







- 基于网页文档内容的提取方法
- 基于 DOM 结构信息的提取方法
- 基于视觉信息的提取方法
业界进展
未来的话,页面也会越来越多,页面的渲染方式也会发生很大的变化,爬虫也会越来越难做,智能化爬虫也将会变得越来越重要。
目前工业界,其实已经有落地的算法应用了。经过我的一番调研,目前发现有这么几种算法或者服务对页面的智能化解析做的比较好:
- Diffbot,国外的一家专门来做智能化解析服务的公司,https://www.diffbot.com
- Boilerpipe,Java 语言编写的一个页面解析算法,https://github.com/kohlschutter/boilerpipe
- Embedly,提供页面解析服务的公司,https://embed.ly/extract
- Readability,是一个页面解析算法,但现在官方的服务已经关闭了,https://www.readability.com/
- Mercury,Readability 的替代品,https://mercury.postlight.com/
- Goose,Java 语音编写的页面解析算法,https://github.com/GravityLabs/goose
那么这几种算法或者服务到底哪些好呢,Driffbot 官方曾做过一个对比评测,使用 Google 新闻的一些文章,使用不同的算法依次摘出其中的标题和文本,然后与真实标注的内容进行比较,比较的指标就是文字的准确率和召回率,以及根据二者计算出的 F1 分数。
