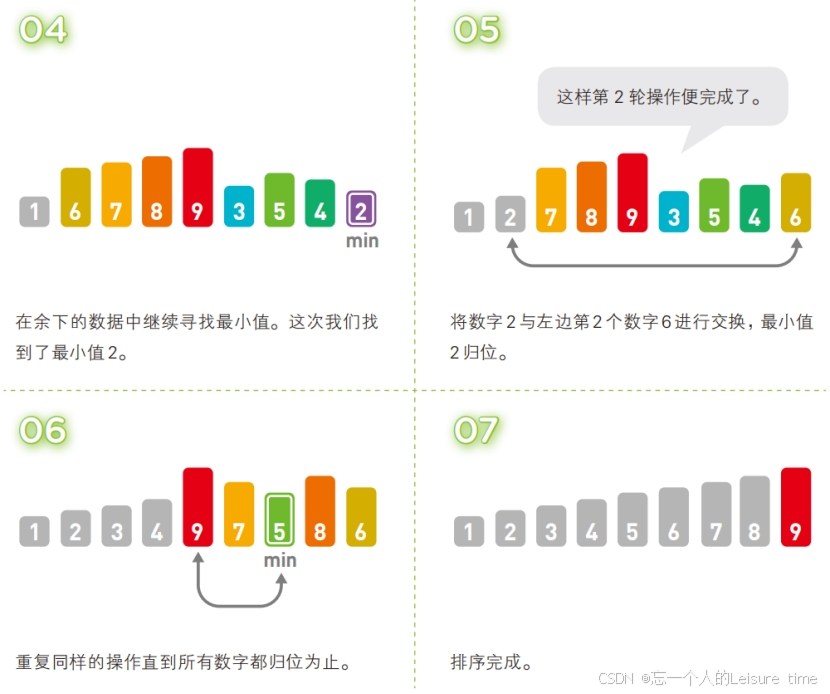
练习:设计一个程序,要求用户通过键盘依次输入10个随机整数,然后利用选择排序实现整数序列的升序排列。
-
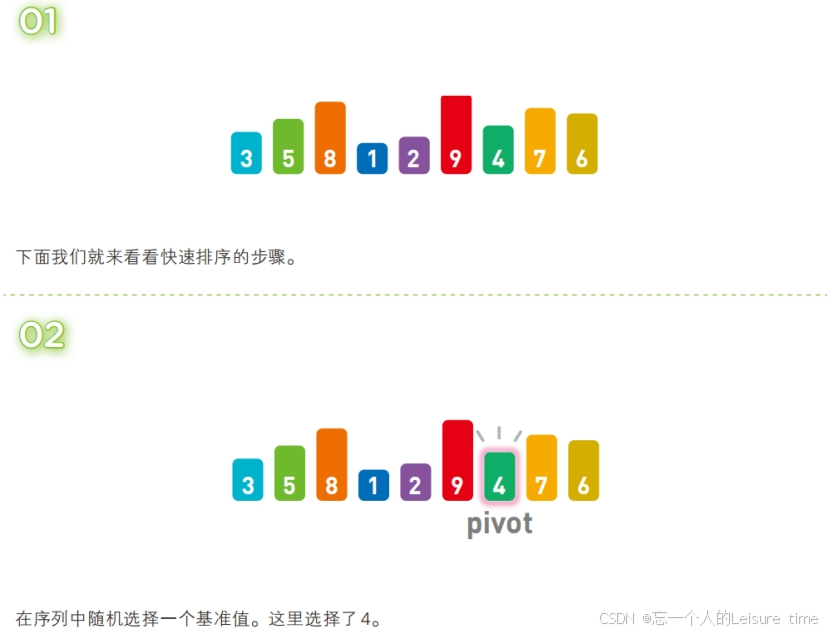
快速排序
快速排序也属于交换类的排序算法,特点是通过多次划分操作实现排序。快速排序算法首先会在序列中随机选择一个基准值(通常是序列中的第一个元素),然后将除了基准值以外的数分为“比基准值小的数”和“比基准值大的数”这两个类别,再将其排列成以下形式。
[ 比基准值小的数 ] 基准值 [ 比基准值大的数 ]
接着对两个“[ ]”中的数据进行排序之后,整体的排序便完成了。对“[ ]”里面的数据进行排序时同样也会使用快速排序。
