






1.3 分类
1.1. 被动信息收集
通过公开渠道可获得的信息,与目标系统不会产生直接交互。被动信息收集不会在日志中留下痕迹。比如:在网络上进行搜索,百度搜索,Google搜索。
1.2. 主动信息收集
直接访问,扫描网站,这种将流量流经网站的行为:与目标系统产生交互的行为,与目标系统直接交互,系统日志留下痕迹,像利用工具扫描。
2.资产信息收集
以下的信息收集以 大学 为目标展开
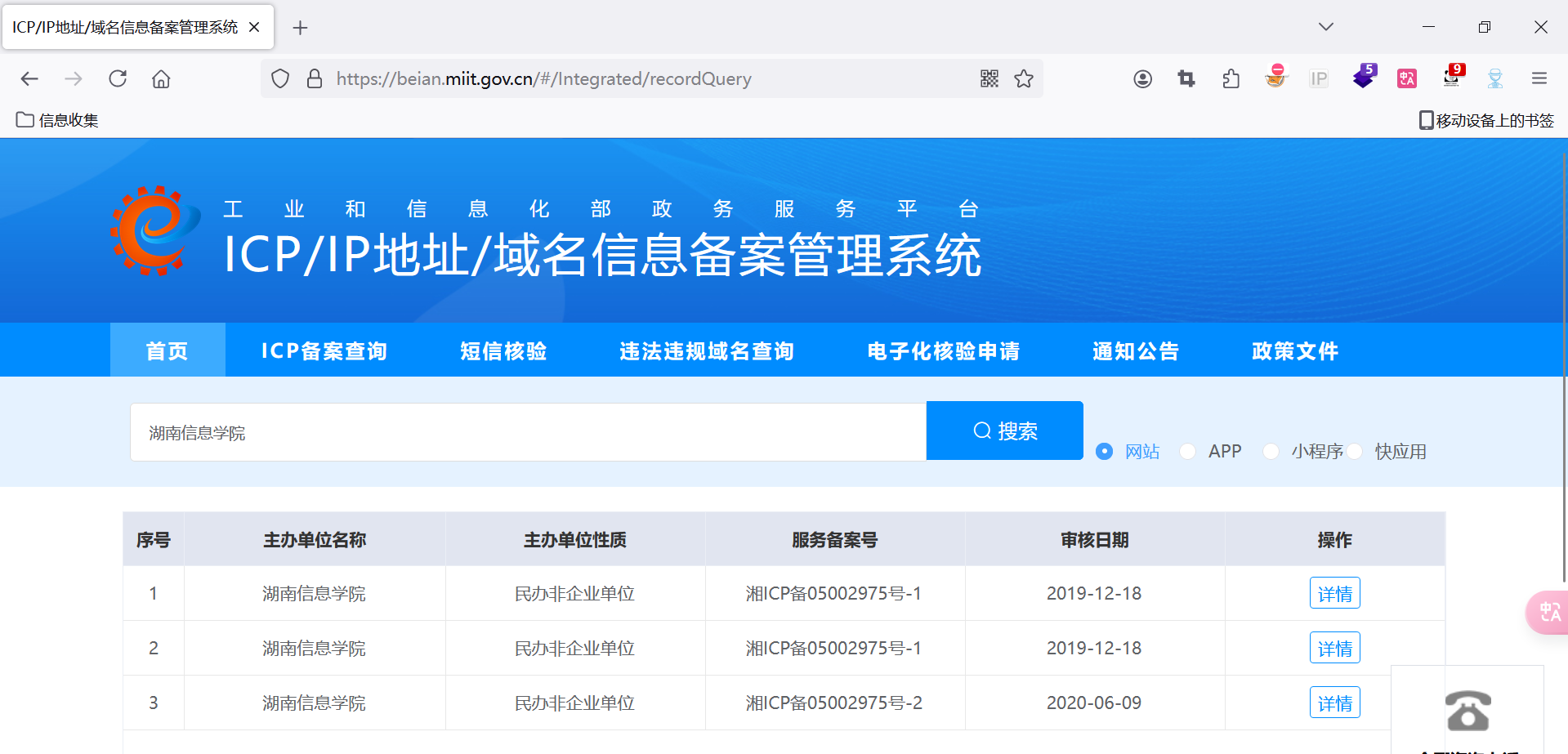
2.1 主域名资产收集
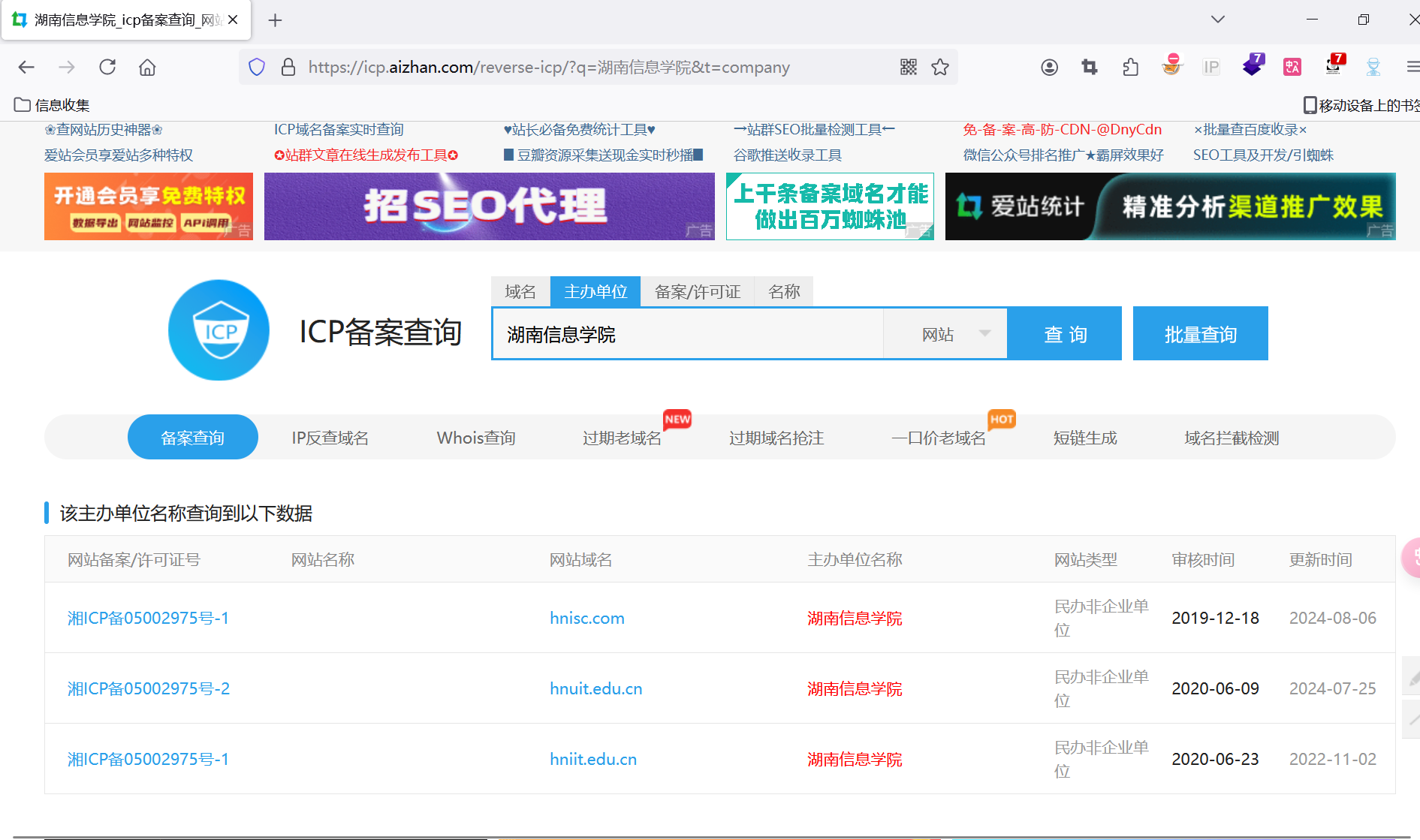
1.1. 利用名称和域名查询
运用以下网站都可以查询主域名和IP地址和子域名

- https://beian.miit.gov.cn/#/Integrated/index 工信部备案
- http://icp.chinaz.com/ 站长之家
- https://www.aizhan.com/cha/ 爱站网
1.2. 使用DNS记录查询

正向解析=====》域名找IP
反向解析=====》IP找域名
