







目录
1>概念
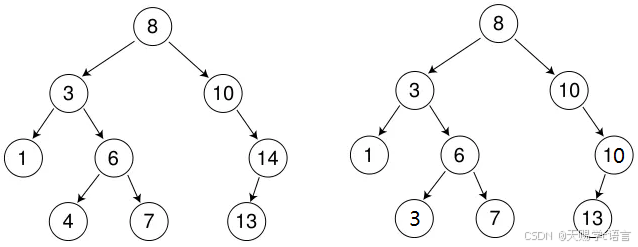
⼆叉搜索树⼜称⼆叉排序树,它或者是⼀棵空树,或者是具有以下性质的⼆叉树:
① 若它的左⼦树不为空,则左⼦树上所有结点的值都⼩于等于根结点的值
② 若它的右⼦树不为空,则右⼦树上所有结点的值都⼤于等于根结点的值
③ 它的左右⼦树也分别为⼆叉搜索树
④ ⼆叉搜索树中可以⽀持插⼊相等的值,也可以不⽀持插⼊相等的值,具体看使⽤场景定义
2>性能分析
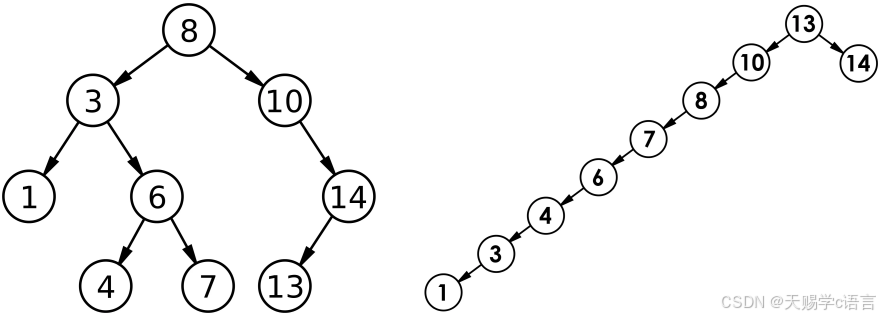
最优情况下,⼆叉搜索树为完全⼆叉树(或者接近完全⼆叉树),其⾼度为: log2 N
最差情况下,⼆叉搜索树退化为单⽀树(或者类似单⽀),其⾼度为: N
所以综合⽽⾔⼆叉搜索树增删查时间复杂度为: O(N)
另外提一点,⼆分查找也可以实现 O(log2 N) 级别的查找效率,但是⼆分查找有两⼤缺陷:
① 需要存储在⽀持下标随机访问的结构中,并且有序
② 插⼊和删除数据效率很低,因为存储在下标随机访问的结构中,插⼊和删除数据⼀般需要挪动数据
3>插入
插⼊的具体过程如下:
① 树为空,则直接新增结点,赋值给root指针
② 树不空,按⼆叉搜索树性质,插⼊值⽐当前结点⼤往右⾛,插⼊值⽐当前结点⼩往左⾛,找到空位置,插⼊新结点
③ 如果⽀持插⼊相等的值,插⼊值跟当前结点相等的值可以往右⾛,也可以往左⾛,找到空位置,插⼊新结点
int arr[] = {8, 3, 1, 10, 6, 4, 7, 14, 13};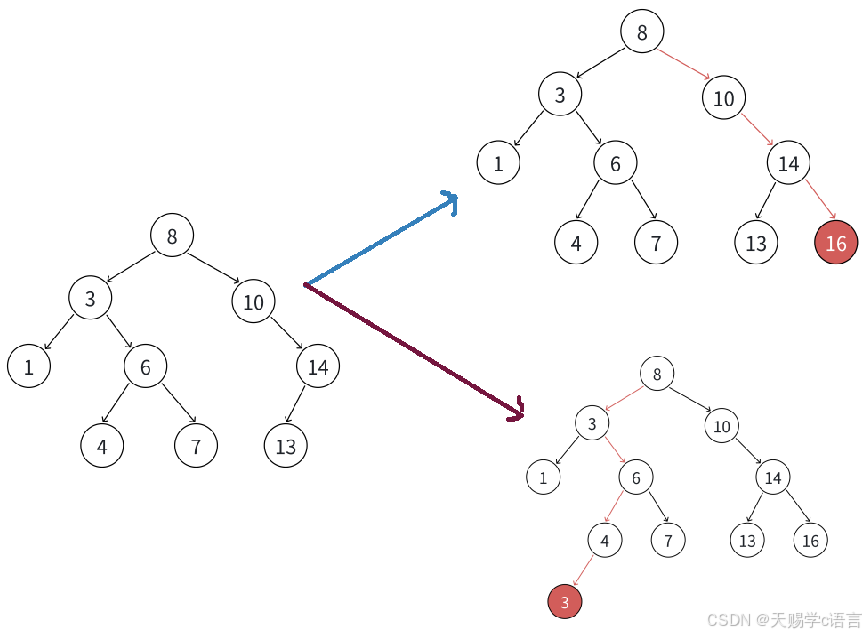
bool insert(const K& key)
{
if (_root == nullptr)
{
_root = new Node(key);
return true;
}
Node* parent = _root;
Node* cur = _root;
while (cur)
{
if (cur->_key > key)
{
parent = cur;
cur = cur->left;
}
else if (cur->_key < key)
{
parent = cur;
cur = cur->right;
}
else
{
return false;
}
}
cur = new Node(key);
if (parent->_key > key)
{
parent->left = cur;
}
else
{
parent->right = cur;
}
return true;
}4>查找
① 从根开始⽐较,查找x,x⽐根的值⼤则往右边⾛查找,x⽐根值⼩则往左边⾛查找
② 最多查找⾼度次,⾛到到空,还没找到,这个值不存在
③ 如果不⽀持插⼊相等的值,找到x即可返回
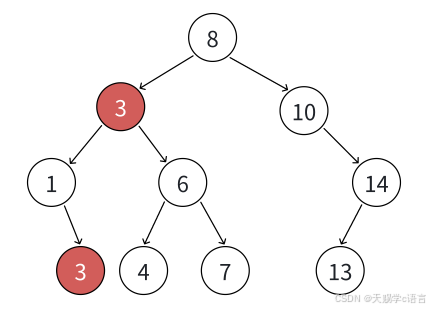
④ 如果⽀持插⼊相等的值,意味着有多个x存在,⼀般要求查找中序的第⼀个x。如下图,查找3,要找到1的右孩⼦的那个3返回
bool find(const K& key)
{
Node* cur = _root;
while (cur)
{
if (cur->_key > key)
{
cur = cur->left;
}
else if (cur->_key < key)
{
cur = cur->right;
}
else
{
return true;
}
}
return false;
}5>删除
⾸先查找元素是否在⼆叉搜索树中,如果不存在,则返回false
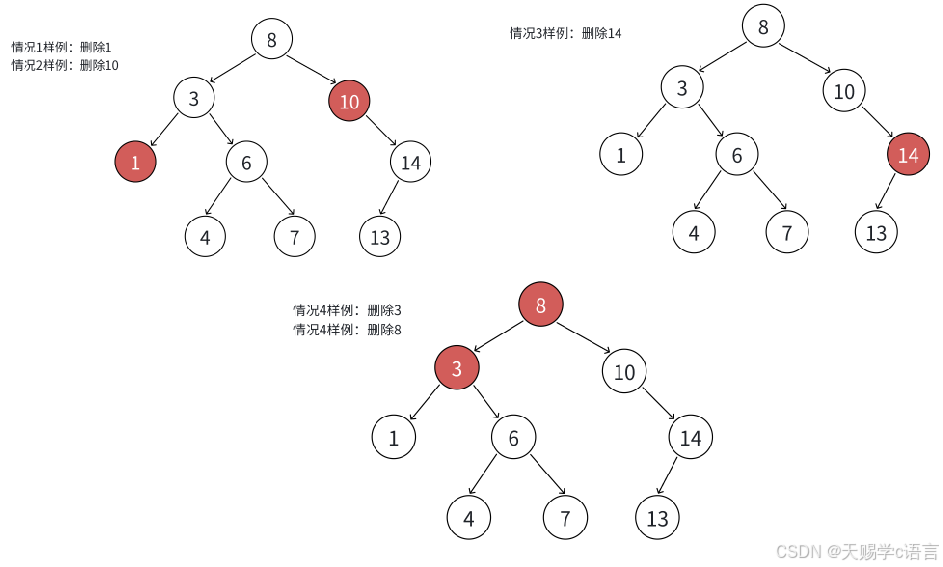
如果查找元素存在则分以下四种情况分别处理:(假设要删除的结点为N)
(1)要删除结点N左右孩⼦均为空
(2)要删除的结点N左孩⼦位空,右孩⼦结点不为空
(3)要删除的结点N右孩⼦位空,左孩⼦结点不为空
(4)要删除的结点N左右孩⼦结点均不为空
对应以上四种情况的解决⽅案:
