








往期精彩内容:
时序预测:LSTM、ARIMA、Holt-Winters、SARIMA模型的分析与比较
EMD变体分解效果最好算法——CEEMDAN(五)-优快云博客
拒绝信息泄露!VMD滚动分解 + Informer-BiLSTM并行预测模型-优快云博客
CEEMDAN +组合预测模型(BiLSTM-Attention + ARIMA)-优快云博客
CEEMDAN +组合预测模型(Transformer - BiLSTM + ARIMA)-优快云博客
基于麻雀优化算法SSA的CEEMDAN-BiLSTM-Attention的预测模型-优快云博客
基于麻雀优化算法SSA的CEEMDAN-Transformer-BiGRU预测模型-优快云博客
VMD + CEEMDAN 二次分解,BiLSTM-Attention预测模型-优快云博客
VMD + CEEMDAN 二次分解,CNN-Transformer预测模型-优快云博客
风速预测(八)VMD-CNN-Transformer预测模型-优快云博客
高创新 | CEEMDAN + SSA-TCN-BiLSTM-Attention预测模型-优快云博客
VMD + CEEMDAN 二次分解,Transformer-BiGRU预测模型-优快云博客
独家原创 | 基于TCN-SENet +BiGRU-GlobalAttention并行预测模型-优快云博客
VMD + CEEMDAN 二次分解——创新预测模型合集-优快云博客
独家原创 | BiTCN-BiGRU-CrossAttention融合时空特征的高创新预测模型-优快云博客
CEEMDAN +组合预测模型(CNN-Transfromer + XGBoost)-优快云博客
创新点:
1. BiTCN模块:使用了BiTCN模块来提取时序空间特征。BiTCN由多个TemporalBlock组成,每个TemporalBlock都包含两个卷积层,批标准化和ReLU激活函数,以及dropout层。此外,BiTCN还应用了权重归一化处理,加速收敛并提高模型的泛化能力。
2. Transformer模块:采用了Transformer编码器模块来提取时域特征。Transformer编码器其优越的结构和多头注意力机制,能够有效地捕捉序列数据中的时间依赖关系,提高了模型对时间序列的建模能力。
3. 序列平均池化和全连接层:在模型的最后阶段融合时空特征,采用了序列平均池化操作和全连接层进行预测。这样的设计能够将时空特征有效地映射到预测结果空间,从而实现对序列数据的准确预测。
注意:此次产品,我们还有配套的模型讲解和参数调节讲解!

前言
本文基于前期介绍的电力变压器(文末附数据集),介绍一种融合时空特征的BiTCN-Transformer并行预测模型,以提高时间序列数据的预测性能。电力变压器数据集的详细介绍可以参考下文:
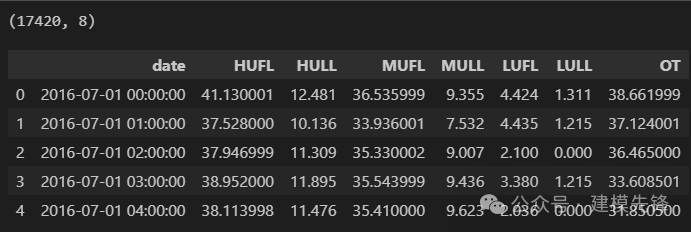
该模型 多变量特征 | 单变量序列预测都适用!