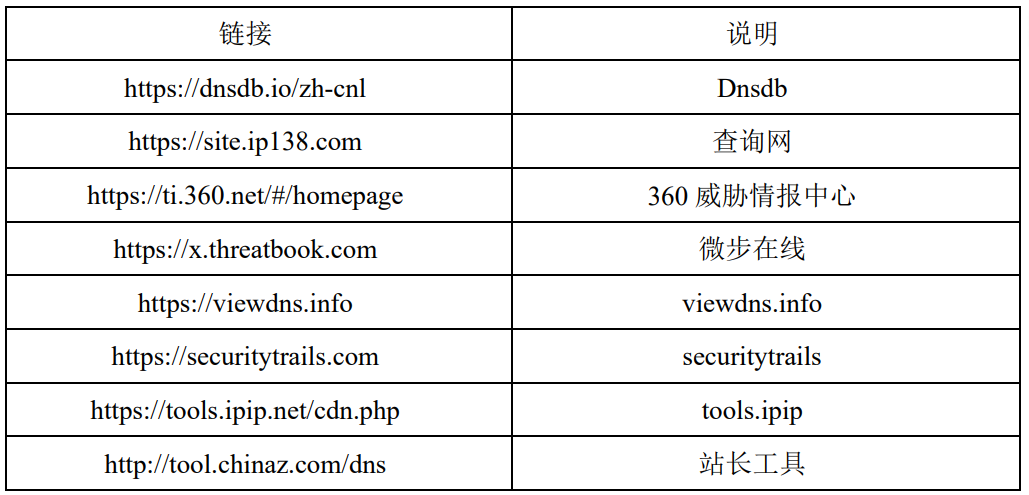
1.3 whois查询
whois是一个用来查询域名是否已经被注册,以及注册域名的详细信息的数据库(包括域名拥有人,域名注册商)。不同域名后缀的whois信息需要到不同的whois数据库查询。
查询接口:四个
在Kali Linux中可以使用命令查询Whois。
2.2 子域名资产收集
1.用搜索引擎
浏览器的搜索语法,搜索子域名。
- 双引号(" "):用于精确匹配短语。例如,搜索
"人工智能技术"将只返回包含该完整短语的结果。 - 星号(*):用于通配符搜索,替代未知单词或短语。例如,搜索
人工智能 * 应用可以匹配“人工智能技术应用”或“人工智能在医疗应用”。 - 减号(-):用于排除特定词语。例如,搜索
人工智能 -医疗将返回与人工智能相关但不包含“医疗”的结果。 - site::用于限定在特定网站内搜索。例如,搜索
人工智能 site:example.com将只在 example.com 网站内搜索相关内容。 - filetype::用于搜索特定文件类型。例如,搜索
