






Zookeeper
zookeeper是分布式应用实现高可用和容错的重要组件,提供基础的分布式协调服务、数据存储、通知和同步机制,负责存储和提供数据的一致性。zk可以用于多个分布式系统,不限于kafka。
传统模式下,zk在kafka中起到重要作用:
-
提供分布式协调服务,包括分布式数据存储、分布式锁和同步机制等。
-
提供强一致性的分布式数据存储,用于存储集群的元数据和配置信息。例如,存储Kafka的Broker列表、Topic信息、Partition状态等。
-
通过心跳机制和临时节点来检测系统故障并发送通知。当一个节点失效或重新加入时,ZooKeeper会触发相关的watch事件通知。
controller
kafka集群中的controller是负责管理和协调集群元数据的一个特殊的broker。kafka集群中只有一个活跃的controller,在kafka启动的时候由zk选出(序号最小的broker),发生故障时重新选举。
scala
代码解读
复制代码
class KafkaController(val config: KafkaConfig, val zkClient: KafkaZkClient, val time: Time, val metrics: Metrics, val metadataCache: MetadataCache, val replicaManager: ReplicaManager, val logManager: LogManager, val kafkaNetworkClient: KafkaNetworkClient, val brokerTopicStats: BrokerTopicStats, val tokenManager: DelegationTokenManager, val apiVersionManager: ApiVersionManager) extends Logging with KafkaMetricsGroup { private val partitionStateMachine: PartitionStateMachine = new PartitionStateMachine(this, zkClient, config, time) private val replicaStateMachine: ReplicaStateMachine = new ReplicaStateMachine(this, zkClient, config, time) def startup(): Unit = { // 初始化 Controller 选举 initializeControllerContext() // 其他启动逻辑 } private def initializeControllerContext(): Unit = { // 初始化 Controller 上下文 // 包括选举 Controller elect() } private def elect(): Unit = { // 创建临时顺序节点 val path = ControllerZNode.path val controllerData = new ControllerData(brokerId, config.brokerState, config.clusterId.orNull).toJson zkClient.createEphemeralPathExpectConflict(path, controllerData) } def onControllerFailover(): Unit = { // 处理 Controller 故障后的恢复逻辑 } }
