






一.原理
首先搞清楚slowfast算法,SlowFast 算法是由 Facebook AI Research (FAIR) 提出的一个深度学习模型,专门用于视频理解任务(如动作识别、视频分类等)。它的核心思想是通过设计两个不同速度的网络来处理视频帧,以便在不同的时间尺度上捕捉视频的多层次信息,从而提升视频理解的效果。
视频中的动作和事件通常发生在不同的时间尺度上。例如,某些动作(如挥手、跑步)可能是瞬间发生的,而一些长期事件(如跳跃、走路)则需要更多的上下文信息才能理解。
Slow Pathway(慢路径):以较低的帧率处理视频。通常这个路径处理视频的全局信息,每秒处理较少的帧,通常按照2帧,这样可以捕捉到较慢的、长期的上下文信息。
Fast Pathway(快路径):以较高的帧率处理视频,通常每秒处理更多的帧,通常按照15帧,这样可以捕捉到视频中的细节和快速变化的信息。
合流以后取公帧率为每秒30帧进行裁剪图片。
二.视频裁剪
可以选择较短时长的视频尝试一下,我选择了一个30s的视频,并裁剪出900帧,保存到文件夹中。在这里随便选取了视频的30s,按照需求自行更改。
from moviepy.editor import VideoFileClip
import os
# 视频文件路径
video_path = "2.mp4" # 替换成你的视频文件路径
output_folder = "2_images" # 存储帧的文件夹
# 如果输出文件夹不存在,创建一个
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 读取视频文件
video = VideoFileClip(video_path)
# 裁剪视频时间段 51:20s 到 51:50s
start_time = 51 * 60 + 20 # 51:20s 转换为秒
end_time = 51 * 60 + 50 # 51:50s 转换为秒
clipped_video = video.subclip(start_time, end_time)
# 每秒提取 30 帧
fps = 30 # 每秒30帧
# 提取帧并保存为图片
for t in range(start_time, end_time):
for i in range(fps):
# 每一秒钟提取30帧,t + i / fps 表示每一帧的时间点
frame_time = t + (i / fps)
# 获取当前时间点的视频帧
frame = clipped_video.get_frame(frame_time)
# 保存帧为图像文件
frame_filename = os.path.join(output_folder, f"frame_{int(frame_time)}_{i}.png")
# 保存帧
from PIL import Image
Image.fromarray(frame).save(frame_filename)
# 关闭视频文件
clipped_video.close()
video.close()
print(f"Frames have been saved in {output_folder}")
最后文件夹:

三.detectron2识别获取人的坐标
1.设置存放识别后照片的路径
我的detectron2装好以后,新建img文件夹,路径如下
C:\detectron2-main\detectron2\img2.新建文件夹original和detection
3.把裁剪出来的2_images文件夹中的图片放入original
4.获取识别后的图和坐标
在此路径下新建py文件,myvia.py,然后用一下代码获取坐标的csv,导出人类候选框为via格式。(本人电脑无独显,有独显的记得修改)同时代码修改文件夹的路径到\img\original。
#cfg.MODEL.DEVICE='cpu'
# Copyright (c) Facebook, Inc. and its affiliates.
# Copyright (c) Facebook, Inc. and its affiliates.
import argparse
import glob
import multiprocessing as mp
import os
import time
import cv2
import tqdm
import os
import csv
import pandas as pd # 导入pandas包
import re
from detectron2.config import get_cfg
from detectron2.data.detection_utils import read_image
from detectron2.utils.logger import setup_logger
from predictor import VisualizationDemo
# constants
WINDOW_NAME = "COCO detections"
def setup_cfg(args):
cfg = get_cfg()
cfg.merge_from_file(args.config_file)
cfg.merge_from_list(args.opts)
cfg.MODEL.RETINANET.SCORE_THRESH_TEST = args.confidence_threshold
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = args.confidence_threshold
cfg.MODEL.PANOPTIC_FPN.COMBINE.INSTANCES_CONFIDENCE_THRESH = args.confidence_threshold
cfg.MODEL.DEVICE = "cpu"
cfg.freeze()
return cfg
def get_parser():
parser = argparse.ArgumentParser(description="Detectron2 demo for builtin configs")
parser.add_argument("--config-file", default="C:/detectron2-main/configs/quick_schedules/mask_rcnn_R_50_FPN_inference_acc_test.yaml", metavar="FILE", help="path to config file")
parser.add_argument("--webcam", action="store_true", help="Take inputs from webcam.")