人工智能 filetype:pdf将返回与人工智能相关的 PDF 文件。 - intitle::用于搜索标题中包含特定关键词的页面。例如,搜索
intitle:人工智能将返回标题中包含“人工智能”的页面。 - inurl::用于搜索 URL 中包含特定关键词的页面。例如,搜索
inurl:ai将返回 URL 中包含“ai”的页面。 - related::用于查找与特定网站相关的网站。例如,搜索
related:example.com将返回与 example.com 相关的网站。 - OR:用于搜索包含任一关键词的结果。例如,搜索
人工智能 OR 机器学习将返回包含“人工智能”或“机器学习”的结果。 - AND:用于搜索同时包含多个关键词的结果。例如,搜索
人工智能 AND 医疗将返回同时包含“人工智能”和“医疗”的结果。 - 括号(()):用于组合搜索条件。例如,搜索
(人工智能 OR 机器学习) AND 医疗将返回包含“人工智能”或“机器学习”且同时包含“医疗”的结果。 - ..:用于搜索数值范围。例如,搜索
人工智能 2010..2020将返回 2010 年至 2020 年间与人工智能相关的结果。
常用site,intitle
site:域名 + 内容,可以更准确地搜集到相关信息
intile
- 查找标题中包含单个关键词的页面:
-
- 搜索
intitle:人工智能,将返回所有标题中包含“人工智能”的网页。
- 搜索
- 查找标题中包含多个关键词的页面:
-
- 搜索
intitle:人工智能 intitle:技术,将返回标题中同时包含“人工智能”和“技术”的网页。
- 搜索
- 结合
site:使用:
-
- 搜索
intitle:新闻 site:example.com,将返回example.com网站上标题中包含“新闻”的网页。
- 搜索
- 结合
filetype:使用:
-
- 搜索
intitle:报告 filetype:pdf,将返回标题中包含“报告”的 PDF 文件。
- 搜索
- 查找特定短语:
-
- 搜索
intitle:"人工智能技术",将返回标题中包含完整短语“人工智能技术”的网页。
- 搜索
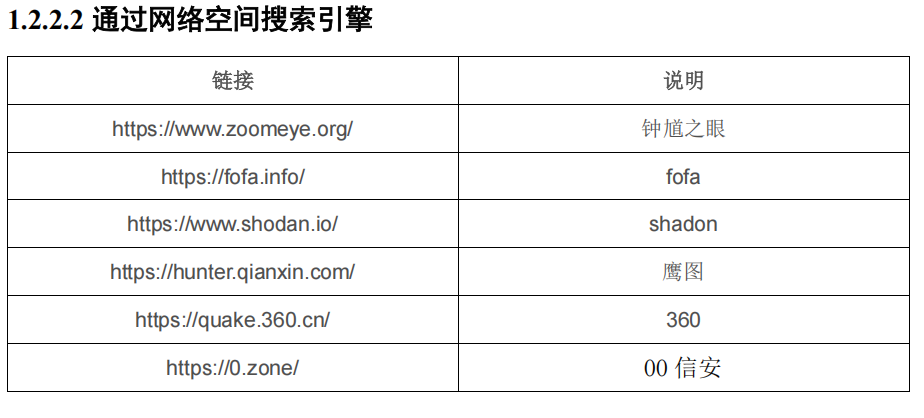
2 . 子域名爆破
1.layer挖掘机

输入域名即可扫描,但是一般不使用,容易被拉黑。
2.oneforall
