







目标检测框架YOLOv5训练手语手势数据集
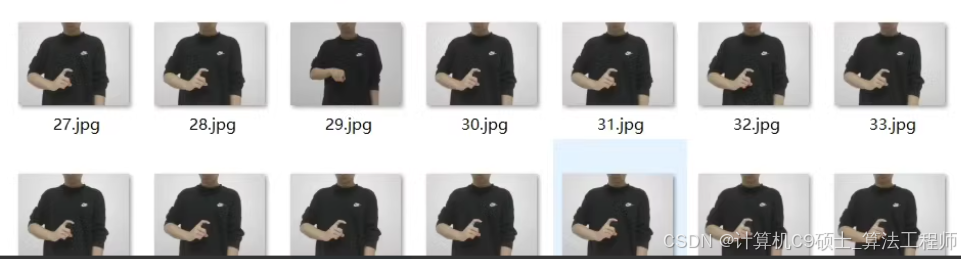
手语手势数据集 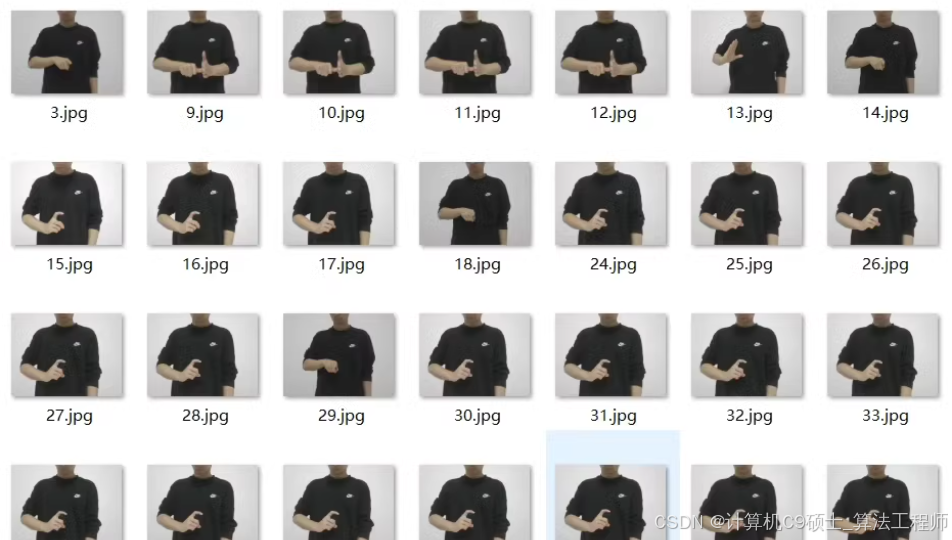
格式:yolo数据集格式
类别:你 时间 朋友 生日 名片 妻子 今天 门 我等共35个类别
标注软件:labelimg
总共有2300+张标记图像,主要应用背景:手语手势识别

