






牛了!北大提出全新模型FAN,一举填补Transformer周期性建模的缺陷!通过引入傅里叶级数思想,使周期性信息能直接嵌入网络结构中,无缝替换MLP,并减少参数量和计算量!
实际上,对Transformer进行改进一直是热门!除前文所提,近来也有多篇高质量成果产出。比如MIT把Transformer计算,直接优化到乘法运算,能耗直降95%;清华则用物理学革新Transformer的注意力机制,精度暴涨30%……
主要在于,当前Transformer可谓是AI领域最核心的模型,发布7年,引用量就破了10万+。但其也一直存在对输入顺序敏感性弱、训练成本高、处理长序列性能下降等困扰,因而对其的改进成为了迫切需求!
为让大家能够全面掌握领域发展,找到自己的idea,我给大家准备了14种改进思路和源码。
论文原文+开源代码需要的同学看文末
论文:ADDITION IS ALL YOU NEED FOR ENERGY-EFFICIENT LANGUAGE MODEL
内容
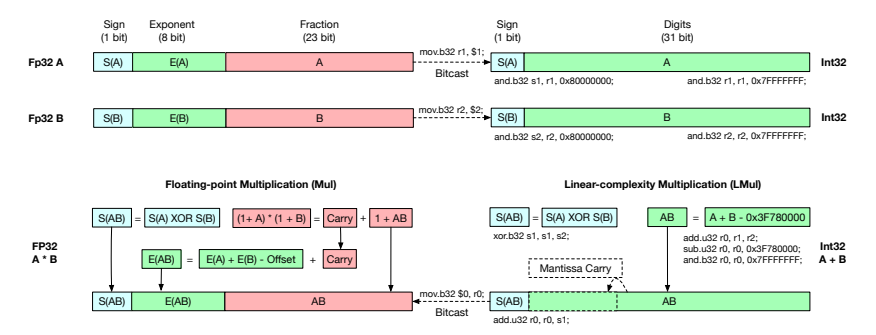
该论文介绍了一种名为L-Mul的新算法,它通过整数加法来近似浮点数乘法,具有线性复杂度,且在保持高精度的同时显著减少了计算资源和能源消耗,L-Mul在多种自然语言、视觉和数学任务上的表现优于8位浮点数乘法,且在不需要额外训练的情况下,可以直接应用于计算密集型的注意力机制,实现节能高效的模型部署。
论文:DIFFERENTIAL TRANSFORMER
内容
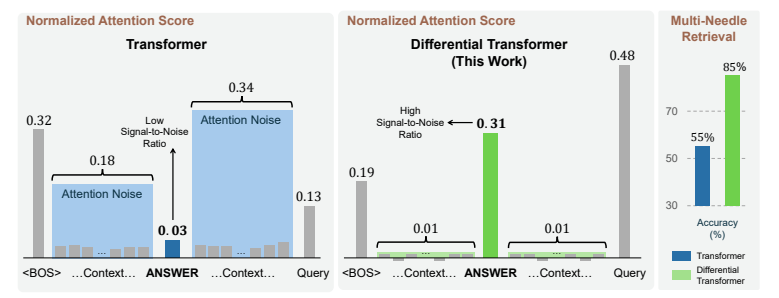
该论文介绍了一种名为DIFF Transformer的新型大型语言模型架构,它通过差分注意力机制来增强对相关上下文的关注并减少噪声,在实际应用中,如长上下文建模、关键信息检索、幻觉减少、上下文学习以及激活异常值减少等方面展现出显著优势。通过减少对不相关上下文的关注,DIFF Transformer能够减轻问题回答和文本摘要中的幻觉现象,并在上下文学习中提高了准确性和鲁棒性。