也是用来扫描子域名的,使用命令需要在命令行中运行,并且需要python环境
启动命令:

当运行时状态:当运行到百分百时在 oneforall 文件
中"OneFor\OneFor\results" ,results文件夹中根据时间可看到

以表格的形式呈现相关域名
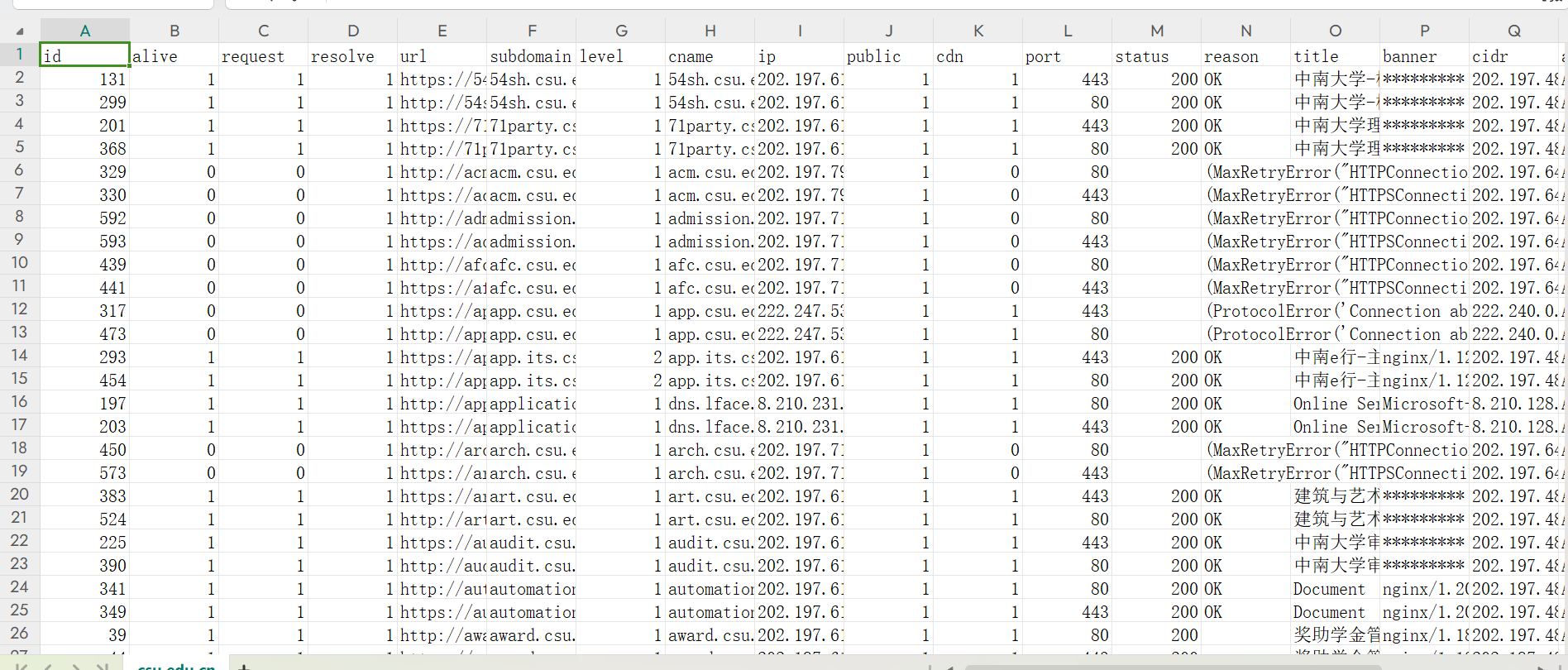
3 .扫描隐藏目录
目录为访问路径
dirsearch是一个基于python3的命令行目录扫描工具,类似于御剑之类的工具,是一个基于Python的开源目录扫描工具,专门用于通过枚举Web服务器上的目录和文件来查找潜在的安全漏洞。它支持多种协议(如HTTP、HTTPS),并且能够处理响应状态码、重定向、时间延迟等多个场景,这使得它在处理复杂环境时也能表现出色。

4.IP和c段资产收集
1.绕过CDN寻找真实IP
CDN的定义和原理:cdn全名 :内容分发网络
CDN技术一般是大公司所使用的缓解当地服务器的技术,将内容分发到各地的节点(像图中的小型服务器),用户在使用的时候会自动选择最近的节点,这样就可以隐藏服务器的真实IP。