zk主要作为一个高可用的数据存储和分布式协调服务,提供基础设施和机制,而controller则是具体执行各种管理和协调逻辑的核心组件。举一些具体的例子:
text
代码解读
复制代码
Kafka Broker注册和管理 Zookeeper: 提供存储机制,用于存储Broker元数据。 创建/brokers/ids/[brokerId]临时节点以存储Broker信息。 通过临时节点的机制监视Broker的在线状态。 Controller: 监听Zookeeper中Broker注册节点的变化。 检测到Broker上线或下线事件时,更新集群状态,重新分配分区Leader。 Topic和Partition管理 Zookeeper: 提供存储机制,用于存储Topic和Partition元数据。 维护/brokers/topics/[topicName]路径下的Topic和Partition信息。 Controller: 处理创建和删除Topic的请求并更新Zookeeper中的相应信息。 监控Partition信息的变化,执行Leader选举,将选举结果写入Zookeeper。 Leader选举 Zookeeper: 提供分布式锁和同步机制,帮助Kafka Controller进行选举协调。 Controller: 执行Leader选举的逻辑,确定新的Leader。 将新的Leader信息写入Zookeeper的/brokers/topics/[topicName]/partitions/[partitionId]/state路径下。 心跳检测和故障恢复 Zookeeper: 提供临时节点机制,监测Broker心跳。 当检测到心跳停止时删除对应的节点,触发通知。 Controller: 监听Zookeeper中Broker心跳节点的变化。 根据节点的消失事件进行故障恢复,包括重新选举Partition的Leader。
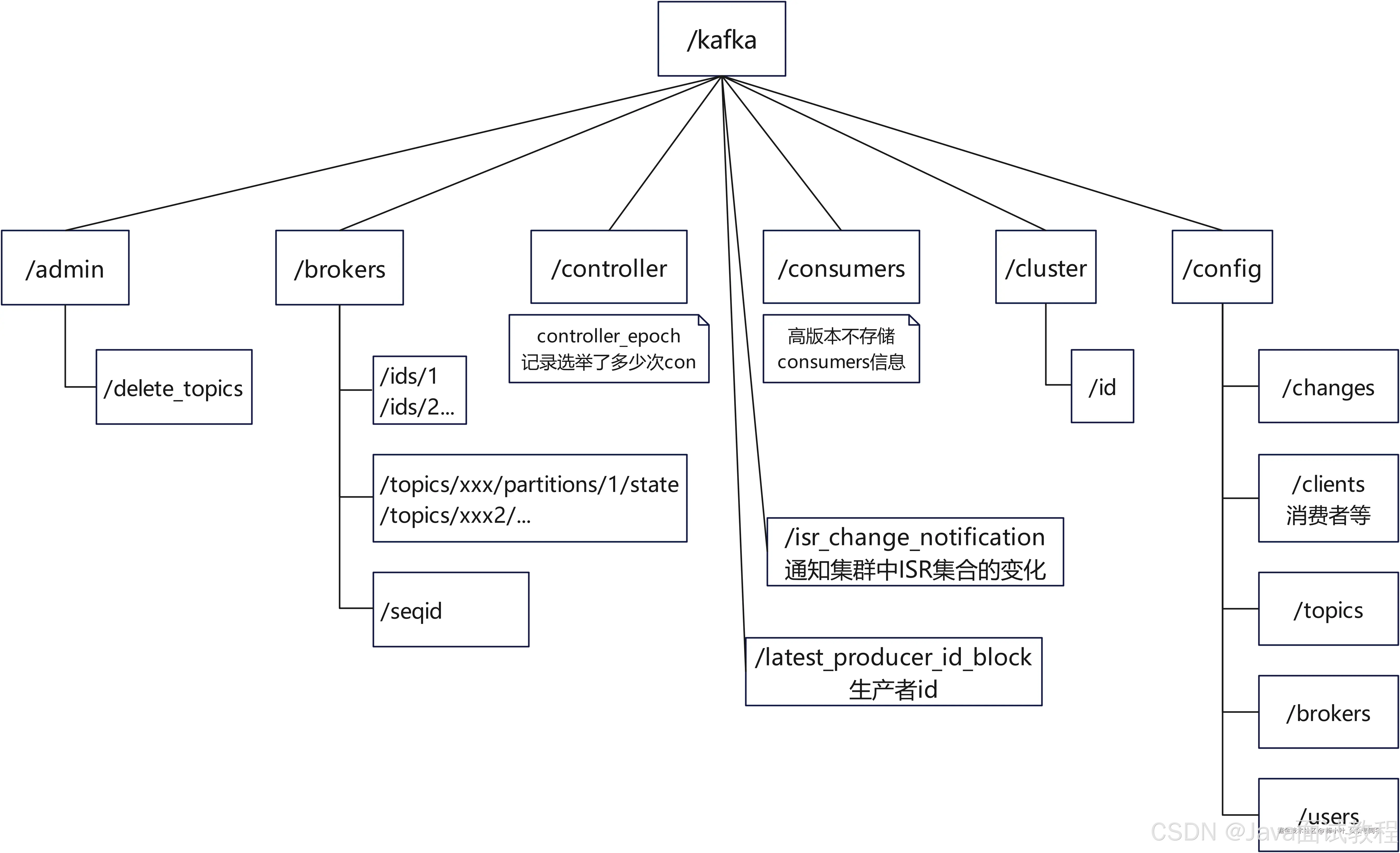
树状图
zk中存储的kafka相关的数据,也是树状分布的,如下图。
参数配置
| 参数 | 描述 |
|---|---|
Replication
在上一篇中提到,一个topic在broker集群中会有多个partition。而副本就是每个partition的数据除了一个主副本叫leader外,还会有多个copy叫follower。
leader负责处理读写请求,而follower只是从leader那里复制同步数据。为什么要这么做呢,副本的作用是提高数据的可靠性可用性,即使leader发生故障,其他的follower可以接管leader的功能。
scala
代码解读
复制代码
// 在 Kafka 源码中,副本的生成和管理主要通过 ReplicaManager 类来实现。 // ReplicaManager 负责管理每个分区的副本,包括创建、删除和同步副本。 // 具体来说,副本的创建通常在 Kafka 集群启动时或通过 Kafka 管理工具(如 kafka-topics.sh)动态添加分区时进行。 def makeFollower(topicPartition: TopicPartition, leaderAndIsr: LeaderAndIsr, isNew: Boolean): Unit = { val replica = getOrCreateReplica(topicPartition) replica.becomeFollower(leaderAndIsr.leader, leaderAndIsr.leaderEpoch, isNew) } // 副本之间数据同步通过Fetcher和Log实现,Fetcher从leader拉取数据,Log将数据写入本地磁盘,follower读取。 