1 模型整体结构
模型整体结构如下所示,多特征变量时间序列数据先经过BiTCN网络提取全局空间特征,同时数据通过Transformer网络提取时序特征,再进行时空特征融合,最后经过全连接层进行高精度预测。
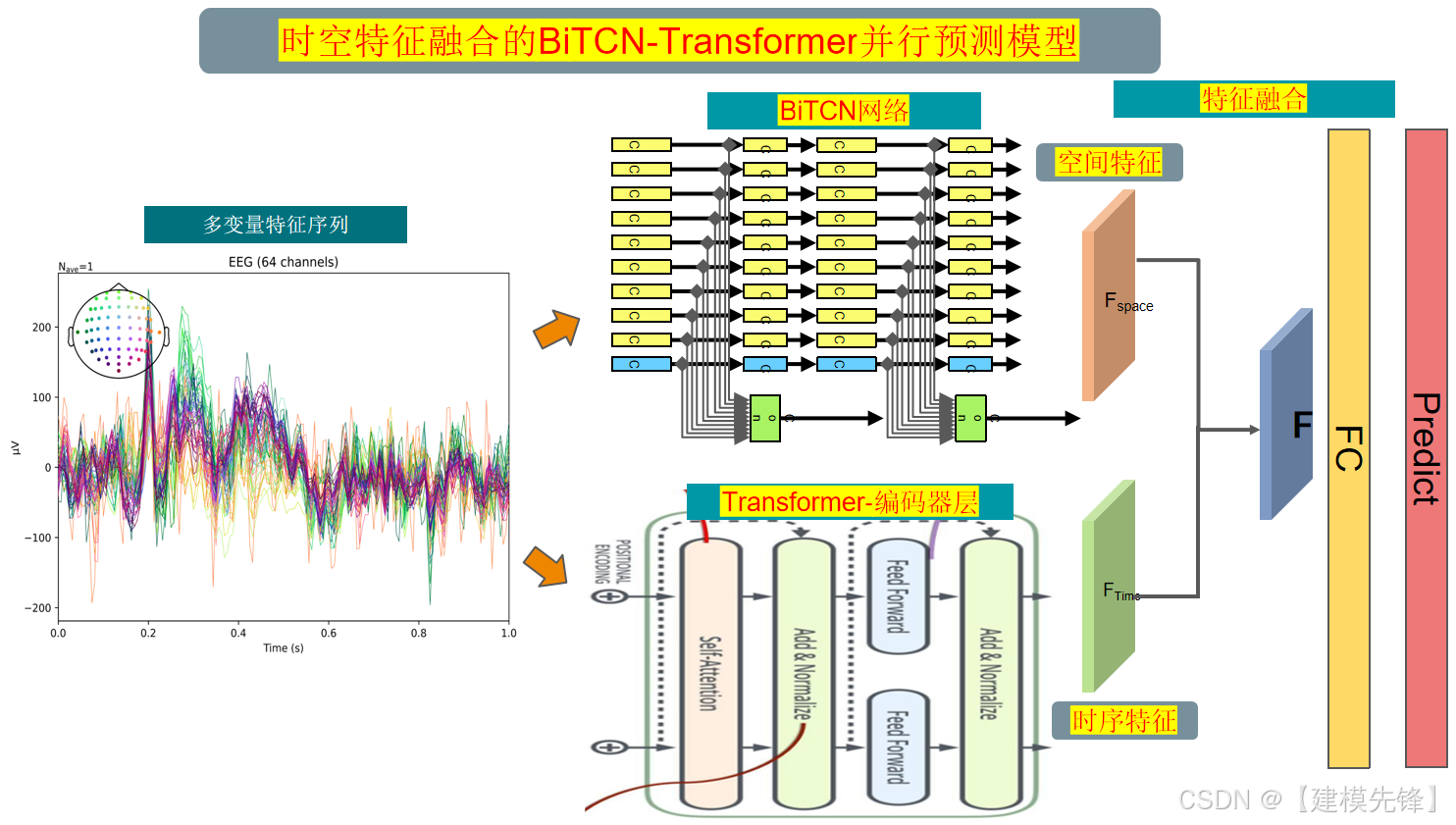
(1) 双向时空卷积网络(BiTCN):
BiTCN(双向时空卷积网络)是一种用于处理时间序列数据的神经网络模型。它主要用于提取时序空间特征,以捕捉序列数据中的空间相关性和时间依赖性。
-
双向性质:BiTCN包含两个方向的卷积操作,分别用于正向和反向的时间序列数据。这种双向设计能够有效地捕捉序列数据中前后关系,提高模型对时间依赖性的建模能力。
-
时空卷积:BiTCN使用了时空卷积操作,将卷积核在时间和空间维度上同时滑动,以获取序列数据中不同时间点和空间位置的特征信息。这种卷积操作能够有效地捕捉序列数据中的局部模式和全局趋势。
-
多层结构:BiTCN通常由多个TemporalBlock组成,每个TemporalBlock包含两个卷积层,批标准化和ReLU激活函数,以及dropout层。这种多层结构能够逐渐提取抽象层次的时序空间特征,从而提高模型的表示能力。