① 把N结点的⽗亲对应孩⼦指针指向空,直接删除N结点(情况1可以当成2或者3处理,效果是⼀样的)
② 把N结点的⽗亲对应孩⼦指针指向N的右孩⼦,直接删除N结点
③ 把N结点的⽗亲对应孩⼦指针指向N的左孩⼦,直接删除N结点
④ ⽆法直接删除N结点,因为N的两个孩⼦⽆处安放,只能⽤替换法删除。找N左⼦树的值最⼤结点R(最右结点)或者N右⼦树的值最⼩结点R(最左结点)替代N,因为这两个结点中任意⼀个,放到N的位置,都满⾜⼆叉搜索树的规则
替代N的意思就是N和R的两个结点的值交换,转⽽变成删除R结点,R结点符合情况2或情况3,可以直接删除
bool erase(const K& key)
{
Node* parent = _root;
Node* cur = _root;
while (cur)
{
if (cur->_key > key)
{
parent = cur;
cur = cur->left;
}
else if (cur->_key < key)
{
parent = cur;
cur = cur->right;
}
else
{
if (cur->left == nullptr)
{
if (cur == _root)
{
_root = cur->right;
}
else
{
if (parent->_key > cur->_key)
{
parent->left = cur->right;
}
else
{
parent->right = cur->right;
}
}
delete cur;
}
else if (cur->right == nullptr)
{
if (cur == _root)
{
_root = cur->right;
}
else
{
if (parent->_key > cur->_key)
{
parent->left = cur->left;
}
else
{
parent->right = cur->left;
}
}
delete cur;
}
else
{
Node* minparent = cur;
Node* minright = cur->right;
while (minright->left)
{
minparent = minright;
minright = minright->left;
}
cur->_key = minright->_key;
if (minparent->left == minright)
{
minparent->left = minright->right;
}
else
{
minparent->right = minright->right;
}
delete minright;
}
return true;
}
}
return false;
}6>实现代码
这里需要注意的是中序遍历这个函数,因为我们遍历它肯定是要给root的,但是root作为私有成员在类外不可访问,那我们可以采用嵌套的方式去访问_root
namespace tianci
{
template<class K>
struct BSTNode
{
K _key;
BSTNode<K>* left;
BSTNode<K>* right;
BSTNode(const K& key)
:_key(key)
,left(nullptr)
,right(nullptr)
{}
};
template<class K>
class BSTree
{
typedef BSTNode<K> Node;
public:
bool insert(const K& key)
{
if (_root == nullptr)
{
_root = new Node(key);
return true;
}
Node* parent = _root;
Node* cur = _root;
while (cur)
{
if (cur->_key > key)
{
parent = cur;
cur = cur->left;
}
else if (cur->_key < key)
{
parent = cur;