parser.add_argument("--video-input", help="Path to video file.")
parser.add_argument("--input", nargs="+", help="A list of space separated input images; or a single glob pattern such as 'directory/*.jpg'")
parser.add_argument("--output", help="A file or directory to save output visualizations. If not given, will show output in an OpenCV window.")
parser.add_argument("--confidence-threshold", type=float, default=0.5, help="Minimum score for instance predictions to be shown")
parser.add_argument("--opts", help="Modify config options using the command-line 'KEY VALUE' pairs", default=[], nargs=argparse.REMAINDER)
return parser
if __name__ == "__main__":
mp.set_start_method("spawn", force=True)
args = get_parser().parse_args()
setup_logger(name="fvcore")
logger = setup_logger()
logger.info("Arguments: " + str(args))
# 图片的输入和输出文件夹
imgOriginalPath = 'C:/detectron2-main/detectron2/img/original'
imgDetectionPath = 'C:/detectron2-main/detectron2/img/detection'
# 确保输出目录存在
if not os.path.exists(imgDetectionPath):
os.makedirs(imgDetectionPath)
# 提前定义 imgInputPaths
imgInputPaths = []
# 读取文件下的图片名字
for i, j, k in os.walk(imgOriginalPath):
for namek in k:
# 使用 os.path.join 拼接文件路径
imgInputPath = os.path.join(imgOriginalPath, namek)
imgInputPaths.append(imgInputPath)
# 修改 args 里的输入图片路径
args.input = imgInputPaths