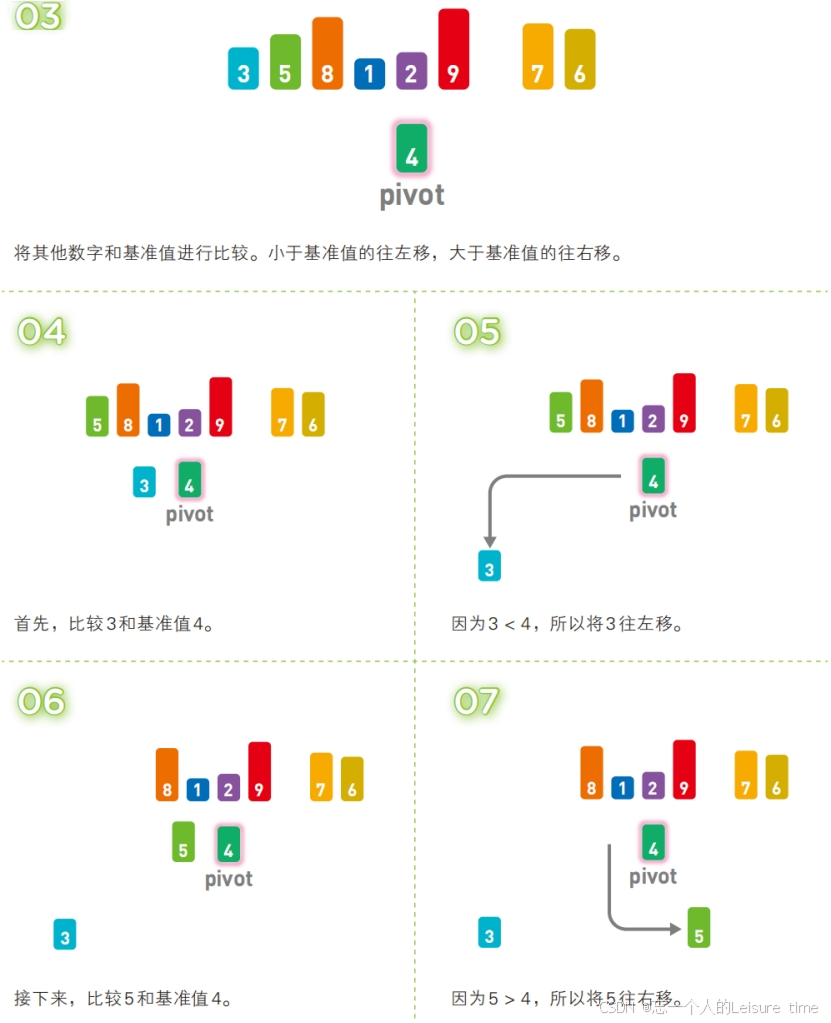
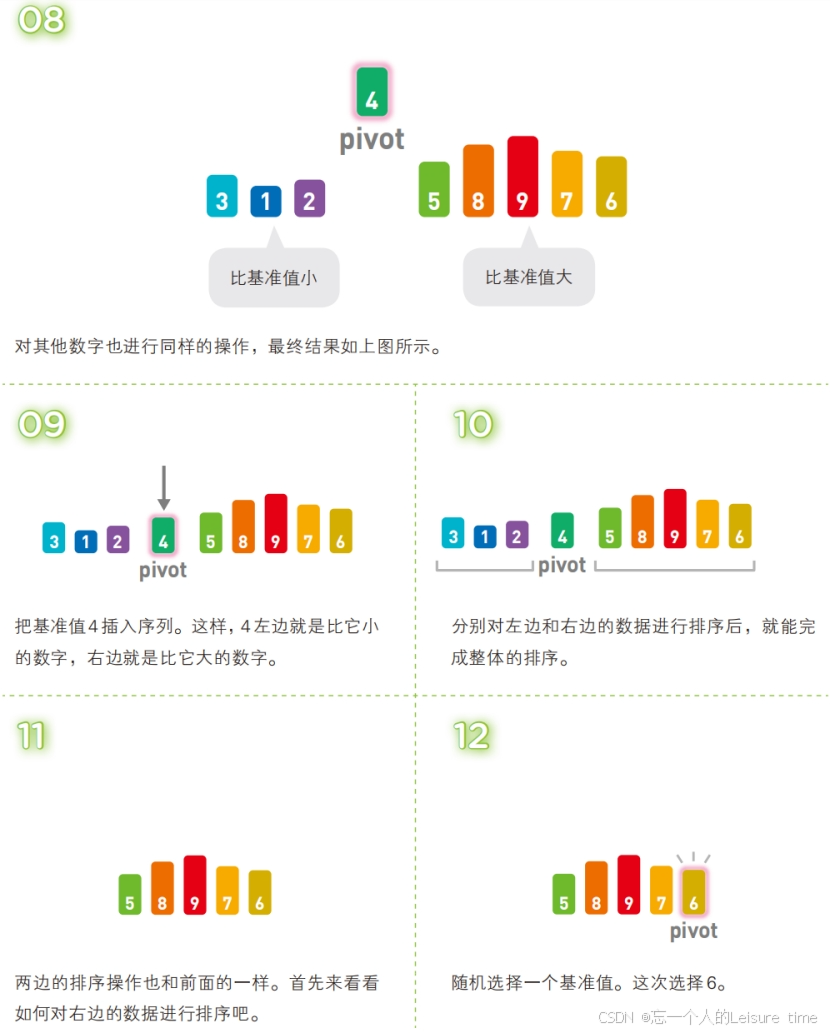
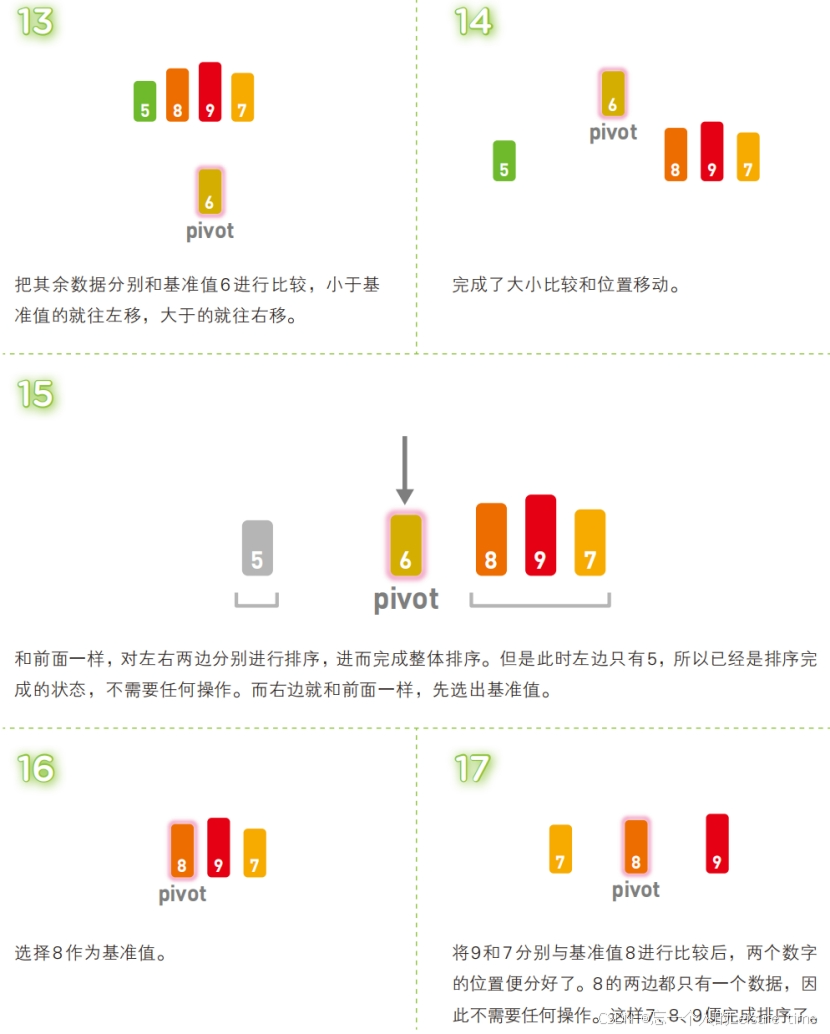
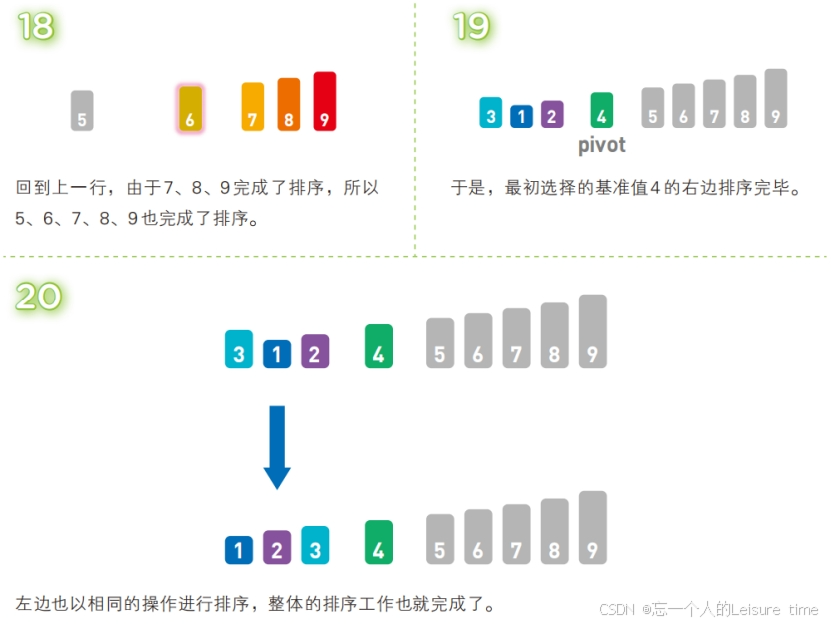
快速排序是一种“分治法”。它将原本的问题分成两个子问题(比基准值小的数和比基准值大的数),然后再分别解决这两个问题。子问题就是子序列完成排序后,再像一开始说明的那样,把他们合并成一个序列,那么对原始序列的排序也就完成了。
