







题目描述
如题,给定一棵有根多叉树,请求出指定两个点直接最近的公共祖先。
输入格式
第一行包含三个正整数 N,M,S,分别表示树的结点个数、询问的个数和树根结点的序号。
接下来 N−1 行每行包含两个正整数 x,y,表示 x 结点和 y 结点之间有一条直接连接的边(数据保证可以构成树)。
接下来 M 行每行包含两个正整数 a,b,表示询问 a 结点和 b 结点的最近公共祖先。
输出格式
输出包含 M 行,每行包含一个正整数,依次为每一个询问的结果。
输入输出样例
输入 #1
5 5 4
3 1
2 4
5 1
1 4
2 4
3 2
3 5
1 2
4 5输出 #1
4
4
1
4
4说明/提示
对于 30% 的数据,N ≤ 10,M ≤ 10。
对于 70% 的数据,N ≤ 10000,M ≤ 10000。
对于 100% 的数据,1 ≤ N, M ≤ 500000,1 ≤ x, y, a, b ≤ N,不保证 。
样例说明:
该树结构如下:
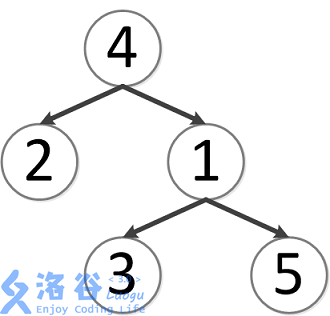
第一次询问:2,4 的最近公共祖先,故为 4。
第二次询问:3,2 的最近公共祖先,故为 4。
第三次询问:3,5 的最近公共祖先,故为 1。
第四次询问:1,2 的最近公共祖先,故为 4。
第五次询问:4,5 的最近公共祖先,故为 4。
故输出依次为 4, 4, 1, 4, 4。
算法思路:
-
预处理:通过深度优先搜索(DFS)记录每个节点的深度和直接父节点。
-
倍增表:构建一个
up表,其中up[k][u]表示节点u的第级祖先。
-
查询LCA:
-
将两个节点调整到同一深度。
-
同时向上跳跃,直到找到最近的公共祖先。
-
代码实现:
#include <bits/stdc++.h>
#define int long long
using namespace std;
vector<vector<int> > adj; // 邻接表
vector<int> depth; // 节点深度
vector<vector<int> > up; // 倍增表
inline int read() {register int x = 0, t = 1;register char ch = getchar();while(ch < '0' || ch > '9') {if(ch == '-')t -= 1;ch = getchar();}while(ch >= '0' && ch <= '9') {x = x * 10 + ch - '0';ch = getchar(); }return x * t;}
void dfs(int u, int p) {
up[0][u] = p;
for (int i = 0; i < adj[u].size(); i++) { // 改用下标遍历
int v = adj[u][i];
if (v != p) {
depth[v] = depth[u] + 1;
dfs(v, u);
}
}
}
// LCA查询
int lca(int u, int v) {
if (depth[u] < depth[v]) swap(u, v);
// 对齐深度
int k_max = up.size();
for (int k = k_max-1; k >= 0; k--) {
if (depth[u] - (1 << k) >= depth[v]) {
u = up[k][u];
}
}
if (u == v) return u;
// 同步上跳
for (int k = k_max-1; k >= 0; k--) {
if (up[k][u] != up[k][v]) {
u = up[k][u];
v = up[k][v];
}
}
return up[0][u];
}
signed main() {
int n,m;
cin >> n >> m;
int s; cin >> s;
adj.resize(n+1);
depth.resize(n+1, 0);
int LOG = log2(n) + 1;
up.resize(LOG, vector<int>(n+1));
// 建树(假设输入为n-1条边)
for (int i = 1; i < n; i++) {
int a, b;
a = read(),b = read();
adj[a].push_back(b);
adj[b].push_back(a);
}
// 预处理(根节点为s)
dfs(s, s);
for (int k = 1; k < LOG; k++) {
for (int u = 1; u <= n; u++) {
up[k][u] = up[k-1][up[k-1][u]];
}
}
// 查询示例