cur = cur->right;
}
else
{
return false;
}
}
cur = new Node(key);
if (parent->_key > key)
{
parent->left = cur;
}
else
{
parent->right = cur;
}
return true;
}
bool find(const K& key)
{
Node* cur = _root;
while (cur)
{
if (cur->_key > key)
{
cur = cur->left;
}
else if (cur->_key < key)
{
cur = cur->right;
}
else
{
return true;
}
}
return false;
}
bool erase(const K& key)
{
Node* parent = _root;
Node* cur = _root;
while (cur)
{
if (cur->_key > key)
{
parent = cur;
cur = cur->left;
}
else if (cur->_key < key)
{
parent = cur;
cur = cur->right;
}
else
{
if (cur->left == nullptr)
{
if (cur == _root)
{
_root = cur->right;
}
else
{
if (parent->_key > cur->_key)
{
parent->left = cur->right;
}
else
{
parent->right = cur->right;
}
}
delete cur;
}
else if (cur->right == nullptr)
{
if (cur == _root)
{
_root = cur->right;
}
else
{
if (parent->_key > cur->_key)
{
parent->left = cur->left;
}
else
{
parent->right = cur->left;
}
}
delete cur;
}
else
{
Node* minparent = cur;
Node* minright = cur->right;
while (minright->left)
{
minparent = minright;
minright = minright->left;
}
cur->_key = minright->_key;
if (minparent->left == minright)
{
minparent->left = minright->right;
}
else
{
minparent->right = minright->right;
}
delete minright;
}
return true;
}
}
return false;
}
void Inorder()
{
_Inorder(_root);
}
private:
void _Inorder(Node* cur)
{
if (cur == nullptr)
{
return;
}
_Inorder(cur->left);
cout << cur->_key << ' ';
_Inorder(cur->right);
}
Node* _root = nullptr;
};
}插入和查找相对简单一些,删除的逻辑稍微复杂一点,当面试的时候遇到搜索二叉树,那大概率会让你敲删除的代码,因为删除的细节比较多
另外大家可以尝试敲敲,下面这段代码可以帮助你测试一下代码有没有问题
void TestBSTree1()
{
tianci::BSTree<int> tree;
int arr[] = { 8, 3, 1, 10, 6, 4, 7, 14, 13 };
for (auto& e : arr)
{
tree.insert(e);
}
tree.Inorder();
cout << endl;
