




 本文介绍了如何使用Python简洁地将数据保存为CSV文件和MySQL数据库。通过pandas的to_csv方法以gbk编码保存数据,并讨论了index=False参数的重要性。此外,文章还展示了利用sqlalchemy将DataFrame保存到MySQL,强调了数据库配置、字段创建、if_exists='append'选项以及index=False的使用技巧。
本文介绍了如何使用Python简洁地将数据保存为CSV文件和MySQL数据库。通过pandas的to_csv方法以gbk编码保存数据,并讨论了index=False参数的重要性。此外,文章还展示了利用sqlalchemy将DataFrame保存到MySQL,强调了数据库配置、字段创建、if_exists='append'选项以及index=False的使用技巧。
分享写入csv文件和写入mysql的方法,编码工作我一向追求代码的简单性,今天分享的也不例外
之前介绍过一篇文章,用pandas读取几种常见文件,有兴趣可以看看
人生苦短,我用pandas一行代码读取4种常见文件
数据我就按比较常见的列表嵌套字典来演示了,这种数据结构也是在各个场景下经常用到的数据结构[{},{},{}…]
import pandas as pd
data = [
{"name":"张三","age":18,"city":"北京"},
{"name":"李四","age":19,"city":"上海"},
{"name":"王五","age":20,"city":"广州"},
{"name":"赵六","age":21,"city":"深圳"},
{"name":"孙七","age":22,"city":"武汉"}
]
用pandas将数据转换成行列Dataframe数据类型
df = pd.DataFrame(data,columns=["name","age","city"])
print(df)
name age city
0 张三 18 北京
1 李四 19 上海
2 王五 20 广州
3 赵六 21 深圳
4 孙七 22 武汉
一、保存CSV
用to_csv方法仅需一行代码即可保存成功
df.to_csv("csv_file.csv",encoding="gbk",index=False)
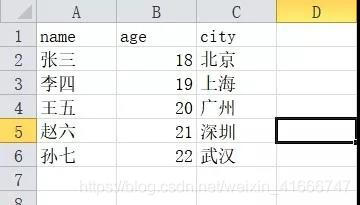
注意事项:
1、一般情况下我们用utf-8编码进行保存,如果出现中文编码错误,则可以依次换用gbk,gb2312 , gb18030,一般总能成功的,本例中用gbk
2、to_csv方法,具体参数还有很多,可以去看官方文档,这里提到一个index = False参数,表示保存csv的时候,我们不保存pandas 的Data frame的行索引1234这样的序号,默认情况不加的话是index = True,会有行号(如下图),这点在保存数据库mysql的时候体现尤其明显,不注意的话可能会出错
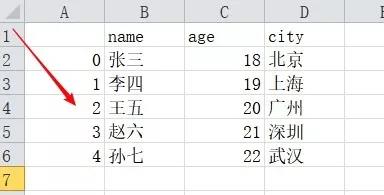
二、保存msyql
from sqlalchemy import create_engine
db_flag = "mysql"
host_ip = "127.0.0.1"
host_port = 3306
db_name = "centos_test"
table_name = "aaa"
user = "root"
pawd = "123456789"
charset = "utf-8"
engine_config = '%s%s%s%s%s%s%s%s%s%s%s' % ('mysql+pymysql://', user, ':', pawd, '@', host_ip, ':',host_port, '/', db_name,'?charset=utf8')
print(engine_config)
engine = create_engine(engine_config)
conn = engine.connect()
df.to_sql( table_name, conn, if_exists='append',index=False)

上面代码已经实现将我们构造的df数据保存MySQL,现在提一些注意点
注意事项:
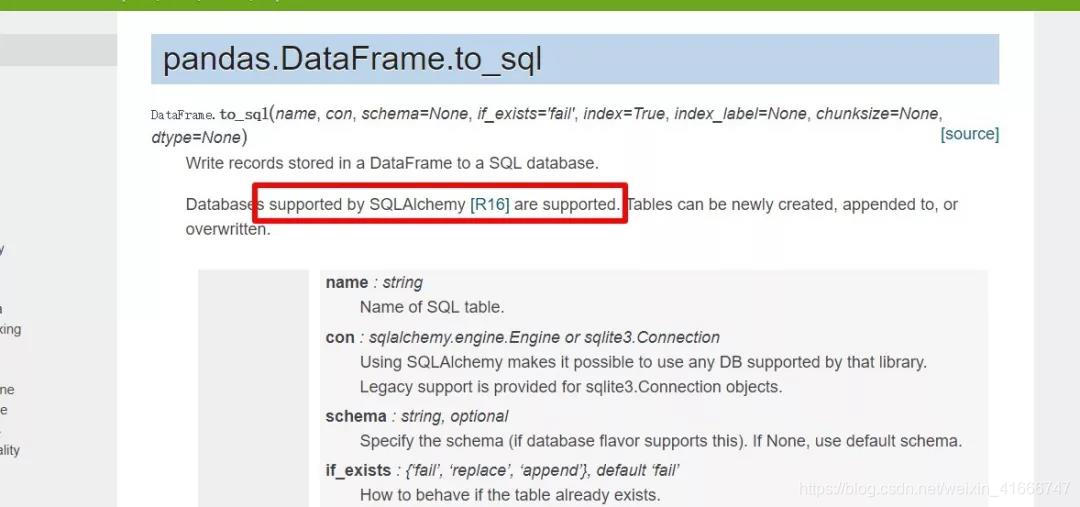
1、我们用的库是sqlalchemy,官方文档提到to_sql是被sqlalchemy支持
文档地址:
http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.to_sql.html
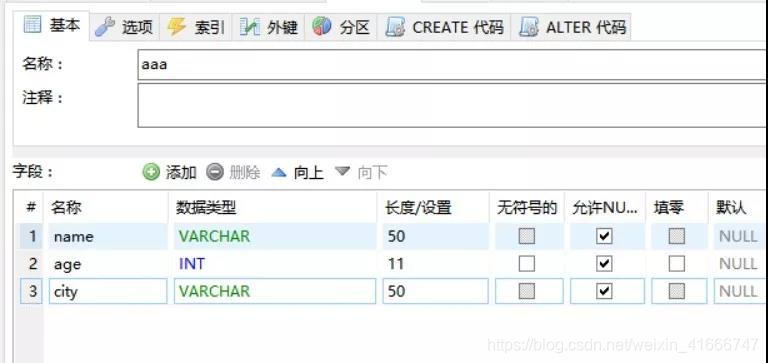
2、数据库配置用你自己的数据库配置,db_flag为数据库类型,根据不同情况更改,在保存数据之前,要先创建数据库字段,下图是我这边简单创建的字段
3、engine_config为数据库连接配置信息,按照我上面的方式构造就行了打印出来如下图
mysql+pymysql://root:123456789@127.0.0.1:3306/centos_test?charset=utf8
4、create_engine是根据数据库配置信息创建连接对象
5、if_exists = ‘append’,追加数据
6、index = False 保存时候,不保存df的行索引,这样刚好df的3个列和数据库的3个字段一一对应,正常保存,如果不设置为false的话,数据相当于4列,跟MySQL 3列对不上号,会报错
这里提个小问题,比如我们想在遍历的时候来一条数据,保存一条,而不是整体生成Dataframe后才保存,该怎么做?上面提到if_exists,可以追加,用这个即可实现,包括保存csv同样也有此参数,可以参考官方文档
python爬虫人工智能大数据公众号:


















 400
400

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