时间/时候
你/您/你的/这
早上
9
0
快乐/高兴
新
祝
请
路
生日
平
安
朋友
8
认识
名片
结婚/妻子
茶
有
花
今天
门
停
谢谢
慢
走
晚
我
好
人
以YOLOv5为例,因为它是一个广泛应用的目标检测框架,并且支持Yolo格式的数据集。以下是详细的步骤和代码示例:
数据准备
- 组织数据:
- 确保你的图像文件位于
images/目录下(可以进一步划分为train/、val/等子目录),对应的标签文件(YOLO格式)位于labels/目录下。 - 创建一个
data.yaml文件来描述你的数据集路径和类别信息。例如:
- 确保你的图像文件位于
train: ./path/to/train/images
val: ./path/to/val/images
nc: 35
names: ['时间/时候', '你/您/你的/这', '早上', ..., '好', '人'] # 请根据实际类别列表填充
确保类别名称与标注时使用的完全一致。
安装依赖并获取YOLOv5
- 如果你还没有安装YOLOv5,请先克隆仓库并安装所需的Python包:
git clone https://github.com/ultralytics/yolov5 # 克隆YOLOv5仓库
cd yolov5
pip install -r requirements.txt # 安装依赖
开始训练
- 使用以下命令开始训练过程。你可以根据自己的需求调整参数,比如批次大小(
--batch-size)、学习率(--lr)、epoch数(--epochs)等。
python train.py --img 640 --batch 16 --epochs 100 --data path/to/your/data.yaml --weights yolov5s.pt
--img 640设置输入图像尺寸为640x640像素。--batch 16设置批次大小为16。--epochs 100设置训练轮次为100。--data path/to/your/data.yaml指定数据配置文件路径。--weights yolov5s.pt加载预训练权重作为起点。如果想从头开始训练,可以去掉此选项或选择其他合适的预训练权重。
评估模型
- 训练完成后,可以使用以下命令评估模型性能:
python val.py --weights runs/train/exp/weights/best.pt --data path/to/your/data.yaml --img 640 --task val
这将输出验证集上的mAP(mean Average Precision)等指标。
可视化预测结果
- 使用YOLO提供的
detect.py脚本可以对新图像进行预测,并保存带有边界框的结果图像:
python detect.py --source path/to/test/images --weights runs/train/exp/weights/best.pt --conf 0.25 --save-txt --save-conf
--source path/to/test/images指定待预测图像或视频的路径。--weights runs/train/exp/weights/best.pt指定最佳权重文件路径。--conf 0.25设置置信度阈值。--save-txt保存预测结果为txt文件。--save-conf在txt文件中保存置信度分数。
为了提供更详细的指导,我们将进一步细化每个步骤,并补充一些关键点和代码示例。我们将使用YOLOv5作为示例框架来训练你的手语手势数据集。
1. 环境配置
首先确保你有一个合适的Python环境,并安装了必要的依赖项:
# 克隆YOLOv5仓库
git clone https://github.com/ultralytics/yolov5
cd yolov5
# 安装依赖
pip install -r requirements.txt
2. 数据准备
假设你的数据已经标注并转换为YOLO格式(通过LabelImg或其他工具),接下来需要组织这些数据以便于训练。
- 将图像文件放置在
/path/to/images/train和/path/to/images/val中。 - 标签文件应放在对应的
/path/to/labels/train和/path/to/labels/val目录下。 - 创建一个
data.yaml文件,内容如下:
train: /path/to/images/train
val: /path/to/images/val
nc: 35 # 类别数量
names: ['时间/时候', '你/您/你的/这', '早上', ..., '好', '人'] # 所有类别名称
3. 训练模型
接下来是编写训练脚本。你可以直接调用YOLOv5的train.py脚本来开始训练过程,同时根据需要调整参数。
import torch
# 指定超参数
imgsz = 640 # 图像尺寸
batch_size = 16 # 批次大小
epochs = 100 # 训练轮数
weights = 'yolov5s.pt' # 预训练权重路径
data = '/path/to/data.yaml' # 数据配置文件路径
# 开始训练
model = torch.hub.load('ultralytics/yolov5', 'custom', path_or_model=weights)
model.train(data=data, epochs=epochs, imgsz=imgsz, batch_size=batch_size)
print("训练完成")
4. 模型评估
训练完成后,可以使用以下代码进行评估:
from pathlib import Path
# 加载最佳权重
best_weights = str(Path('runs/train/exp/weights/best.pt')) # 根据实际情况修改路径
# 使用验证集评估模型
model = torch.hub.load('ultralytics/yolov5', 'custom', path_or_model=best_weights)
results = model.val(data=data)
# 输出mAP等指标
print(results)
5. 可视化预测结果
对于新图像的预测与可视化,可以使用以下代码片段:
from PIL import Image
import cv2
# 加载模型
model = torch.hub.load('ultralytics/yolov5', 'custom', path_or_model=best_weights)
# 对单张图片进行预测
def plot_one_box(x, img, color=None, label=None, line_thickness=None):
tl = line_thickness or round(0.002 * (img.shape[0] + img.shape[1]) / 2) + 1 # line/font thickness
color = color or [random.randint(0, 255) for _ in range(3)]
c1, c2 = (int(x[0]), int(x[1])), (int(x[2]), int(x[3]))
cv2.rectangle(img, c1, c2, color, thickness=tl, lineType=cv2.LINE_AA)
if label:
tf = max(tl - 1, 1) # font thickness
t_size = cv2.getTextSize(label, 0, fontScale=tl / 3, thickness=tf)[0]
c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3
cv2.rectangle(img, c1, c2, color, -1, cv2.LINE_AA) # filled
cv2.putText(img, label, (c1[0], c1[1] - 2), 0, tl / 3, [225, 255, 255], thickness=tf, lineType=cv2.LINE_AA)
image_path = '/path/to/test/image.jpg'
img = Image.open(image_path)
results = model(img)
for i, (im, pred) in enumerate(zip(results.imgs, results.pred)):
im = cv2.cvtColor(im, cv2.COLOR_RGB2BGR)
if pred is not None:
for *box, conf, cls in pred:
label = f'{results.names[int(cls)]} {conf:.2f}'
plot_one_box(box, im, label=label, color=[0, 255, 0])
cv2.imshow('Prediction', im)
cv2.waitKey(0)
cv2.destroyAllWindows()


















 992
992

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