tree.erase(1);
tree.Inorder();
tree.erase(10);
tree.Inorder();
tree.erase(8);
tree.Inorder();
for (auto& e : arr)
{
tree.erase(e);
}
tree.Inorder();
}7>使用场景
a.key搜索场景
只有key作为关键码,结构中只需要存储key即可,关键码即为需要搜索到的值,搜索场景只需要判断key在不在。key的搜索场景实现的⼆叉树搜索树⽀持增删查,但是不⽀持修改,修改key破坏搜索树结构了
例如,检查⼀篇英⽂⽂章单词拼写是否正确,将词库中所有单词放⼊⼆叉搜索树,读取⽂章中的单词,查找是否在⼆叉搜索树中,不在则波浪线标红提⽰
b.key/value搜索场景
每⼀个关键码key,都有与之对应的值value,value可以任意类型对象。树的结构中(结点)除了需要存储key还要存储对应的value,增/删/查还是以key为关键字⾛⼆叉搜索树的规则进⾏⽐较,可以快速查找到key对应的value
key/value的搜索场景实现的⼆叉树搜索树⽀持修改,但是不⽀持修改key,修改key破坏搜索树性质了,可以修改value
例如,简单中英互译字典,树的结构中(结点)存储key(英⽂)和vlaue(中⽂),搜索时输⼊英⽂,则同时查找到了英⽂对应的中⽂
c.key/value代码实现
namespace tianci
{
template<class K, class V>
struct BSTNode
{
K _key;
V _value;
BSTNode<K,V>* left;
BSTNode<K,V>* right;
BSTNode(const K& key, const V& value)
:_key(key)
,_value(value)
, left(nullptr)
, right(nullptr)
{}
};
template<class K, class V>
class BSTree
{
typedef BSTNode<K,V> Node;
public:
bool insert(const K& key, const V& value)
{
if (_root == nullptr)
{
_root = new Node(key,value);
return true;
}
Node* parent = _root;
Node* cur = _root;
while (cur)
{
if (cur->_key > key)
{
parent = cur;
cur = cur->left;
}
else if (cur->_key < key)
{
parent = cur;
cur = cur->right;
}
else
{
return false;
}
}
cur = new Node(key, value);
if (parent->_key > key)
{
parent->left = cur;
}
else
{
parent->right = cur;
}
return true;
}
Node* find(const K& key)
{
Node* cur = _root;
while (cur)
{
if (cur->_key > key)
{
cur = cur->left;
}
else if (cur->_key < key)
{
cur = cur->right;
}
else
{
return cur;
}
}
return nullptr;
}
bool erase(const K& key)
{
Node* parent = _root;
Node* cur = _root;
while (cur)
{
if (cur->_key > key)
{
parent = cur;
cur = cur->left;
}
else if (cur->_key < key)
{
parent = cur;
cur = cur->right;
}