CDN 技术还可以根据服务器负载情况进行流量调度,保证服务器的稳定性和可 用性。使用 CDN 技术隐藏真实 IP 可以进一步提高服务器的安全性。但是,使用 CDN 技术隐藏 IP 可能导致服务器发布的内容无法及时更新,并且受到地区限制的影响
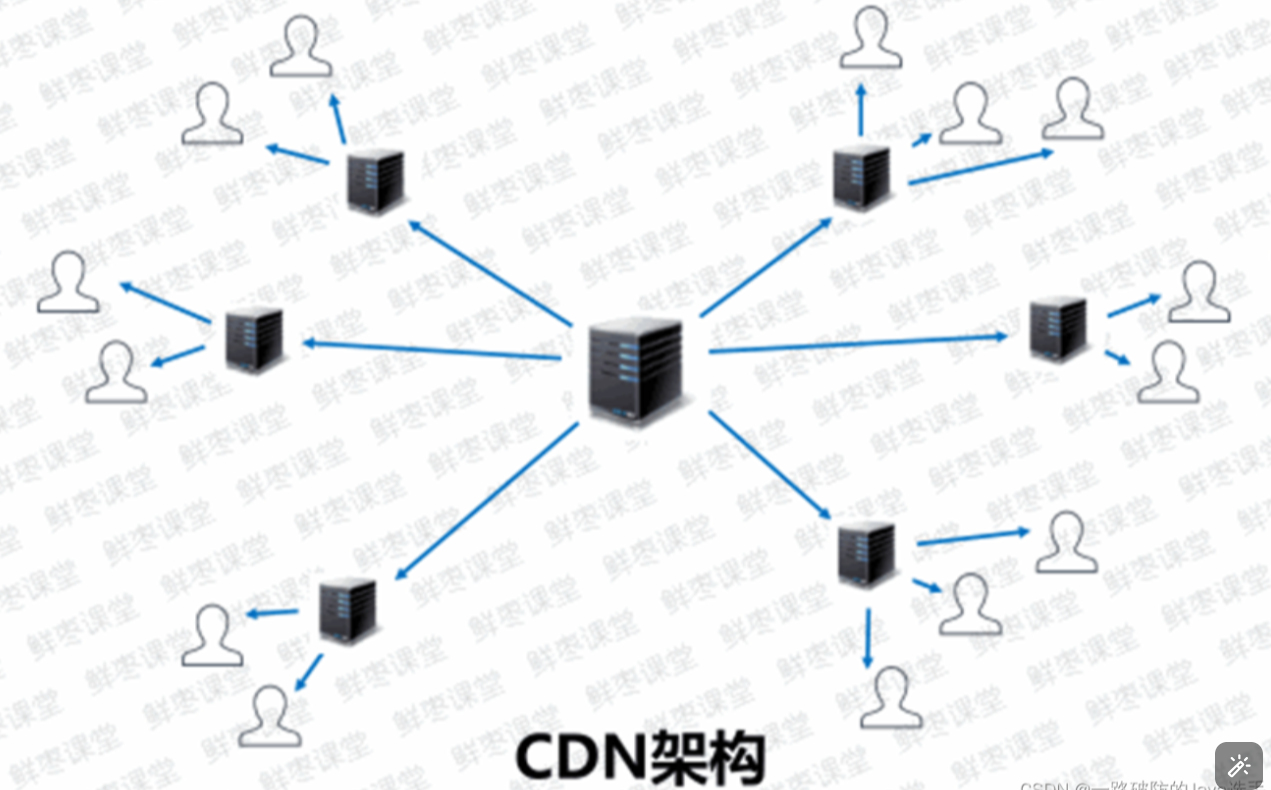
1.1 判断是否存在 CDN 方法
负载均衡
1:很简单,使用各种多地 ping 的服务,查看对应 IP 地址是否唯一,如果不唯 一多半是使用了 CDN,多地 Ping 网站有:
http://ping.chinaz.com/
http://ping.aizhan.com/
首先,要判断该域名是否存在 CDN 的情况,我们可以去在线 CDN 查询网站:http://ping.chinaz.com/ 。
如果查询出的 ip 数量大于一个的话,则说明该 ip 地址不是真实的服务器地址。
如果是 2 个或者 3 个,并且这几个地址是同一地区的不同运营商的话,则很有可能这几个地址是服务器的出口地址,该服务器在内网中,通过不同运营商 NAT 映射供互联网访问,同时采用几个不同的运营商可以负载均衡和热备份。如果 是多个 ip 地址,并且这些 ip 地址分布在不同地区的话,则基本上可以断定就是采用了 CDN 了。