def fetch(topicPartition: TopicPartition, offset: Long, maxBytes: Int): FetchDataInfo = { val leader = leaderFor(topicPartition) val response = leader.fetch(topicPartition, offset, maxBytes) response.data } def append(records: MemoryRecords): LogAppendInfo = { val info = log.append(records) info } def read(offset: Long, maxLength: Int) FetchDataInfo = { val fetchDataInfo = log.read(offset, maxLength) fetchDataInfo }
ISR
在之前的文档读书笔记中提到过ISR这个概念,每个partition的所有副本叫做AR,AR = ISR + OSR,即使只有两三个副本,这些概念也是有的。
ISR(In-Sync Replicas):是指那些与 Leader 副本保持同步的 Follower 副本集合。这些副本能够及时地从 Leader 副本拉取数据,并且它们的日志偏移量与 Leader 副本的日志偏移量保持一致或非常接近。
OSR(Out-of-Sync Replicas):是指那些没有及时与 Leader 副本同步的 Follower 副本。这些副本的日志偏移量落后于 Leader 副本。
scala
代码解读
复制代码
// ReplicaManager.scala 检查follower状态,定期更新ISR和OSR def checkAndMaybeShrinkIsr(): Unit = { allPartitions.foreach { partition => val replica = getReplica(partition.topicPartition).get maybeShrinkIsr(partition.topicPartition, replica) } } def checkAndMaybeExpandIsr(): Unit = { allPartitions.foreach { partition => val replica = getReplica(partition.topicPartition).get maybeExpandIsr(partition.topicPartition, replica) } }
选举leader
刚刚提到副本是为了数据的可靠性可用性,那么当leader挂了的时候,如何保证可靠性可用性呢?下面是围绕leader选举前后相关的流程:
- 故障检测:controller通过心跳检测或 ZooKeeper 监控到 Leader 副本故障。
scala
代码解读
复制代码
// ControllerEventManager.scala def onBrokerFailure(deadBroker: Int): Unit = { info(s"Broker $deadBroker has failed") val partitions = replicaStateMachine.replicasForBroker(deadBroker).map(_.topicPartition) partitions.foreach { partition => electLeaderForPartition(partition) } }
- 选择新的 Leader:controller从 ISR 中选择一个新的 Leader 副本。如果 ISR 为空,controller可能会从 OSR 中选择一个新的 Leader,但这通常会导致数据丢失的风险。