# 修改 args 里的输出图片路径
args.output = imgDetectionPath
cfg = setup_cfg(args)
demo = VisualizationDemo(cfg)
# 创建 csv
csvFile = open(os.path.join(imgDetectionPath, "detection.csv"), "w+", encoding="gbk")
CSVwriter = csv.writer(csvFile)
CSVwriter.writerow(["filename", "file_size", "file_attributes", "region_count", "region_id", "region_shape_attributes", "region_attributes"])
if args.input:
if len(args.input) == 1:
args.input = glob.glob(os.path.expanduser(args.input[0]))
assert args.input, "The input path(s) was not found"
for path in tqdm.tqdm(args.input, disable=not args.output):
img = read_image(path, format="BGR")
start_time = time.time()
predictions, visualized_output = demo.run_on_image(img)
mask = predictions["instances"].pred_classes == 0
pred_boxes = predictions["instances"].pred_boxes.tensor[mask]
ImgNameT = re.findall(r'[^\\/:*?"<>|\r\n]+$', path)
ImgName = ImgNameT[0]
ImgSize = os.path.getsize(path)
img_file_attributes = "{}"
img_region_count = len(pred_boxes)
region_id = 0
img_region_attributes = "{}"
for i in pred_boxes:
iList = i.cpu().numpy().tolist()
img_region_shape_attributes = {"\"name\"": "\"rect\"", "\"x\"": int(iList[0]), "\"y\"": int(iList[1]), "\"width\"": int(iList[2] - iList[0]), "\"height\"": int(iList[3] - iList[1])}
CSVwriter.writerow([ImgName, ImgSize, '"{}"', img_region_count, region_id, str(img_region_shape_attributes), '"{}"'])