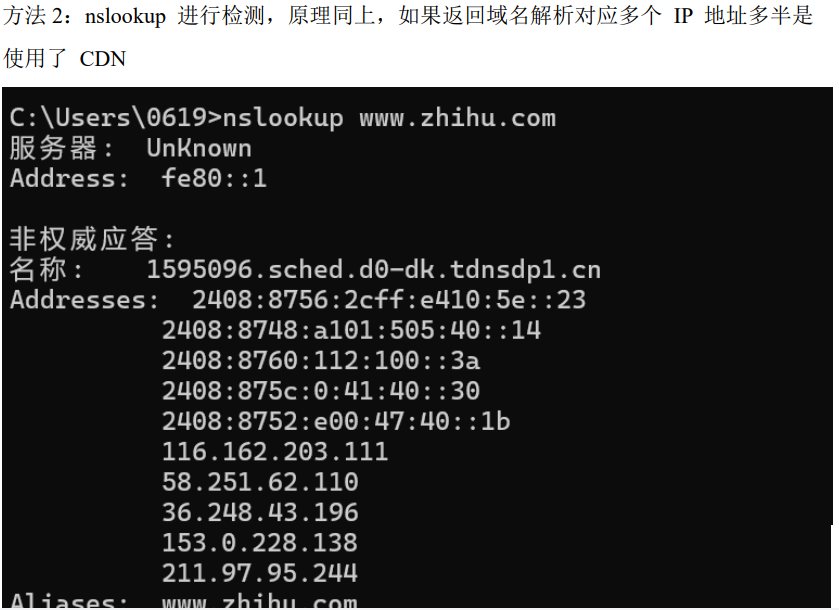
1.2 绕过CDN的方法
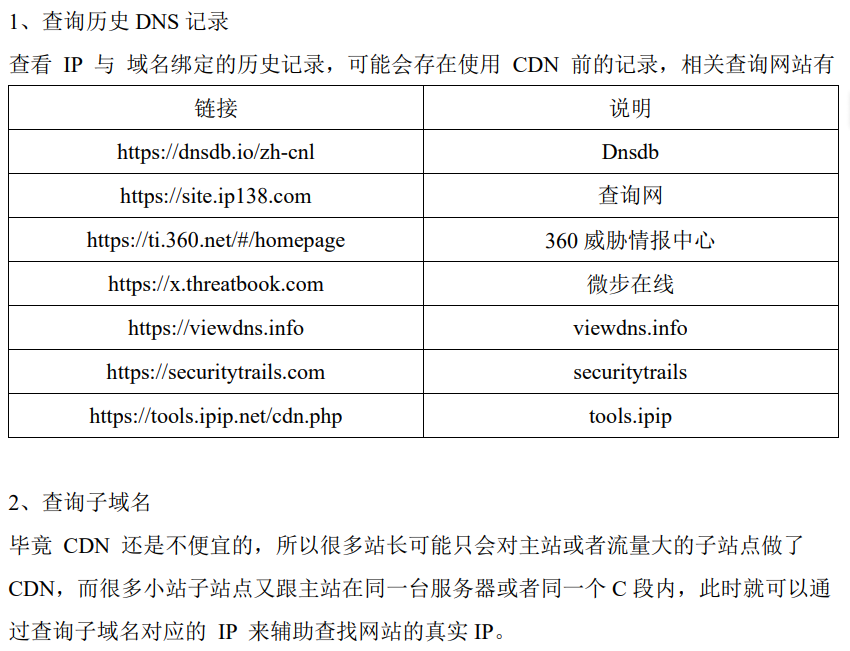
2.资产收集工具
下图是·nmap的应用程序
但是不清楚如何使用

3.HTTP证书
证书的序列号也可以进行查询,但是序列号是16进制,需要转换为二进制
将csdn的证书做列子
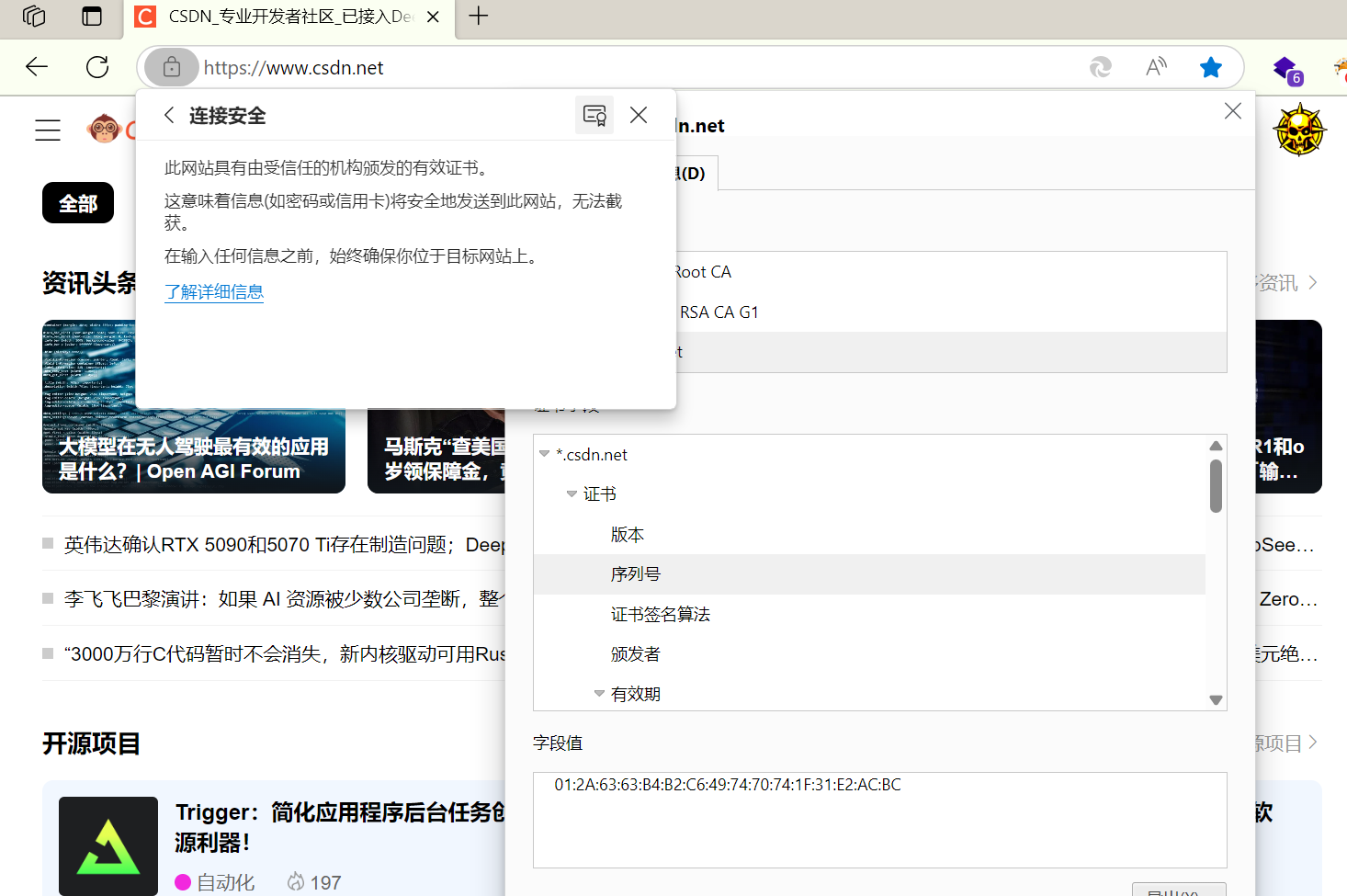
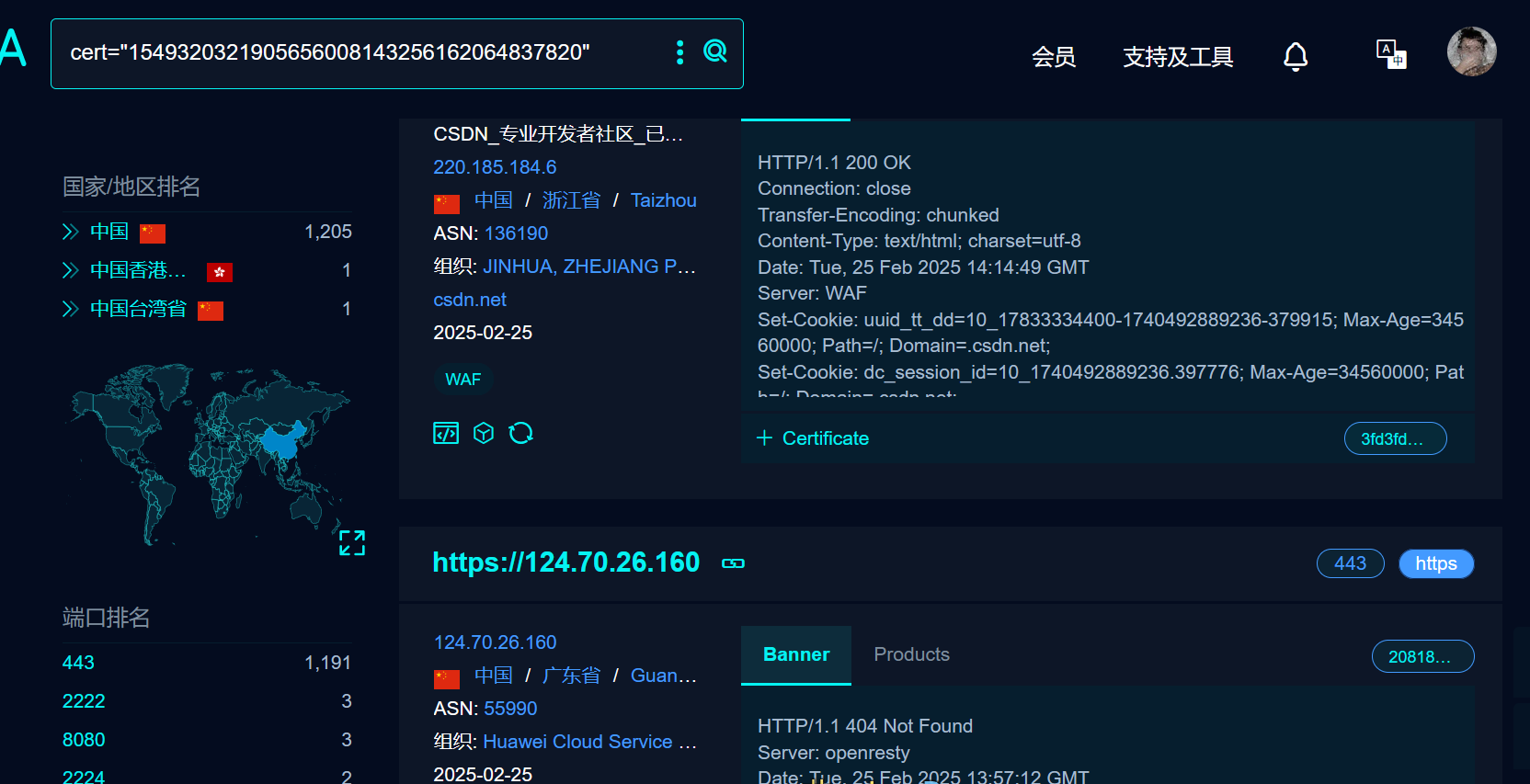
在转换时需要将序列号中的:去除才可以进行转换
在转换后在fofa中利用语法既可以进行信息收集搜索
4.旁站和从段
1.旁站的概念
旁站是指同一个服务器上的其他网站,很多时候,有些网站可能不是那么容易入侵。 那么,可以查看该网站所在的服务器上是否还有其他网站。如果有其他网站的话,可 以先拿下其他网站的 webshell,然后再提权拿到服务器的权限,最后就自然可以拿下 该网站了!
