






Pytorch实现cifar10多分类
数据集说明
CIFAR-10数据集由10个类的60000个32x32彩色图像组成,每个类有6000个图像。有50000个训练图像和10000个则试图像。
数据集分为5个训练批次和1个测试批次,每个批次有10000个图像。测试批次包含来自每个类别的恰好1000个随机选择的图像。训练批次以随机顺序选取剩余图像,但一些训练批次可能更多会选取来自一个类别的图像。总体来说,五个训练集之和包含来自每个类的正好5000张图像。图6-27显示了数据集中涉及的10个类,以及来自每个类的10个随机图像。

这10类都是彼此独立的,不会出现重要,即这是多分类单标签问题
构建网络
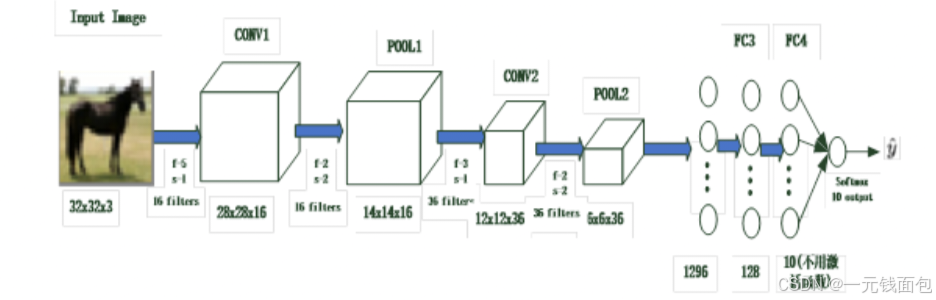
输入层(Input Image):输入是一张大小为32×32像素的彩色图像(通道数为3),比如图中的马的图像。
卷积层(CONV):
CONV1:使用16个滤波器(filters),滤波器大小(kernel_size)为5×5,步长(stride)为1,对输入图像进行卷积操作,输出特征图大小变为28×28,通道数变为16。
CONV2:以CONV1的输出作为输入,使用36个滤波器,滤波器大小为3×3,步长为1,输出特征图大小变为12×12,通道数变为36 。
池化层(POOL):
POOL1:采用最大池化(Max Pooling),池化核大小为2×2,步长为2,对CONV1的输出进行降采样,输出特征图大小变为14×14,通道数保持16不变。
POOL2:对CONV2的输出进行最大池化,同样池化核大小为2×2,步长为2,输出特征图大小变为6×6,通道数保持36不变。
全连接层(FC):
FC3:将POOL2输出的特征图(6×6×36,即1296个神经元)展开后作为输入,输出128个神经元
FC4:以FC3的输出作为输入,输出10个神经元,对应CIFAR - 10数据集中的10个类别,最后通过Softmax函数(图中提及“10(不用激活函数)”有误,通常此处需要Softmax来计算类别概率)得到每个类别的预测概率 。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