else
{
if (cur->left == nullptr)
{
if (cur == _root)
{
_root = cur->right;
}
else
{
if (parent->_key > cur->_key)
{
parent->left = cur->right;
}
else
{
parent->right = cur->right;
}
}
delete cur;
}
else if (cur->right == nullptr)
{
if (cur == _root)
{
_root = cur->right;
}
else
{
if (parent->_key > cur->_key)
{
parent->left = cur->left;
}
else
{
parent->right = cur->left;
}
}
delete cur;
}
else
{
Node* minparent = cur;
Node* minright = cur->right;
while (minright->left)
{
minparent = minright;
minright = minright->left;
}
cur->_key = minright->_key;
if (minparent->left == minright)
{
minparent->left = minright->right;
}
else
{
minparent->right = minright->right;
}
delete minright;
}
return true;
}
}
return false;
}
void Inorder()
{
_Inorder(_root);
cout << endl;
}
private:
void _Inorder(Node* cur)
{
if (cur == nullptr)
{
return;
}
_Inorder(cur->left);
cout << cur->_key << ':' << cur->_value << endl;
_Inorder(cur->right);
}
Node* _root = nullptr;
};
}逻辑和key的实现是一样的,大家可以尝试敲敲,下面这段代码可以帮助你测试一下代码有没有问题
void TestBSTree2()
{
key_value::BSTree<string, string> tree;
tree.insert("insert", "插入");
tree.insert("erase", "删除");
tree.insert("left", "左边");
tree.insert("string", "字符串");
string str;
while (cin >> str)
{
auto ret = tree.find(str);
if (ret)
{
cout << str << ":" << ret->_value << endl;
}
else
{
cout << "单词拼写错误" << endl;
}
}
string strs[] = { "苹果", "西瓜", "苹果", "樱桃", "苹果", "樱桃", "苹果", "樱桃", "苹果" };
// 统计水果出现的次
key_value::BSTree<string, int> countTree;
for (auto str : strs)
{
auto ret = countTree.find(str);
if (ret == NULL)
{
countTree.insert(str, 1);
}
else
{
ret->_value++;
}
}
countTree.Inorder();
}本篇文章到这里就结束啦,希望这些内容对大家有所帮助!
下篇文章见,希望大家多多来支持一下!
感谢大家的三连支持!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