while (m --) {
int u, v;
u = read(),v = read();
cout << lca(u, v) << endl;
}
return 0;
}代码结构解析
全局变量
vector<vector<int>> adj; // 邻接表存储树结构
vector<int> depth; // 记录每个节点的深度
vector<vector<int>> up; // 倍增表,up[k][u]表示u的2^k级祖先-
adj:树的邻接表表示。 -
depth:存储每个节点到根节点的深度。 -
up:倍增表,用于快速跳转查找祖先。
快速输入函
-
通过逐字符读取实现快速输入,适用于大数据量。
-
处理负数(虽然本题中节点编号为正整数)。
DFS预处理
void dfs(int u, int p) {
up[0][u] = p; // 直接父节点
for (int i = 0; i < adj[u].size(); i++) {
int v = adj[u][i];
if (v != p) {
depth[v] = depth[u] + 1; // 更新子节点深度
dfs(v, u); // 递归处理子节点
}
}
}-
递归遍历树,初始化每个节点的直接父节点(
up[0][u])。 -
记录每个节点的深度(
depth[v] = depth[u] + 1)。
LCA查询
int lca(int u, int v) {
// 对齐深度
if (depth[u] < depth[v]) swap(u, v);
for (int k = up.size()-1; k >= 0; k--) {
if (depth[u] - (1 << k) >= depth[v]) {
u = up[k][u];
}
}
// 如果v是u的祖先,直接返回
if (u == v) return u;
// 同步上跳找LCA
for (int k = up.size()-1; k >= 0; k--) {
if (up[k][u] != up[k][v]) {
u = up[k][u];
v = up[k][v];
}
}
return up[0][u];
}-
深度对齐:将较深的节点
u上跳至与v同深度。 -
同步上跳:从最大步长开始,同步上跳
u和v,直到它们的父节点相同。 -
返回LCA:最终
u和v的父节点即为LCA。
主函数
int main() {
int n, m, s;
cin >> n >> m >> s;
// 初始化数据结构
adj.resize(n+1);
depth.resize(n+1, 0);
int LOG = log2(n) + 1; // 计算倍增表层数
up.resize(LOG, vector<int>(n+1));
// 构建树
for (int i = 1; i < n; i++) {
int a = read(), b = read();
adj[a].push_back(b);
adj[b].push_back(a);
}
// 预处理DFS和倍增表
dfs(s, s); // 根节点的父节点是自身
for (int k = 1; k < LOG; k++) {
for (int u = 1; u <= n; u++) {
up[k][u] = up[k-1][up[k-1][u]]; // 递推填充倍增表
}
}
// 处理查询
while (m--) {
int u = read(), v = read();
cout << lca(u, v) << endl;
}
return 0;
}-
输入处理:读取节点数
n、查询数m和根节点s。 -
初始化邻接表和倍增表。
-
构建树:读取
n-1条边,构建邻接表。 -
预处理:
-
通过DFS初始化深度和直接父节点。
-
填充倍增表
up,其中up[k][u]表示u的2^k级祖先。
-
-
查询处理:对每个查询调用
lca(u, v)并输出结果。
关键点分析
-
倍增表构建:
-
up[k][u] = up[k-1][up[k-1][u]]:利用已计算的2^(k-1)级祖先递推计算2^k级祖先。 -
复杂度:预处理
O(n log n),查询O(log n)。
-
-
深度对齐与同步上跳:
-
通过二进制拆分思想,将跳跃步长从大到小尝试,确保快速定位LCA。
-
-
根节点处理:
-
根节点的父节点设为自身,避免越界。
-
总结
该代码通过DFS预处理和倍增技术高效求解LCA问题,适用于大规模树结构查询。核心思想是通过预处理存储每个节点的多级祖先,将单次查询复杂度降至对数级。

















 412
412

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