论文:Improving Transformers with Dynamically Composable Multi-Head Attention
内容
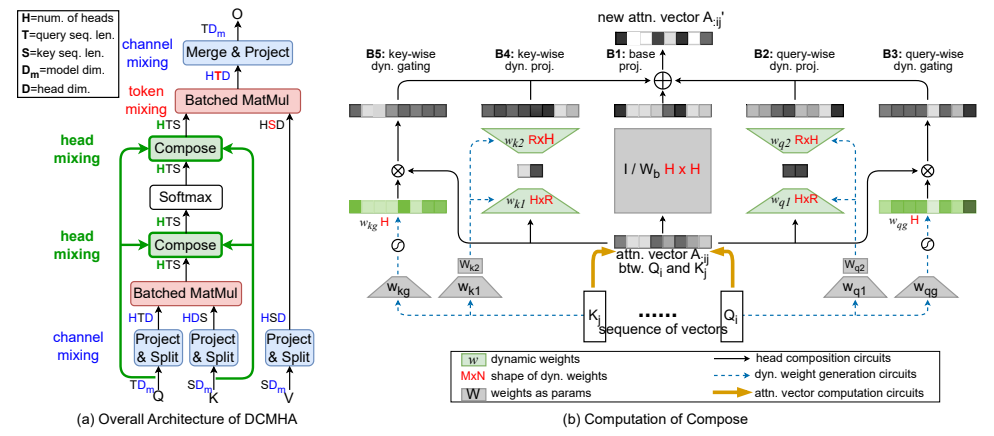
该论文提出了一种名为动态可组合多头注意力的新型注意力机制,它通过动态组合注意力头来提高Transformer模型的表达能力。DCMHA通过一个核心的Compose函数,以输入依赖的方式转换注意力得分和权重矩阵,DCMHA在语言建模任务上显著优于传统的Transformer模型,且在不同架构和模型规模上均表现出色,例如DCPythia-6.9B在预训练困惑度和下游任务评估上优于开源的Pythia-12B模型。
论文:Mixture-of-Depths: Dynamically allocating compute in transformer-based language models
内容
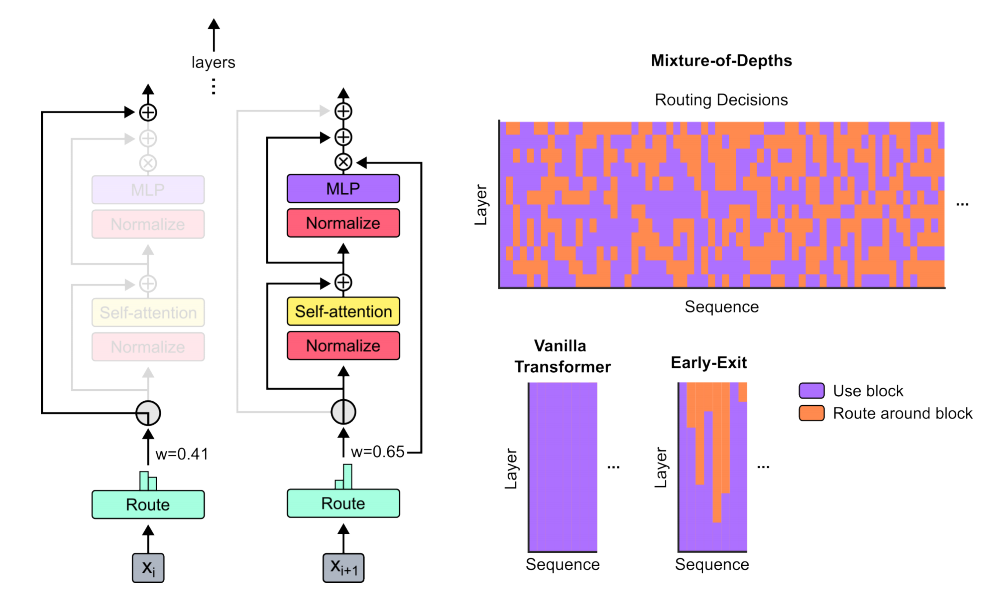
该论文介绍了一种名为Mixture-of-Depths(MoD)的方法,它允许基于Transformer的语言模型动态地在序列的特定位置分配计算资源(FLOPs),通过限制每层可以参与自注意力和多层感知器(MLP)计算的令牌(tokens)数量来实现。这种方法使得模型能够根据每个令牌的需要来优化计算资源的分配,从而在保持性能的同时减少每次前向传播所需的FLOPs,加快后训练采样步骤的速度。
关注下方《AI科研圈圈》
回复“TR魔改”获取全部论文+开源代码
码字不易,欢迎大家点赞评论收藏


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









