






当我们用一个四阶多项式(一个比较复杂的曲线)去拟合数据时,正则化参数(λ)的作用就像是一个“调节器”,它可以帮助我们控制模型的复杂程度,避免模型过于简单或过于复杂。
前提:正则化参数是什么:
正则化参数 λ(有时也记作 α 或其他符号)是正则化项中的一个超参数,它不是模型本身的一个变量,而是在训练模型之前需要设定的一个值。正则化参数控制着正则化项在损失函数中的权重,从而影响模型训练的过程和结果。

1. 正则化参数(λ)的作用
-
λ非常大(比如10000):
-
当λ非常大时,模型会尽量让参数(w)变得很小,甚至接近于零。这是因为正则化项(λ/2 * Σw²)会惩罚参数的大小。
-
结果是,所有的参数(w1, w2, w3, w4)都会变得非常小,模型会变得非常简单,几乎是一个常数函数(f(x) ≈ 常数)。
-
这种情况下,模型在训练数据上的表现很差,因为它无法捕捉数据的任何变化,偏差很高(Jtrain很大)。
-
-
λ非常小(比如0):
-
当λ非常小(甚至为0)时,正则化的作用几乎不存在,模型会尽量去拟合每一个训练数据点。
-
这时模型会变得非常复杂,曲线会完美地通过每一个数据点,看起来像是“过拟合”。
-
虽然在训练集上的误差很小(Jtrain很小),但在验证集上的误差会很大(Jcv比Jtrain大得多),方差很高。
-
-
λ适中:
-
如果选择一个合适的λ值,模型既不会过于简单,也不会过于复杂。
-
这时模型能够很好地拟合数据,同时在训练集和验证集上的表现都很不错(Jtrain和Jcv都很小)。
-
2. 如何选择合适的λ值
为了找到合适的λ值,可以使用交叉验证的方法:
-
步骤1:选择一系列不同的λ值,比如0、0.01、0.1、1、10等。
-
步骤2:对于每一个λ值,用训练集数据训练模型,得到一组参数(w)。
-
步骤3:用这些参数在交叉验证集上计算误差(Jcv)。
-
步骤4:比较不同λ值对应的Jcv,选择使Jcv最小的λ值。这个λ值就是最佳的正则化参数。
-
步骤5:最后,用这个最佳的λ值重新训练整个模型,并在测试集上评估模型的泛化能力(Jtest)。
3.如何调整正则化参数
调整正则化参数 λ 的过程通常涉及以下几个步骤:
-
理解正则化的作用:首先,需要理解正则化的目的,即防止模型过拟合,提高模型的泛化能力。
-
选择正则化类型:根据问题的特点选择合适的正则化类型,如L1正则化(Lasso)、L2正则化(Ridge)或它们的组合(Elastic Net)。
-