-
权重归一化:为了加速收敛并提高模型的泛化能力,BiTCN通常会对卷积核进行权重归一化处理。这种处理能够有效地减少训练过程中的梯度消失和爆炸问题,从而提高模型的稳定性和泛化能力。
(2) Transformer模块:
Transformer模型在处理长距离依赖关系时表现更好,并且可以高效地并行计算,适用于大规模数据集。
-
编码器:Transformer模型包含若干个编码器堆叠而成,每个编码器由多个相同的层组成。每个层包含两个子层:自注意力机制(Self-Attention)和前馈神经网络(Feed-Forward Neural Network)。
-
多头注意力(Multi-Head Attention):为了增强模型的表达能力和捕获更丰富的特征,Transformer模型引入了多头注意力机制。在多头注意力中,输入序列的隐藏表示会分别通过多个不同的注意力头进行处理,然后将不同头的输出进行拼接和线性变换。多头注意力机制可以使模型同时关注输入序列中不同方面的特征,提高了模型的表示能力和学习能力。
2 多特征变量数据集制作与预处理
2.1 导入数据

2.2 制作数据集
制作数据集与分类标签

3 基于BiTCN-Transformer的高精度并行预测模型
3.1 定义网络模型
3.2 设置参数,训练模型
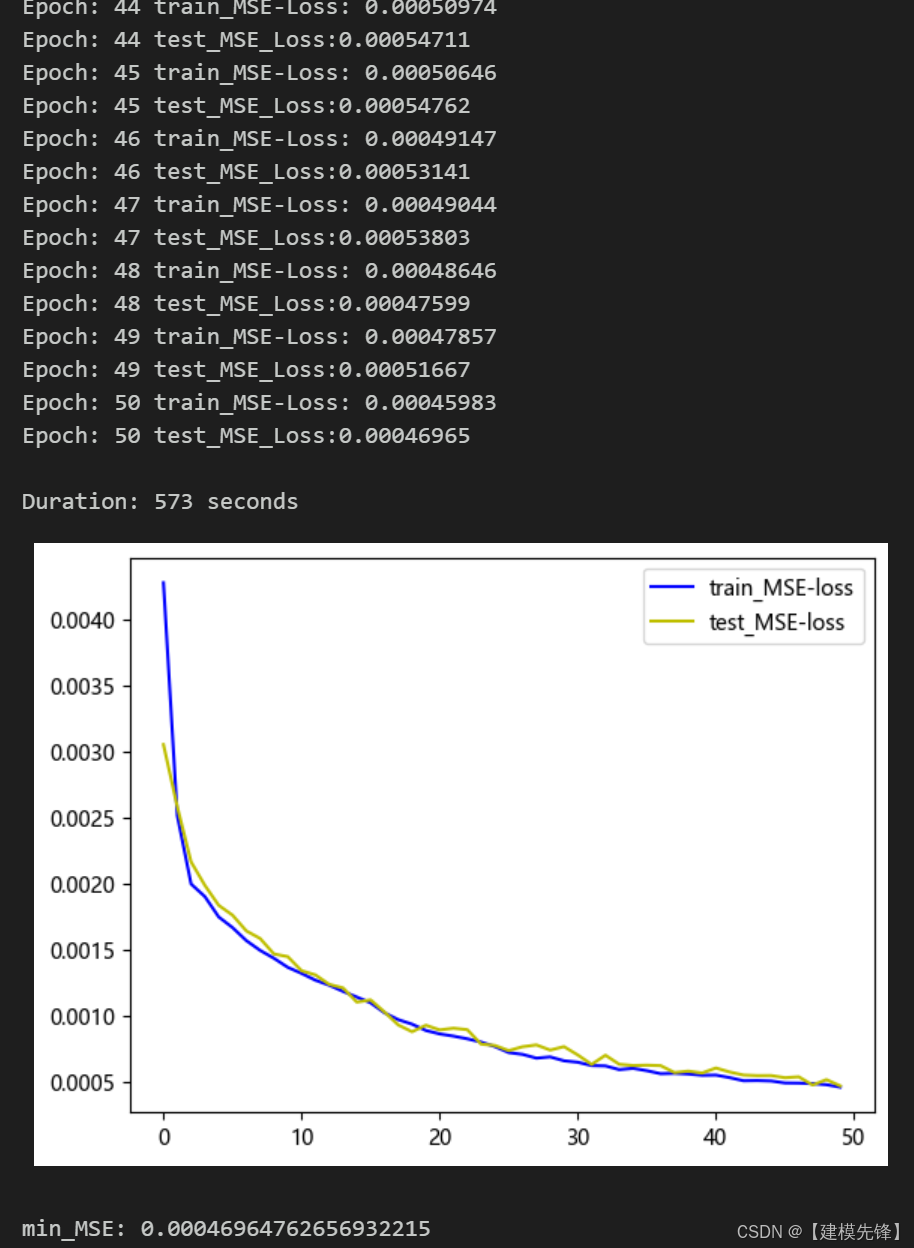
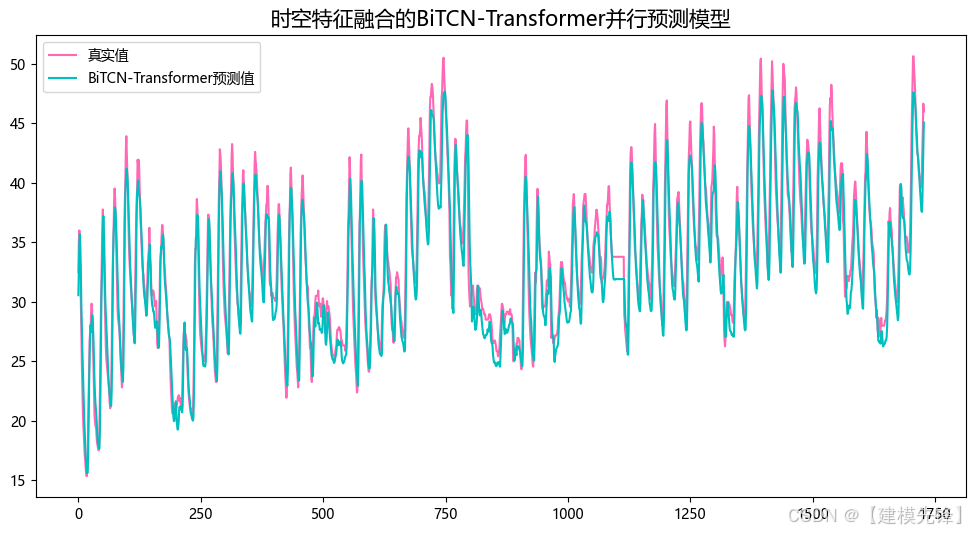
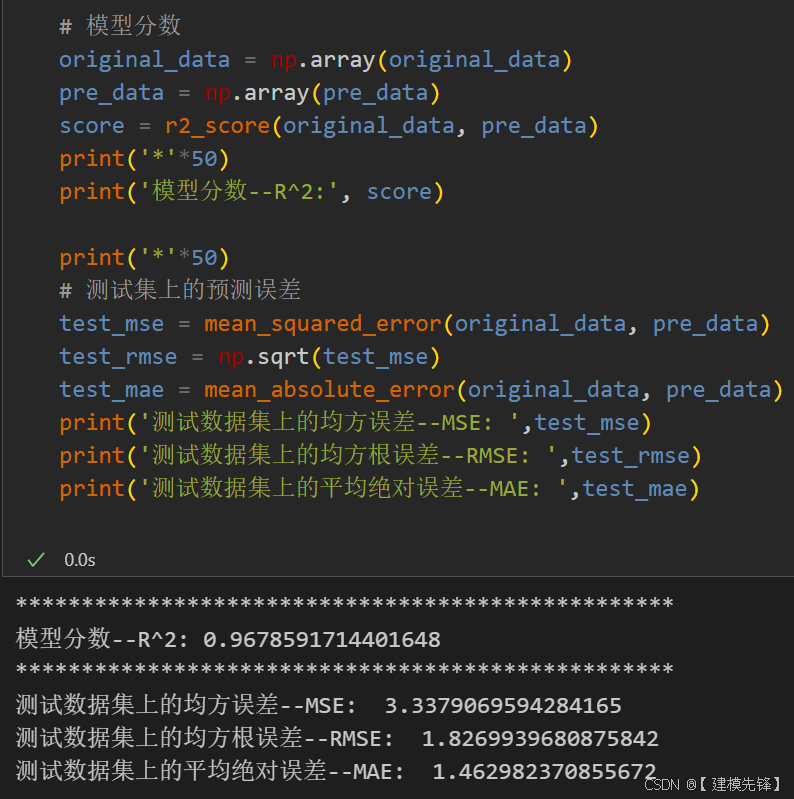
50个epoch,MSE 为0.000469,多变量特征BiTCN-Transformer并行融合网络模型预测效果显著,模型能够充分提取时间序列的空间特征和时序特征,收敛速度快,性能优越,预测精度高,适当调整模型参数,还可以进一步提高模型预测表现。
注意调整参数:
-
可以适当增加BiTCN层数和每层的通道数,微调学习率;
-
调整Transformer编码器层数、多头注意力头数、注意力维度数,增加更多的 epoch (注意防止过拟合)
-
可以改变滑动窗口长度(设置合适的窗口长度)
3.3 模型评估和可视化
预测结果可视化
模型评估
4 代码、数据整理如下:

















 1953
1953

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