scala
代码解读
复制代码
// PartitionStateMachine.scala def electLeaderForPartition(topicPartition: TopicPartition): Unit = { val replicaStates = replicaStateMachine.replicaStates(topicPartition) val isr = replicaStates.filter(_.isInSync).map(_.brokerId) if (isr.nonEmpty) { val newLeader = isr.head val leaderAndIsr = LeaderAndIsr(newLeader, isr.toList, controller.epoch, 0) replicaStateMachine.handleStateChange(topicPartition, newLeaderAndIsr) } else { // Handle the case where ISR is empty warn(s"No in-sync replicas for partition $topicPartition. Cannot elect a new leader.") } }
- 更新元数据:controller更新 ZooKeeper 中的分区元数据,将新的 Leader 副本信息写入 ZooKeeper。
scala
代码解读
复制代码
// ZkLeaderElection.scala def electLeader(topicPartition: TopicPartition, leaderAndIsr: LeaderAndIsr): Unit = { val path = s"${BrokerIdsPath}/${topicPartition.topic}/${topicPartition.partition}" val data = leaderAndIsr.toJson zkUtils.updatePersistentPath(path, data) }
- 通知 Broker:controller通知所有 Broker 分区的 Leader 信息已更新。Broker 更新本地缓存的分区元数据。
scala
代码解读
复制代码
// ControllerChannelManager.scala def sendUpdateMetadataRequest(): Unit = { val partitions = replicaStateMachine.allPartitions val metadata = partitions.map { partition => val replicaStates = replicaStateMachine.replicaStates(partition) val leader = replicaStates.find(_.isLeader).map(_.brokerId).getOrElse(-1) val isr = replicaStates.filter(_.isInSync).map(_.brokerId).toList (partition, LeaderAndIsr(leader, isr, controller.epoch, 0)) }.toMap brokers.foreach { broker => sendRequest(broker, new UpdateMetadataRequest(controller.epoch, metadata)) } }
