







Spark Core
- 什么是 RDD
代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合
弹性
存储的弹性:内存与磁盘的自动切换;
容错的弹性:数据丢失可以自动恢复;
计算的弹性:计算出错重试机制;
分片的弹性:可根据需要重新分片。
分布式:数据存储在大数据集群不同节点上
数据集:RDD 封装了计算逻辑,并不保存数据
数据抽象:RDD 是一个抽象类,需要子类具体实现
不可变:RDD 封装了计算逻辑,是不可以改变的,想要改变,只能产生新的 RDD在新的 RDD 里面封装计算逻辑
可分区、并行计算
二.核心属性
分区列表
RDD 数据结构中存在分区列表,用于执行任务时并行计算,是实现分布式计算的重要属性。
RDD 之间的依赖关系
RDD 是计算模型的封装,当需求中需要将多个计算模型进行组合时,就需要将多个 RDD 建立依赖关系
三. 执行原理
启动 Yarn 集群环境
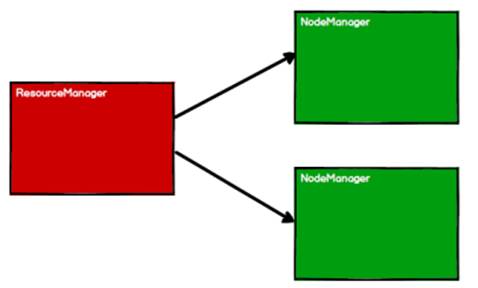
Spark 通过申请资源创建调度节点和计算节点
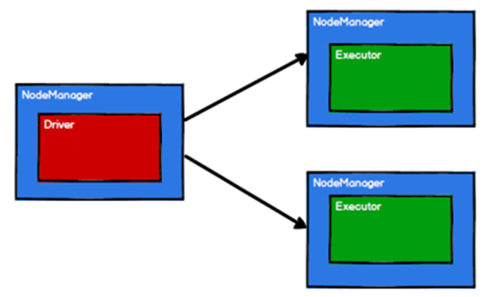
Spark 框架根据需求将计算逻辑根据分区划分成不同的任务

调度节点将任务根据计算节点状态发送到对应的计算节点进行计算
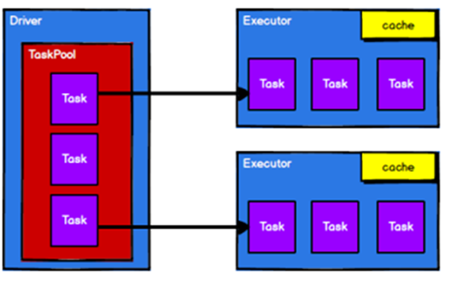
四.RDD 序列化
闭包检查
序列化方法和属性
Kryo 序列化框架
五.RDD 依赖关系
RDD 血缘关系
RDD 只支持粗粒度转换,即在大量记录上执行的单个操作。将创建 RDD 的一系列 Lineage(血统)记录下来,以便恢复丢失的分区
RDD 依赖关系
RDD 窄依赖
RDD 宽依赖
宽依赖表示同一个父(上游)RDD 的 Partition 被多个子(下游)RDD 的 Partition 依赖,会引起 Shuffle,总结:宽依赖我们形象的比喻为多生
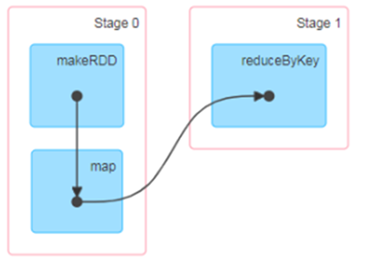
RDD 阶段划分
RDD 任务划分

六.RDD 持久化
RDD Cache 缓存
Spark 会自动对一些 Shuffle 操作的中间数据做持久化操作(比如:reduceByKey)。这样做的目的是为了当一个节点 Shuffle 失败了避免重新计算整个输入。但是,在实际使用的时候,如果想重用数据,仍然建议调用 persist 或 cache
RDD CheckPoint 检查点
缓存和检查点区别
七.RDD 分区器
只有 Key-Value 类型的 RDD 才有分区器,非 Key-Value 类型的 RDD 分区的值是 None
➢ 每个 RDD 的分区 ID 范围:0 ~ (numPartitions - 1),决定这个值是属于那个分区的。
- Hash 分区:对于给定的 key,计算其 hashCode,并除以分区个数取余。
- Range 分区:将一定范围内的数据映射到一个分区中,尽量保证每个分区数据均匀,而且分区间有序
八.RDD 文件读取与保存
text 文件

sequence 文件

sequence 文件

object 对象文件

Spark运行架构
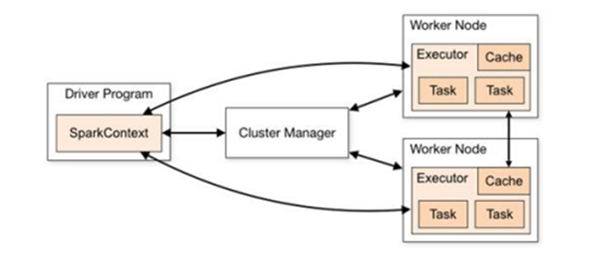
核心组件
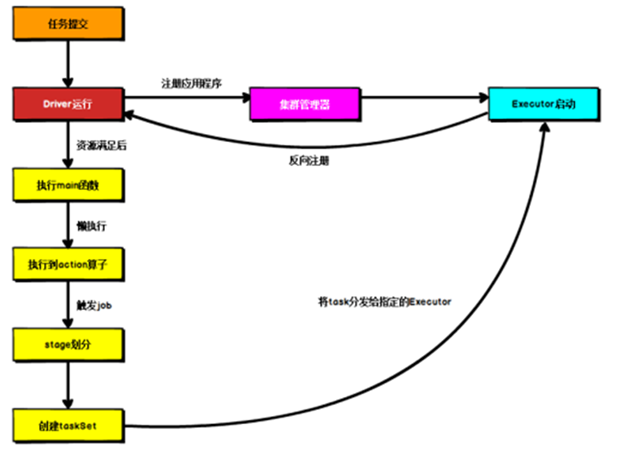
Driver
Spark 驱动器节点,用于执行 Spark 任务中的 main 方法,负责实际代码的执行工作。
Driver 在 Spark 作业执行时主要负责:
➢ 将用户程序转化为作业(job)
➢ 在 Executor 之间调度任务(task)
➢ 跟踪 Executor 的执行情况
➢ 通过 UI 展示查询运行情况
Executor
Spark Executor 是集群中工作节点(Worker)中的一个 JVM 进程,负责在 Spark 作业中运行具体任务(Task),任务彼此之间相互独立
核心概念

有向无环图(DAG)
提交流程


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