不过,解决子问题的时候会再次使用快速排序,甚至在这个快速排序里仍然要使用快速排序。只有在子问题里只剩一个数字的时候,排序才算完成。快速排序的算法中可以体现出“
递归”。
当要排序的序列越无序,快速排序算法的效率越高,当要排序的序列越有序,该算法的效率越低。

笔试题:

查找算法原理与应用
在一堆数据中,找到我们想要的那个数据,就是查找,也称为搜索,很容易想到,查找算法的优劣,取决于两个因素:
- 数据本身存储的特点
- 查找算法本身的特点
比如,如果数据存储是无序的,那么当我们想要在其中找到某个节点时,一般就只能对它们逐个比对。但是如果数据存储是有序且存放在一片连续的内存中,那么我们可以考虑从中间开始找(二分法)。
因此可以看到,在实际应用中如果需要优化数据的查找(搜索)性能,我们主要从以上两方面入手,当然,有时数据的存储特性是无法更改的,那么此时就只能靠优化算法本身去达到提供程序性能的目的了。
-
线性查找
线性查找是一种在数组中查找数据的算法,线性查找的操作很简单,只要在数组中从头开始依次往下查找即可。虽然存储的数据类型没有限制,但为了便于理解,这里我们假设存储的是整数。
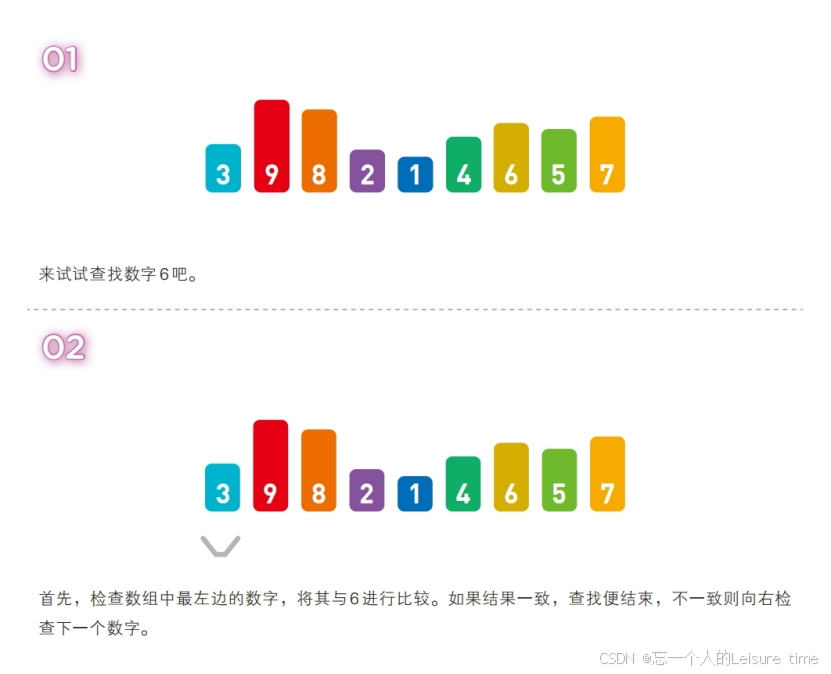
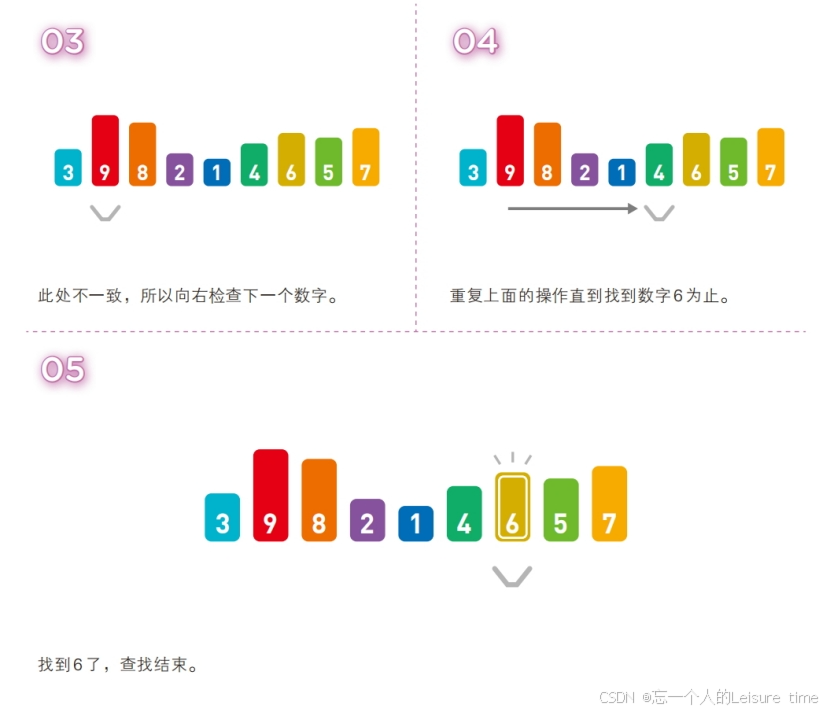
线性查找需要从头开始不断地按顺序检查数据,因此在数据量大且目标数据靠后或者目标数据不存在时,比较的次数就会更多,也更为耗时。若数据量为 n,线性查找的时间复杂度便为 O(n)。