region_id += 1
logger.info("{}: {} in {:.2f}s".format(path, "detected {} instances".format(len(predictions["instances"])) if "instances" in predictions else "finished", time.time() - start_time))
if args.output:
if os.path.isdir(args.output):
assert os.path.isdir(args.output), args.output
out_filename = os.path.join(args.output, os.path.basename(path))
visualized_output.save(out_filename)
csvFile.close()
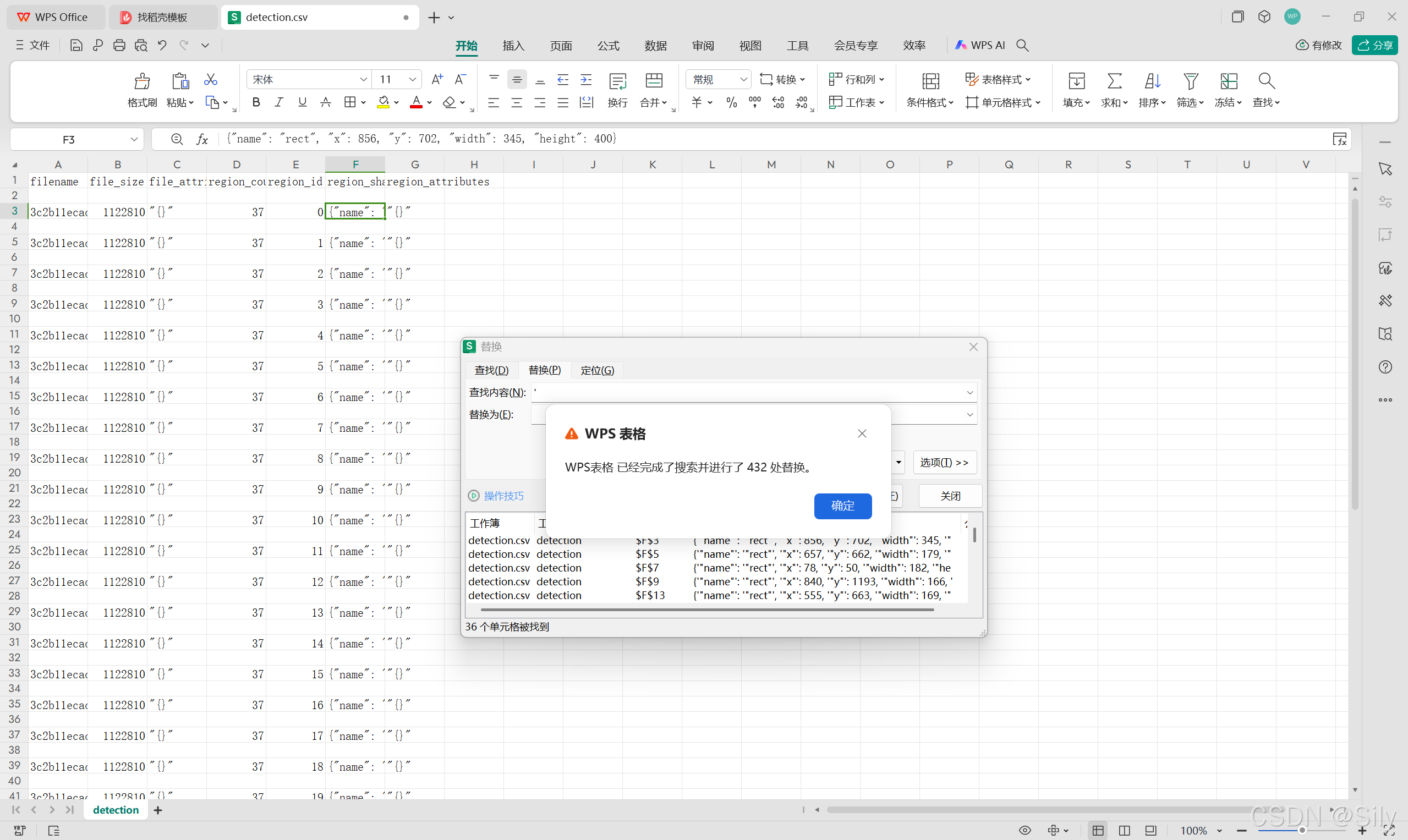
这一步运行以后我们可以得到初步的识别效果,最后照片在detection中,附带有坐标的detectin.csv也在其中。
 裁剪进度差不多是这样,有些图片不方便公示,所以我先举个例子裁剪一张图片。
裁剪进度差不多是这样,有些图片不方便公示,所以我先举个例子裁剪一张图片。
 看看detectron2做出的识别这张图片还是很不错的。
看看detectron2做出的识别这张图片还是很不错的。