其结果对比如下:
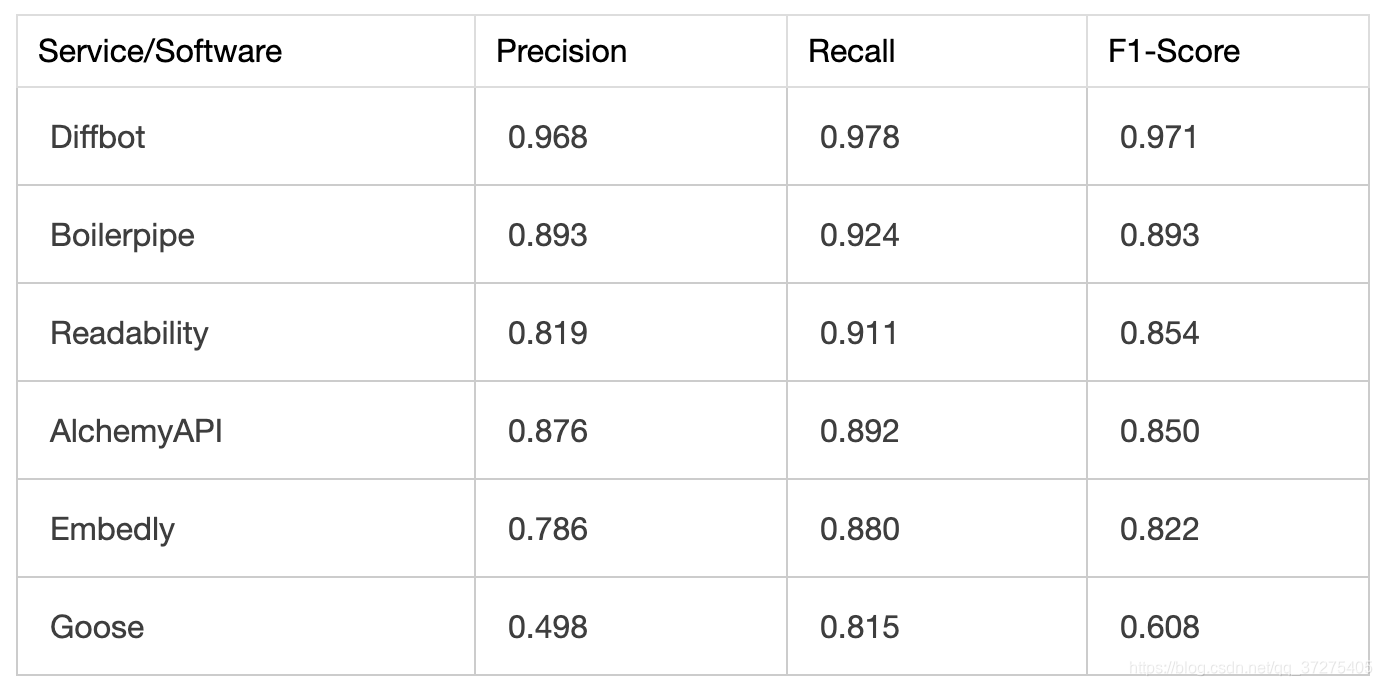
经过对比我们可以发现,Diffbot 的准确率和召回率都独占鳌头,其中的 F1 值达到了 0.97,可以说准确率非常高了。另外接下来比较厉害的就是 Boilerpipe 和 Readability,Goose 的表现则非常差,F1 跟其他的算法差了一大截。下面是几个算法的 F1 分数对比情况:
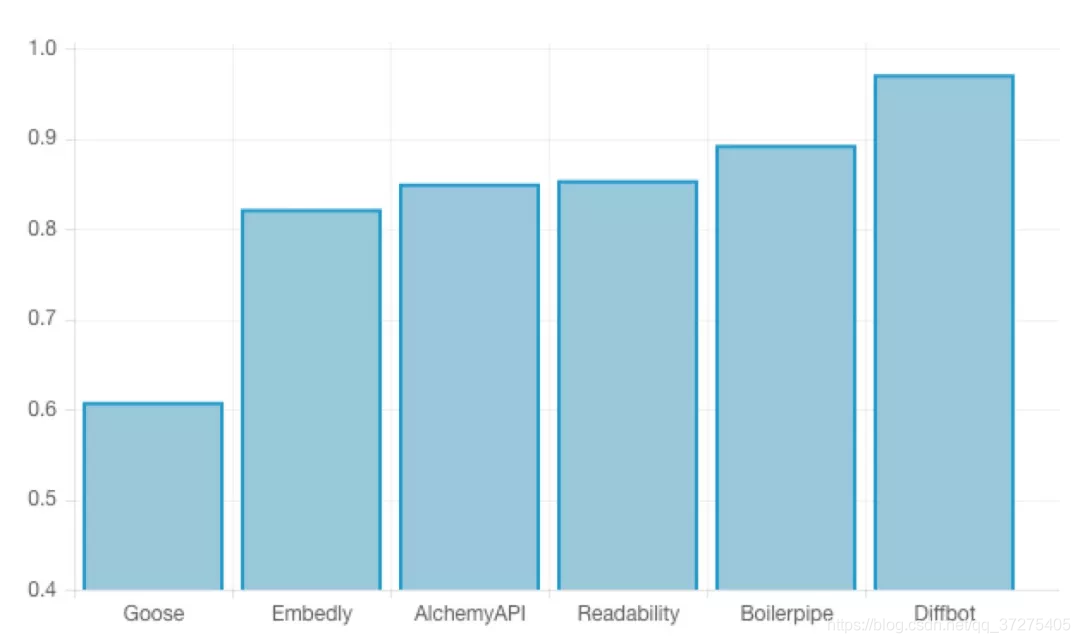
有人可能好奇为什么 Diffbot 这么厉害?我也查询了一番。Diffbot 自 2010 年以来就致力于提取 Web 页面数据,并提供许多 API 来自动解析各种页面。其中他们的算法依赖于自然语言技术、机器学习、计算机视觉、标记检查等多种算法,并且所有的页面都会考虑到当前页面的样式以及可视化布局,另外还会分析其中包含的图像内容、CSS 甚至 Ajax 请求。另外在计算一个区块的置信度时还考虑到了和其他区块的关联关系,基于周围的标记来计算每个区块的置信度。
总之,Diffbot 也是一直致力于这一方面的服务,整个 Diffbot 就是页面解析起家的,现在也一直专注于页面解析服务,准确率高也就不足为怪了。
但它们的算法开源了吗?很遗憾,并没有,而且我也没有找到相关的论文介绍它们自己的具体算法。
所以,如果想实现这么好的效果,那就使用它们家的服务就好了。
Diffbot 页面解析
首先我们需要注册一个账号,它有 15 天的免费试用,注册之后会获得一个 Developer Token,这就是使用 Diffbot 接口服务的凭证。