- 新的 Leader 接管:新的 Leader 副本接管分区的读写请求。Follower 副本继续从新的 Leader 副本拉取数据。
scala
代码解读
复制代码
// ReplicaManager.scala def makeLeader(topicPartition: TopicPartition, leaderAndIsr: LeaderAndIsr, isNew: Boolean): Unit = { val replica = getOrCreateReplica(topicPartition) replica.becomeLeader(leaderAndIsr.leaderEpoch, isNew) replica.updateIsr(leaderAndIsr.isr) info(s"Partition $topicPartition became leader with epoch ${leaderAndIsr.leaderEpoch} and ISR ${leaderAndIsr.isr}") }
Log
上面所说的partition中的每个replication可都是物理概念,用partition来表示主副本leader的话,每个partition都对应有一个log文件。
Producer生产的数据会被不断追加到log文件末端,为防止log文件过大导致数据定位效率低下,Kafka采取了分片和索引机制,将每个partition分为多个segment,每个segment包括:.log文件、.index文件、.timeindex文件。
text
代码解读
复制代码
-rw-rw-r-- 1 service service 432184 Dec 21 13:33 00000000000103897757.index -rw-rw-r-- 1 service service 1073647794 Dec 21 13:33 00000000000103897757.log -rw-rw-r-- 1 service service 632844 Dec 21 13:33 00000000000103897757.timeindex -rw-rw-r-- 1 service service 450416 Dec 21 14:26 00000000000104000818.index -rw-rw-r-- 1 service service 1073736944 Dec 21 14:26 00000000000104000818.log -rw-rw-r-- 1 service service 660504 Dec 21 14:26 00000000000104000818.timeindex -rw-rw-r-- 1 service service 478696 Dec 21 15:32 00000000000104113247.index -rw-rw-r-- 1 service service 1073733468 Dec 21 15:32 00000000000104113247.log -rw-rw-r-- 1 service service 705888 Dec 21 15:32 00000000000104113247.timeindex
log结构
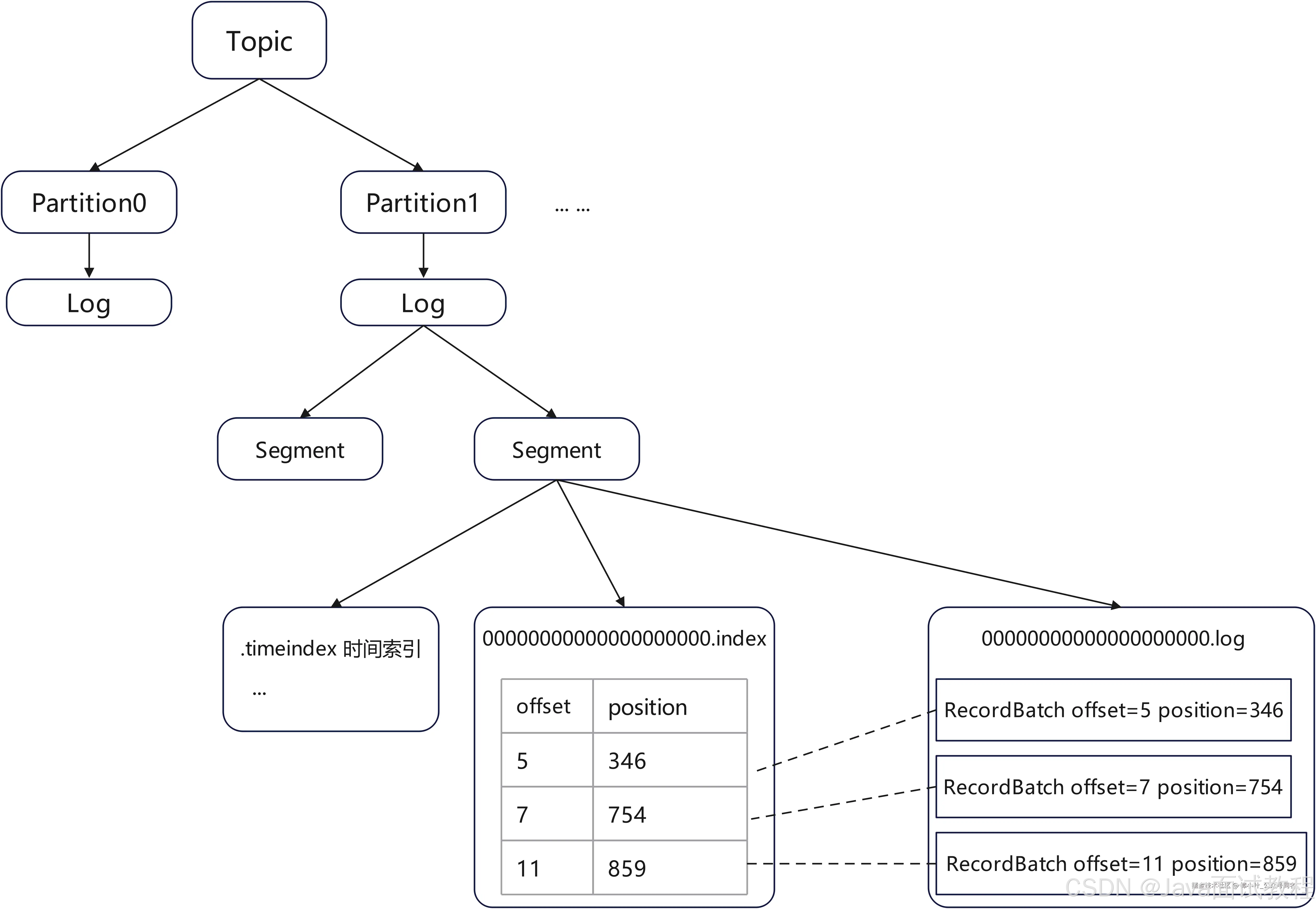
log操作
追加消息:append(records: MemoryRecords): 将消息追加到日志中。
scala
代码解读
复制代码
// Log.scala def append(records: MemoryRecords): LogAppendInfo = { val info = log.append(records) info }