打开文件夹中的csv,替换所以的单引号为空格
5.打开via查看框人效果或修改
点此下载via,,选择最上面下载就可以了
下载完成后,点击下面这个进入网页
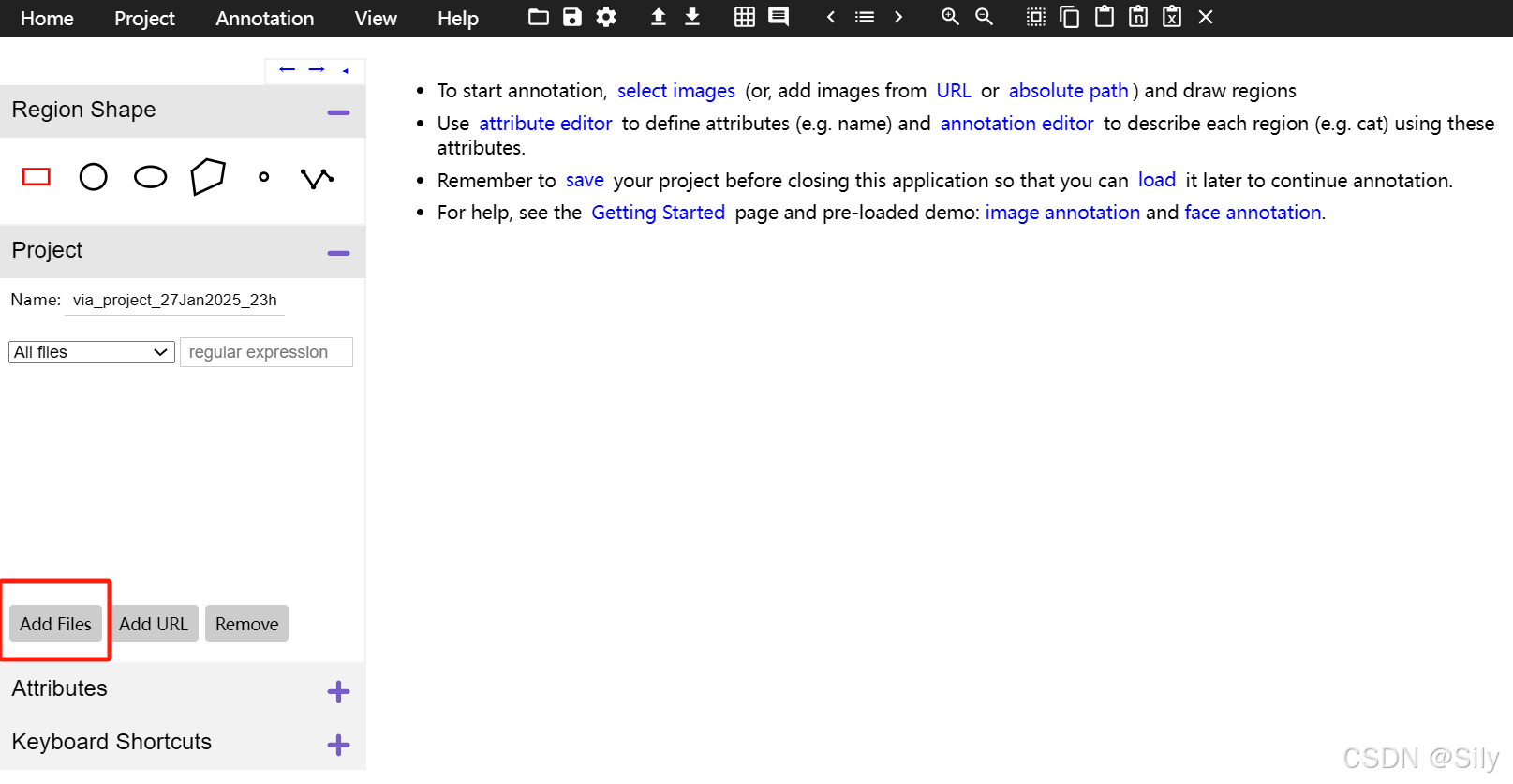
进入是这个样子,在add files中添加我们original文件夹中的文件。
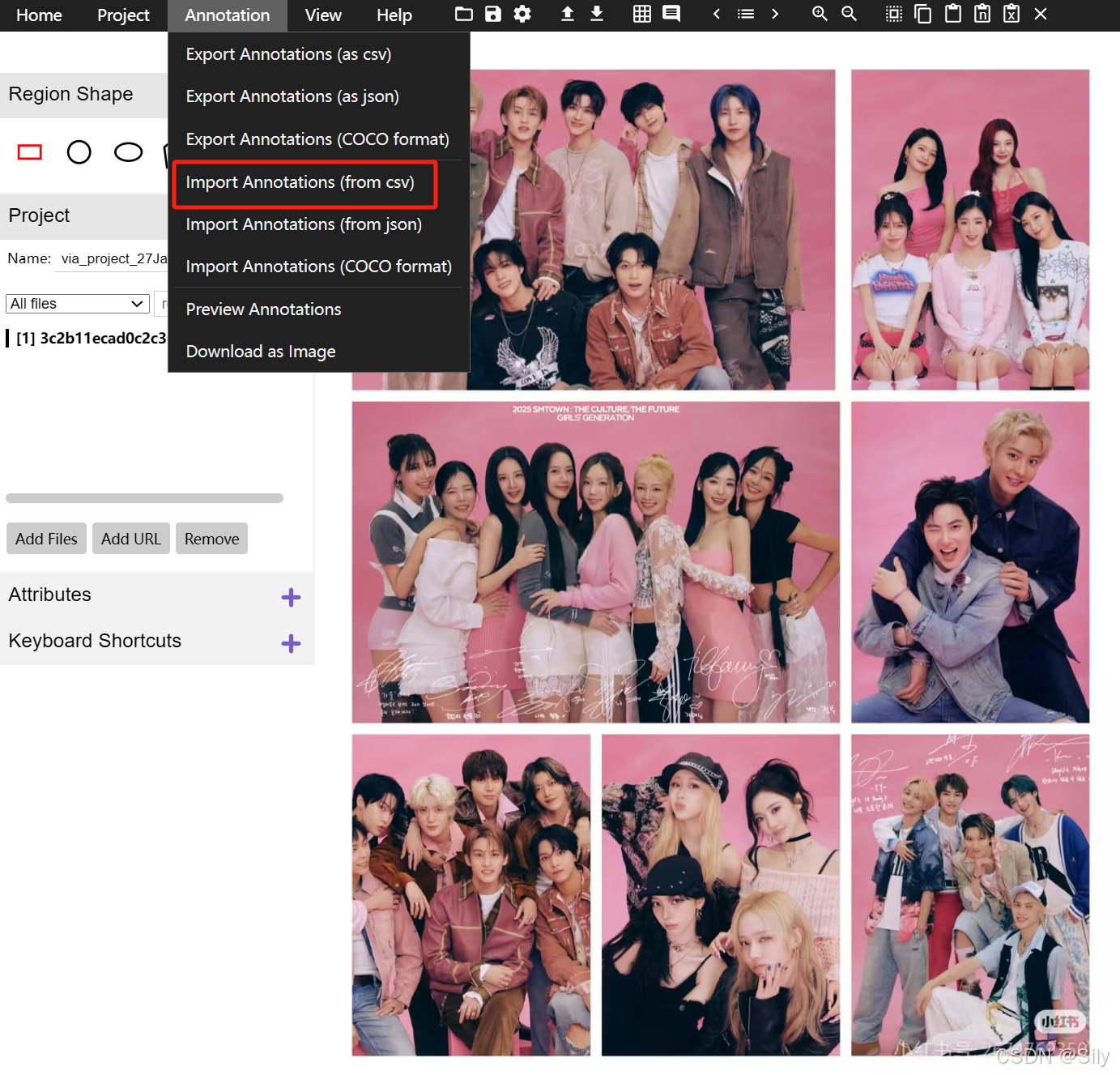
添加好以后,上传我们刚刚修改的csv文件
6.手动修改框子
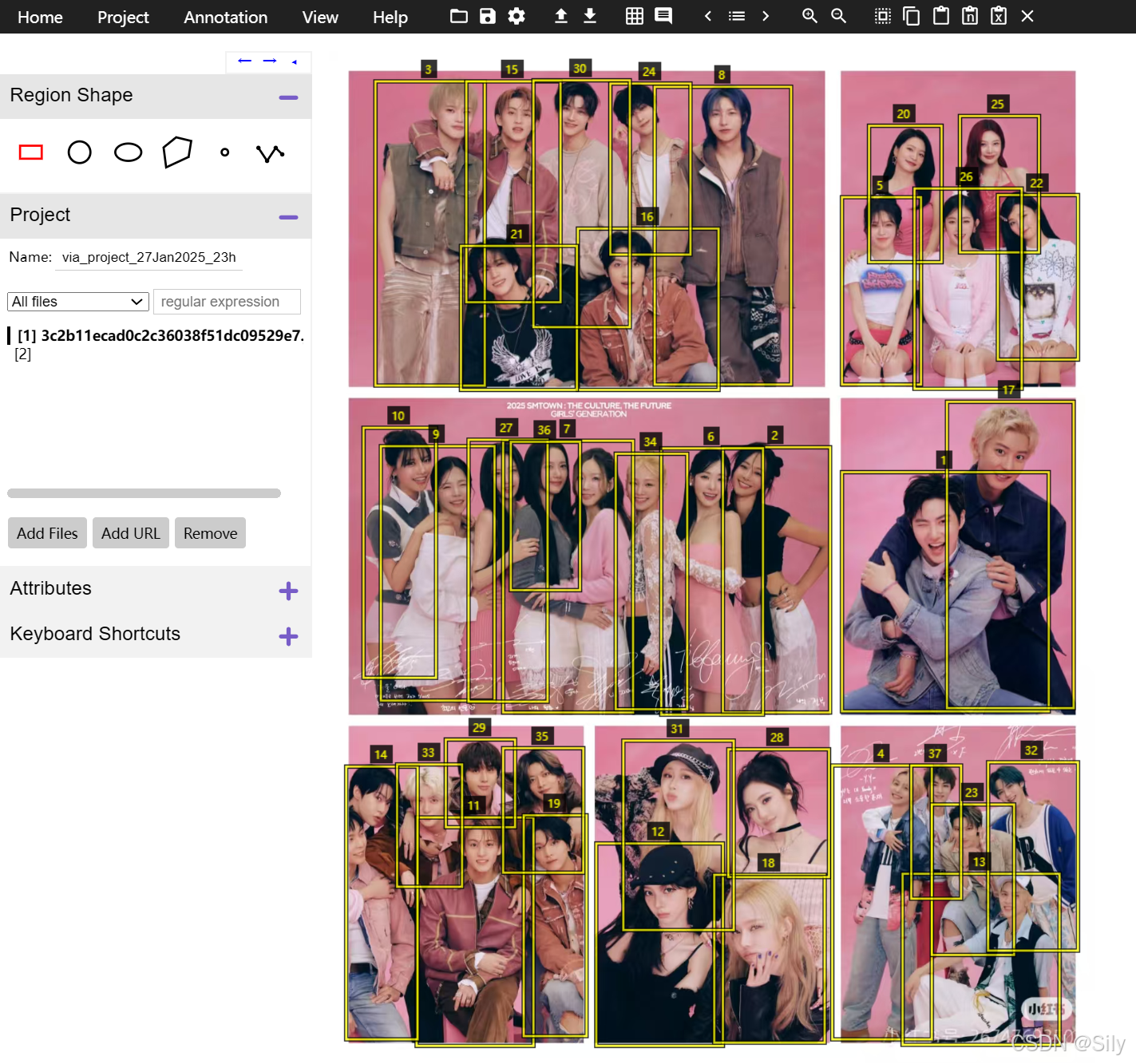
导入文件后就是这样,可以根据自己的需求修改。因为这张图片本来拍的就很好,不太存在识别不上人的问题,教室监控记录下的视频经常会有犄角旮旯或者人衣服颜色相近或者学生一动不动,存在无法识别的情况,那就根据自己需求用鼠标框即可,选中框子,右上角的×也可以删除。
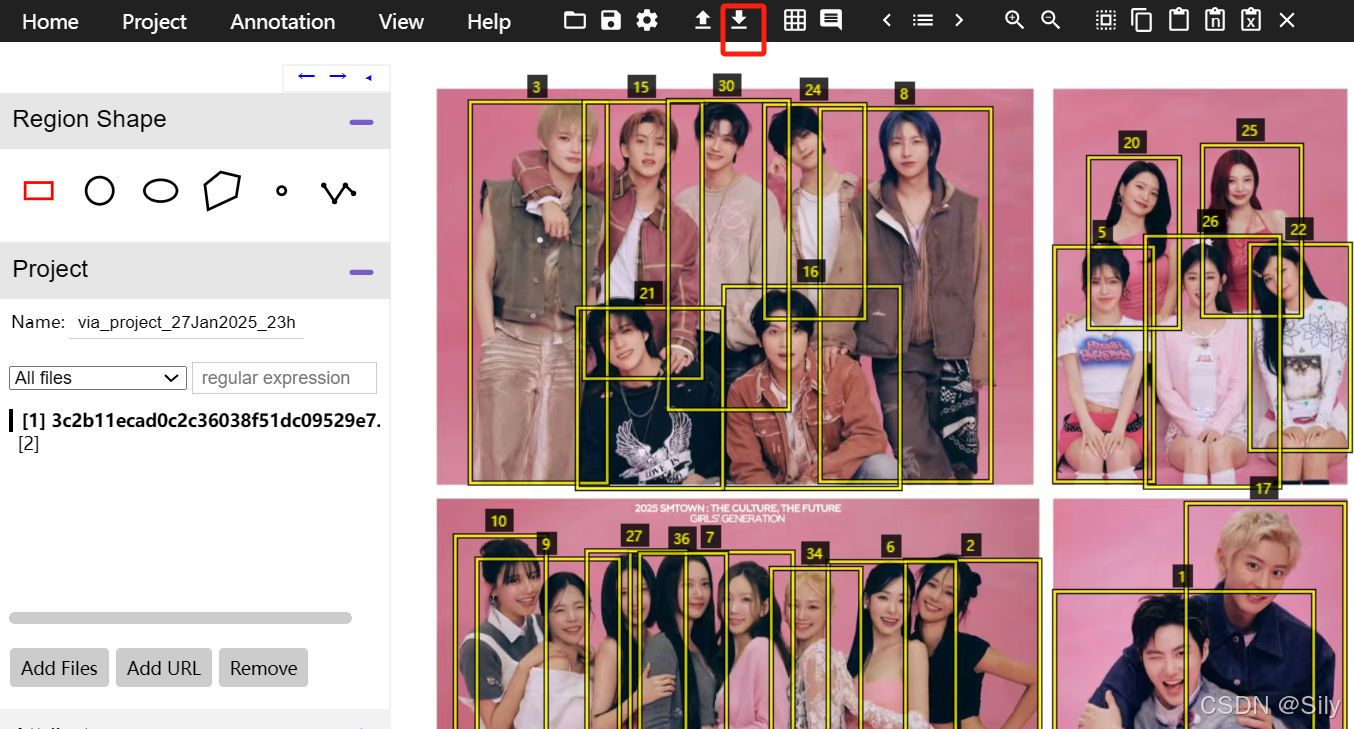 左边是图片名称,上下滑动选择插入图片。框完以后,点击右上角向下👇的箭头,就可以得到修正过的坐标。
左边是图片名称,上下滑动选择插入图片。框完以后,点击右上角向下👇的箭头,就可以得到修正过的坐标。
那么slowfast的数据集基本上就这样完成了。

















 2132
2132

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