2.C 段
C 段指的是同一内网段内的其他服务器,每个 IP 有 ABCD 四个段,举个例子, 192.168.0.1,A 段就是 192,B 段是 168,C 段是 0,D 段是 1,而 C 段嗅探的意思就 是拿下它同一 C 段中的其中一台服务器,也就是说是 D 段 1-255 中的一台服务器,然 后利用工具嗅探拿下该服务器。
2.3 公众号和app资产收集
- 当没有思路时,可以采用天眼查,爱企查,等网站查询该企业的公众号或者app。
2.直接使用微信搜索关键词
3.
小蓝本
https://www.xiaolanben.com/login
3. 敏感信息收集
1.4.1 网站漏洞扫描
网站漏洞扫描,各种扫描器了。如:nessus,极光,xray,AWVS,goby,AppScan,
各种大神团队自己编写的扫描器等等
1.4.2 目录扫描
目录扫描,主要扫描敏感信息、隐藏的目录和 api、代码仓库、备份文件等。工具有:
各种御剑,dirmap,Dirsearch,dirbuster,7kbstorm,gobuster 等等。
1.4.3 JS 信息收集
在 JS 中可能会存在大量的敏感信息,包括但不限于:
1、某些服务的接口,可以测试这些接口是否有未授权等
2、子域名,可能包含有不常见或者子域名收集过程中没收集到的目标
3、密码、secretKey 等敏感数据
链接
说明
https://gitee.com/kn1fes/JSFinder
jsfinder
https://github.com/rtcatc/Packer-Fuzzer
Packer-Fuzzer
https://gitee.com/mucn/SecretFinder
SecretFinder
通过在线网站和各种网盘搜集
直接百度网盘搜索,就可搜到很多在线网盘,然后进入网盘搜索关键词,如单位名、
单位别称等。
链接
说明
https://wooyun.website/
乌云漏洞库
https://www.lingfengyun.com/
凌云搜索
http://www.pansoso.com
盘搜搜
http://www.pansou.com/
盘搜
1.4.5 代码仓库搜集敏感信息
github 语法
说明
in:name xxxx
仓库标题中含有关键字 xxxx
in:descripton xxxx.com
仓库描述搜索含有关键字 xxxx
in:readme xxxx
Readme 文件搜素含有关键字 xxxxsmtp xxx.com password 3306
搜索某些系统的密码
4.Dns 域名解析
1.DNS概述
DNS是 Domain Name System 的缩写,也就是 域名解析系统,是互联网中提供域名与IP地址互相映射的分布式数据库。它的作用非常简单,就是根据域名查出对应的 IP地址。
2.什么是 DNS 域名解析
1.我们首先要了解域名和 IP 地址的区别。
IP 地址是互联网上计算机唯一的逻辑地址
通过 IP 地址实现不同计算机之间的相互通信,每台联网计算机都需要通过 IP 地址来互相联系和分别。但由于 IP 地址是由一串容易混淆的数字串构成,人们很难记忆所有计算机的 IP 地址,这样对于我们日常工作生活访问不同网站是很困难的。基于这种背景,人们在 IP地址的基础上又发展出了一种更易识别的符号化标识,这种标识由人们自行选择的字母和数字构成,相比 IP 地址更易被识别和记忆,逐渐代替 IP 地址成为互联网用户进行访问互联的主要入口。
这种符号化标识就是域名。域名虽然更易被用户所接受和使用,但计算机只能识别纯数字构成的 IP 地址,不能直接读取域名。因此要想达到访问效果,就需要将域名翻译成 IP 地址。而 DNS 域
名解析承担的就是这种翻译效果
http://tool.chinaz.com/dns/
https://tool.lu/dns/
https://dnsdumpster.com/
https://www.virustotal.com/gui/home/search
https://rapiddns.io


















 894
894

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











