







嘿嘿,规划好自己需要的数据,就可以开始进行页面分析了,按住F12,对页面进行一顿刷新,刷新,刷新,看Network中的页面数据加载情况,一个个找,哐的一下你发现一个listBrief?pageNum=1&pageSize...,这就是缘分啊,数据都在这里。 点开Headers查看Request URL,你会发现,这竟然是一个数据接口,舒服呀~
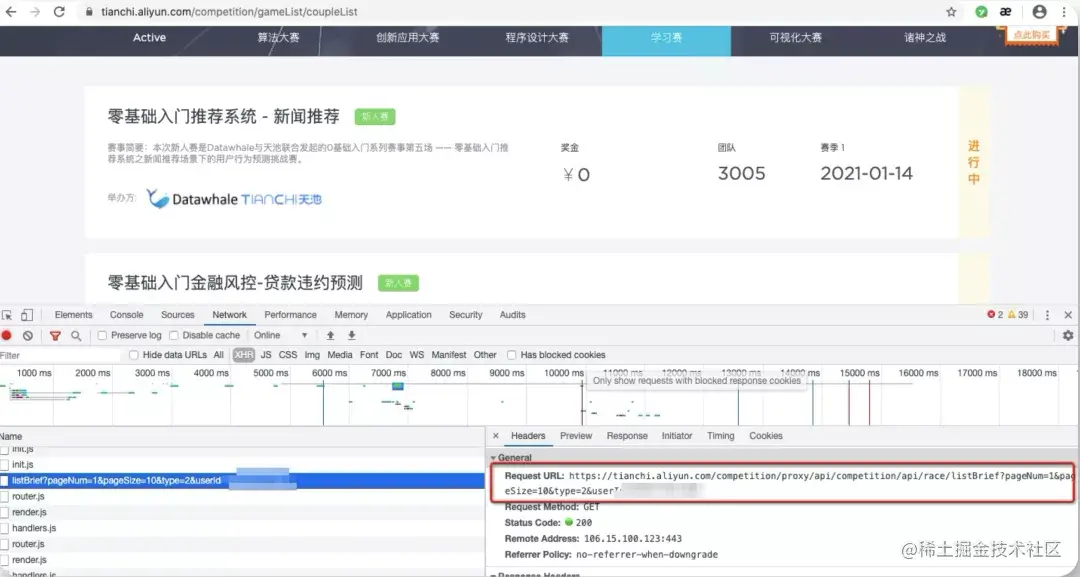
这样的话,数据获取起来就简单多了~!

2.2 写几行代码
先导入一系列需要用到的包~
'''
爬取阿里云旗下大数据平台天池的 学习赛有哪些,及相关数据
地址:https://tianchi.aliyun.com/competition/gameList/coupleList
'''
import warnings
warnings.filterwarnings("ignore")
# 忽略警告
import requests
# 导入页面请求模块
from fake_useragent import UserAgent
# 导入随机生成请求头的模块
import json
# 导入json数据处理包
import pandas as pd
# 导入数据处理模块
import pymysql
# 导入数据库处理模块
复制代码
如果运行发现no module name,直接pip insatll 即可,不用客气。
'''
爬取数据
'''
def get_data():
# 请求头
headers = {
"User-Agent": UserAgent(verify_ssl=False,use_cache_server=False).random
}
# 存储数据用的列表
csv_data = []
# 表头,自己需要的数据项
head_csv = ['raceName', 'raceId', 'brief', 'currentSeasonStart', 'currentSeasonEnd', 'raceState', 'teamNum', 'type', 'currency', 'currencySymbol']
# 经过页面分析一共有4页,32条数据,循环爬取
for i in range(1,5):
# 经过页面分析找到的数据api及规律
competition_api = 'https://tianchi.aliyun.com/competition/proxy/api/competition/api/race/listBrief?pageNum=%d&pageSize=10&type=2'%i
# print(competition_api)
# 发送get请求
response_data = requests.get(competition_api,headers=headers)
# 将获取的到的数据转化成为json格式,然后即可像处理字典一样处理数据啦
json_dat 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 515
515

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