线性查找法对于顺序表和链表都是适用的。对于顺序表,可以通过数组下标递增来顺序扫描数组中的各个元素;对于链表,则可通过表结点指针(假设为p)反复执行p=p->next;来扫描表中各个元素。
-
二分查找
如果待查找的数据本身是有序的,或者在查找前,可以对数据先进行排序(比如数据量虽然较大,但短期较稳定,无大面积更新),这种情况下使用二分查找可以进一步提升效率。
二分法的思路相当朴实无华:从中间开始找。既然数据是有序的,那么如果将待查找的节点跟中间节点对比,就可以以排除掉一半的数据,接着再在剩余的数据的中间开始找,又可以很快排除掉剩下的一半的数据,这种一半一半筛查数据的办法,就是所谓的二分法。
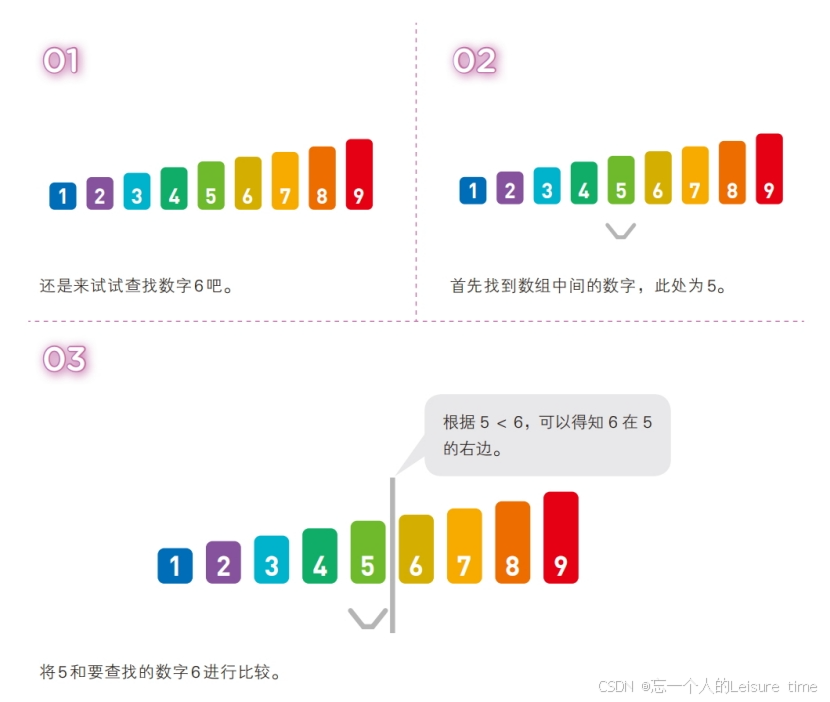

二分查找的时间复杂度为 O(logn),与线性查找的 O(n) 相比速度上得到了指数倍提高,也就是 x=log2n,则 n=2x 。
但是二分查找必须建立在数据已经排好序的基础上才能使用,因此添加数据时必须加到合适的位置,这就需要额外耗费维护数组的时间。
而使用线性查找时,数组中的数据可以是无序的,因此添加数据 时也无须顾虑位置,直接把它加在末尾即可,不需要耗费时间。综上,具体使用哪种查找方法,可以根据查找和添加两个操作哪个更为频繁来决定。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