读取消息:read(startOffset: Long, maxLength: Int): 从指定偏移量读取消息(上图中有描述),最多读取 maxLength 字节。
scala
代码解读
复制代码
// Log.scala def read(startOffset: Long, maxLength: Int): FetchDataInfo = { val fetchDataInfo = log.read(startOffset, maxLength) fetchDataInfo }
滚动日志段:roll(): 创建一个新的日志段。
scala
代码解读
复制代码
// Log.scala def roll(): Unit = { val newSegment = new LogSegment( dir = dir, baseOffset = nextOffsetMetadata.messageOffset, indexIntervalBytes = config.indexIntervalBytes, maxIndexSize = config.maxIndexSize, // ... ) addSegment(newSegment) }
清理日志:cleanup(): 根据配置清理旧的日志段。
scala
代码解读
复制代码
// Log.scala def cleanup(): Unit = { val logSegments = logSegments.sorted val segmentsToDelete = logSegments.takeWhile { segment => segment.log.file.lastModified < time.milliseconds - config.retentionMs || segment.log.size > config.retentionBytes } segmentsToDelete.foreach { segment => segment.delete() removeSegment(segment) } }
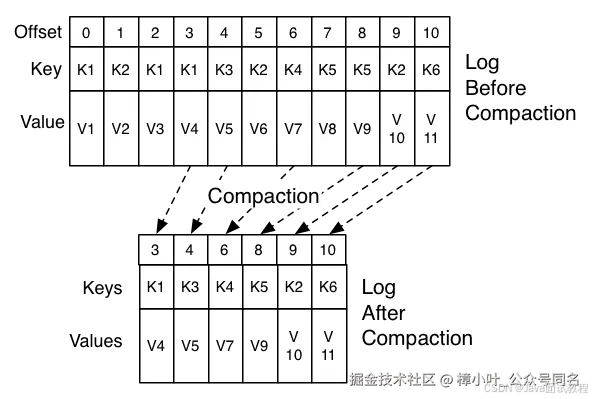
log压缩
除了日志删除直接释放出磁盘空间外,还提供日志压缩这种优化磁盘使用的策略,即只保留每个键的最新值。
scala
代码解读
复制代码
// Log.scala def maybeCompact(): Unit = { if (config.cleanupPolicy.contains("compact")) { // 如果配置开启了日志压缩 // 选择要压缩的segments val segmentsToCompact = logSegments.filter(_.isLogStartOffsetCheckpointed) segmentsToCompact.foreach { segment => segment.compact() // 压缩 } } }
下图来自官网
零拷贝
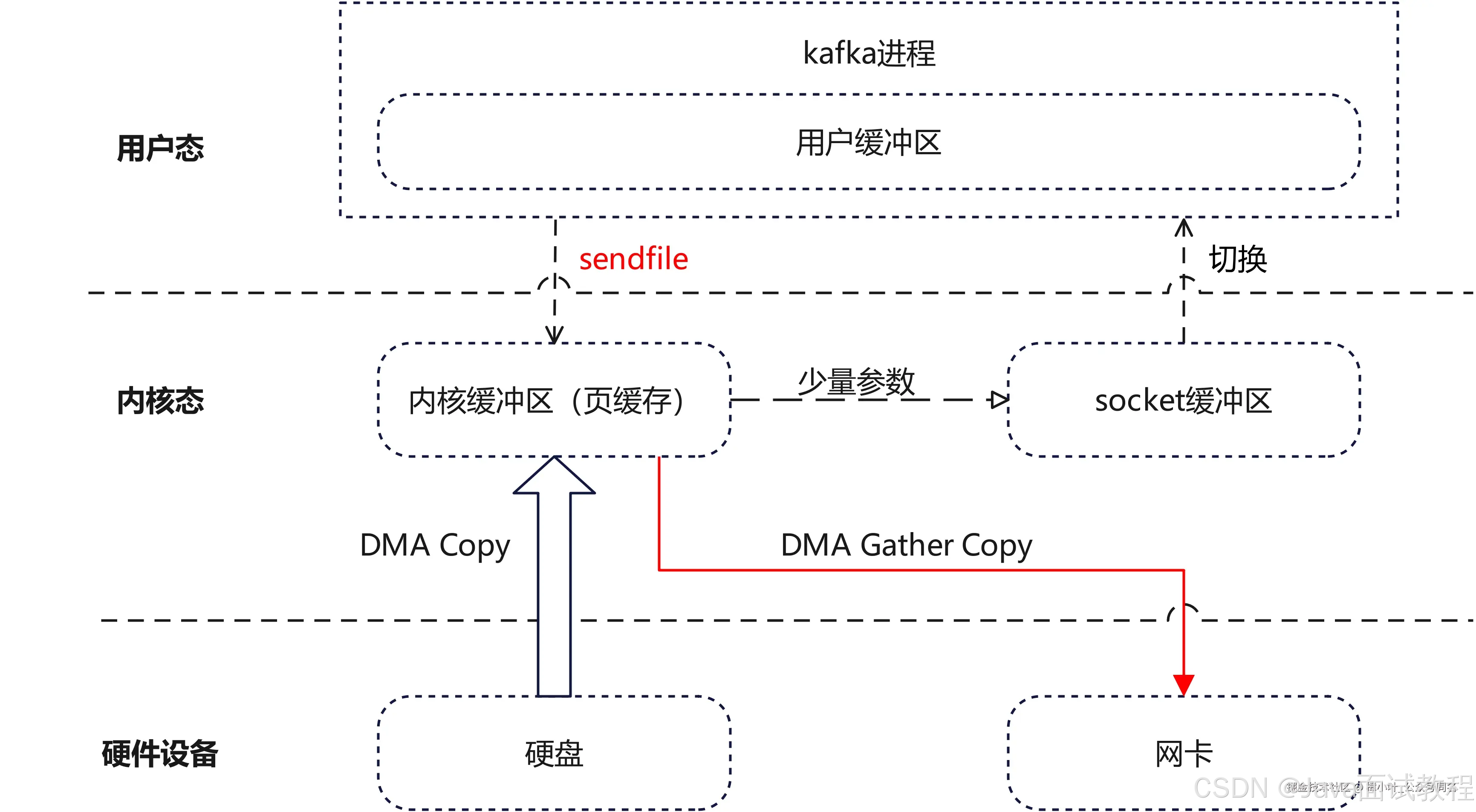
前面的内容有涉及到kafka写磁盘快的秘密,就是顺序写磁盘;有涉及到读的效率提升,就是用log索引机制;还有就是使用分区来并行读写,也能提升读写效率。
kafka还借助了一项linux中的技术,零拷贝sendfile,来提升数据传输效率。具体来说,就是kafka进程本身只需要考虑处理数据,而不需要考虑存储数据,数据传输过程只需要经过0次CPU拷贝、2次DMA拷贝和两次上下文切换,就ok了。比起不用sendfile来传输数据要快一些。

















 1464
1464

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