接下来切换到它的测试页面中,链接为:https://www.diffbot.com/dev/home/,我们来测试一下它的解析效果到底是怎样的。
这里我们选择的测试页面就是上文所述的页面,链接为:https://news.ifeng.com/c/7kQcQG2peWU,API 类型选择 Article API,然后点击 Test Drive 按钮,接下来它就会出现当前页面的解析结果:
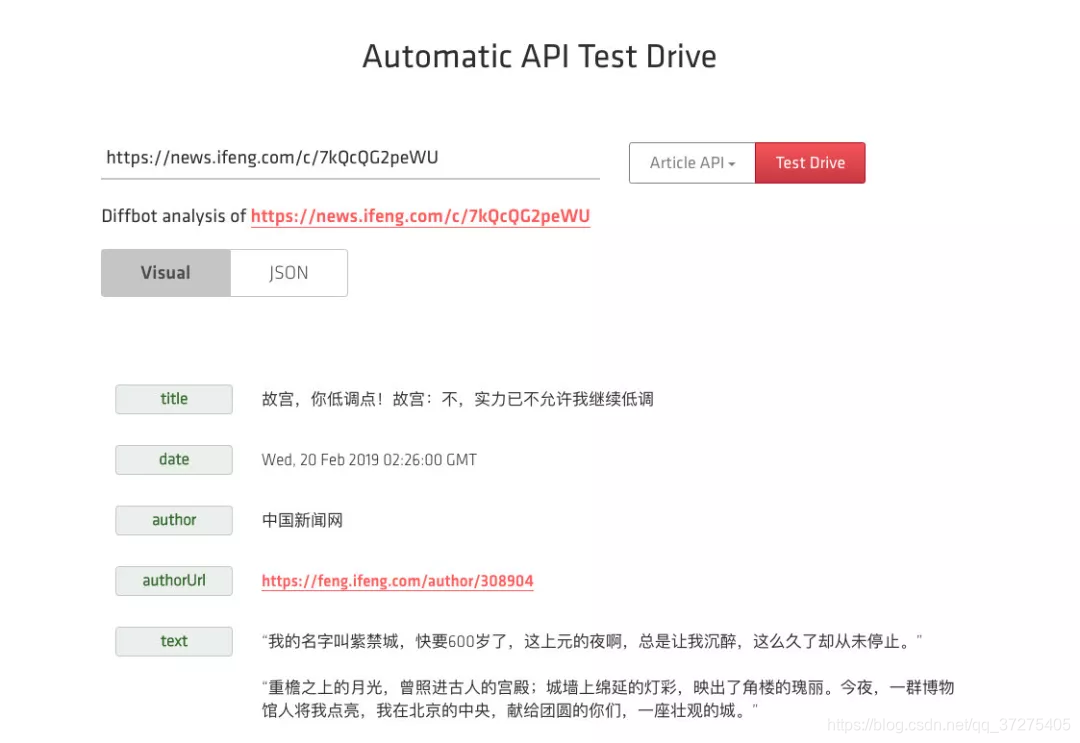
这时候我们可以看到,它帮我们提取出来了标题、发布时间、发布机构、发布机构链接、正文内容等等各种结果。而且目前来看都十分正确,时间也自动识别之后做了转码,是一个标准的时间格式。
接下来我们继续下滑,查看还有什么其他的字段,这里我们还可以看到有 html 字段,它和 text 不同的是,它包含了文章内容的真实 HTML 代码,因此图片也会包含在里面,如图所示:

另外最后面还有 images 字段,他以列表形式返回了文章套图及每一张图的链接,另外还有文章的站点名称、页面所用语言等等结果,如图所示:
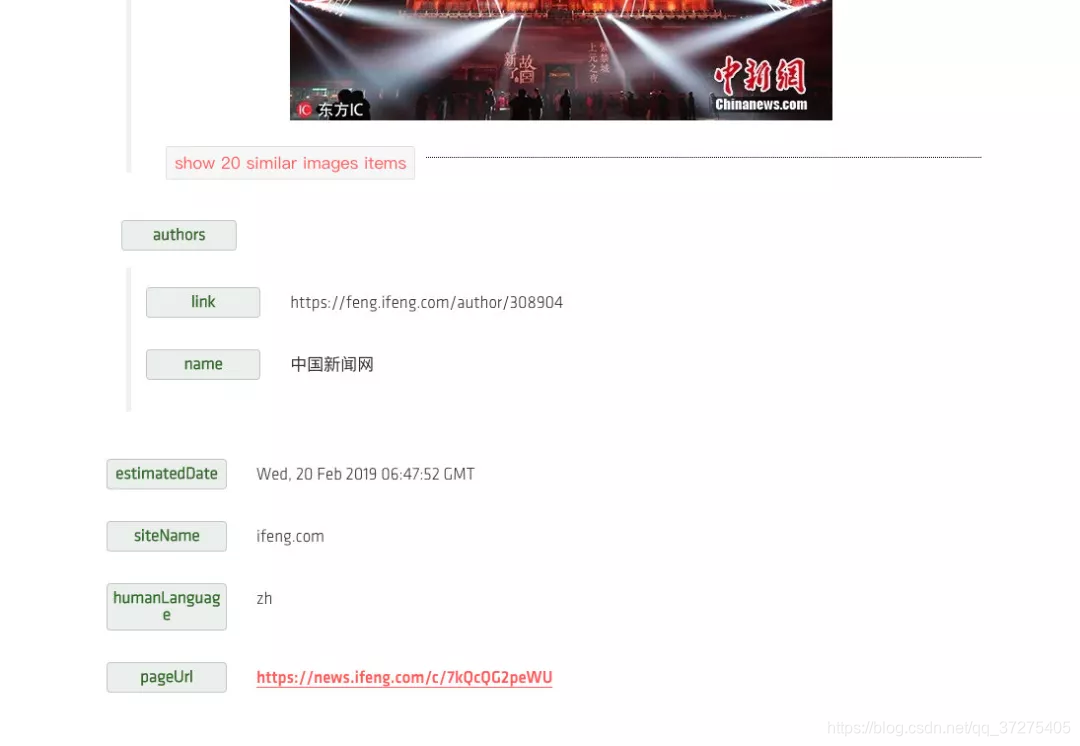
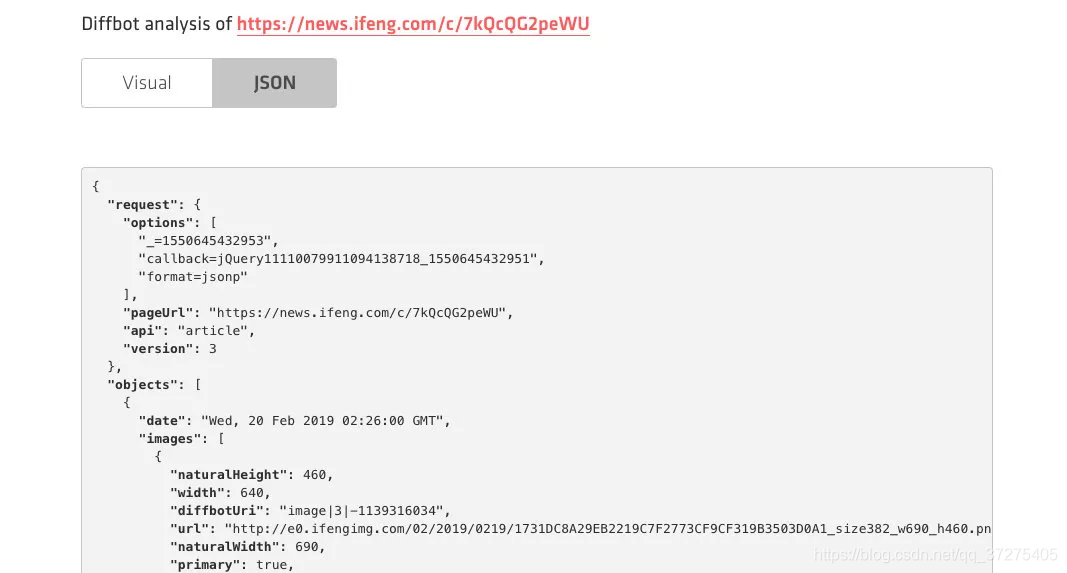
当然我们也可以选择 JSON 格式的返回结果,其内容会更加丰富,例如图片还返回了其宽度、高度、图片描述等等内容,另外还有各种其他的结果如面包屑导航等等结果,如图所示:
经过手工核对,发现其返回的结果都是完全正确的,准确率相当之高!
所以说,如果你对准确率要求没有那么非常非常严苛的情况下,使用 Diffbot 的服务可以帮助我们快速地提取页面中所需的结果,省去了我们绝大多数的手工劳动,可以说是非常赞了。
但是,我们也不能总在网页上这么试吧。其实 Diffbot 也提供了官方的 API 文档,让我们来一探究竟。
Diffbot API
Driffbot 提供了多种 API,如 Analyze API、Article API、Disscussion API 等。
下面我们以 Article API 为例来说明一下它的用法,其官方文档地址为:https://www.diffbot.com/dev/docs/article/,API 调用地址为:
https://api.diffbot.com/v3/article
我们可以用 GET 方式来进行请求,其中的 Token 和 URL 都可以以参数形式传递给这个 API,其必备的参数有:
- token:即 Developer Token
- url:即要解析的 URL 链接
另外它还有几个可选参数:
- fields:用来指定返回哪些字段,默认已经有了一些固定字段,这个参数可以指定还可以额外返回哪些可选字段
- paging:如果是多页文章的话,如果将这个参数设置为 false 则可以禁
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