使用交叉验证:通过交叉验证来评估不同 λ 值对模型性能的影响。通常,我们会在训练集上训练模型,并在验证集上评估模型的性能。
-
搜索最优 λ:可以通过网格搜索(Grid Search)或随机搜索(Random Search)等方法在一定范围内搜索最优的 λ 值。这些方法会尝试多个 λ 值,并选择使验证集上的性能最好的那个值。
-
评估模型性能:在找到最优 λ 值后,使用整个训练集重新训练模型,并在独立的测试集上评估模型的最终性能。
-
调整和迭代:根据模型在测试集上的表现,可能需要回到步骤3,尝试不同的 λ 值或调整其他超参数,以进一步优化模型。
4. 总结
通过调整正则化参数 λ,可以控制模型的复杂度,从而影响模型的偏差和方差:
-
大 λ:模型过于简单,高偏差。
-
适中 λ:模型复杂度适中,泛化能力好。
-
小 λ:模型过于复杂,高方差。
通过交叉验证,我们可以找到一个合适的λ值,让模型在训练集和验证集上都有很好的表现,同时也能更好地泛化到新的数据上。
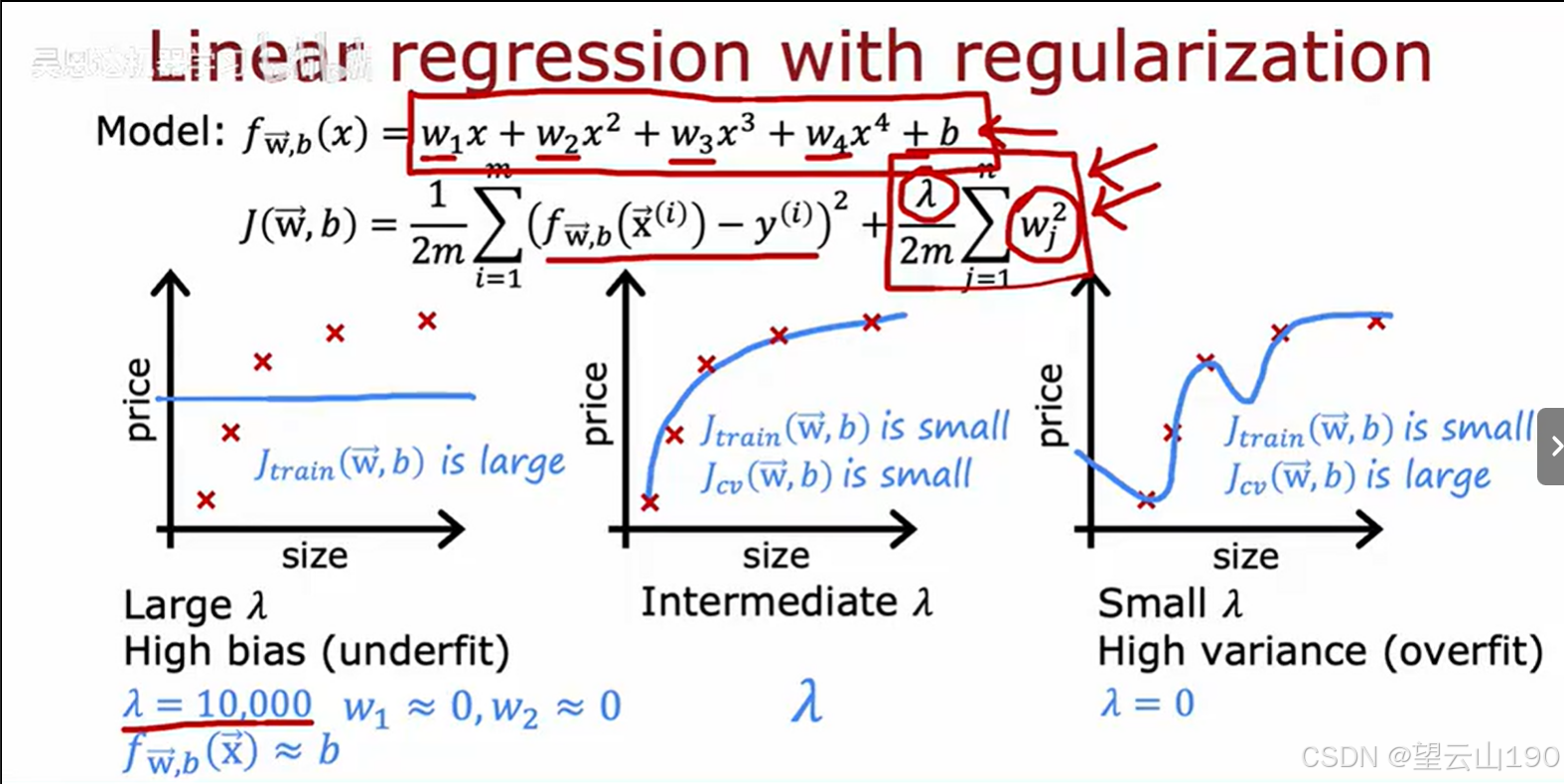
这张照片展示了正则化在线性回归中的应用,特别是如何通过调整正则化参数λ来控制模型的偏差和方差。
模型公式
-
模型:fw,b(x)=w1x+w2x2+w3x3+w4x4+b
-
这是一个四阶多项式模型,其中 w1,w2,w3,w4 是模型参数,b 是偏置项。
-
成本函数
-
成本函数:J(w,b)=2m1∑i=1m(fw,b(x(i))−y(i))2+2mλ∑j=1nwj2
-
第一部分是均方误差,衡量模型预测与实际值之间的差异。
-
第二部分是正则化项,其中 λ 是正则化参数,控制模型复杂度。
-
图表解释
-
左图(大λ):
-
当 λ=10,000 时,模型参数 w1,w2 接近于0,模型简化为 fw,b(x)≈b,即一个常数函数。
-
这种情况下,模型在训练集上的误差较大(Jtrain(w,b) is large),表现出高偏差(underfit)。
-
-
中图(适中λ):
-
当选择一个适中的 λ 值时,模型能够较好地拟合数据。
-
此时,模型在训练集和交叉验证集上的误差都较小(Jtrain(w,b) is small 和 Jcv(w,b) is small),表现出良好的泛化能力。
-
-
右图(小λ):
-
当 λ=0 时,模型没有正则化,可能会过拟合数据。
-
这种情况下,模型在训练集上的误差较小(Jtrain(w,b) is small),但在交叉验证集上的误差较大(Jcv(w,b) is large),表现出高方差(overfit)。
-
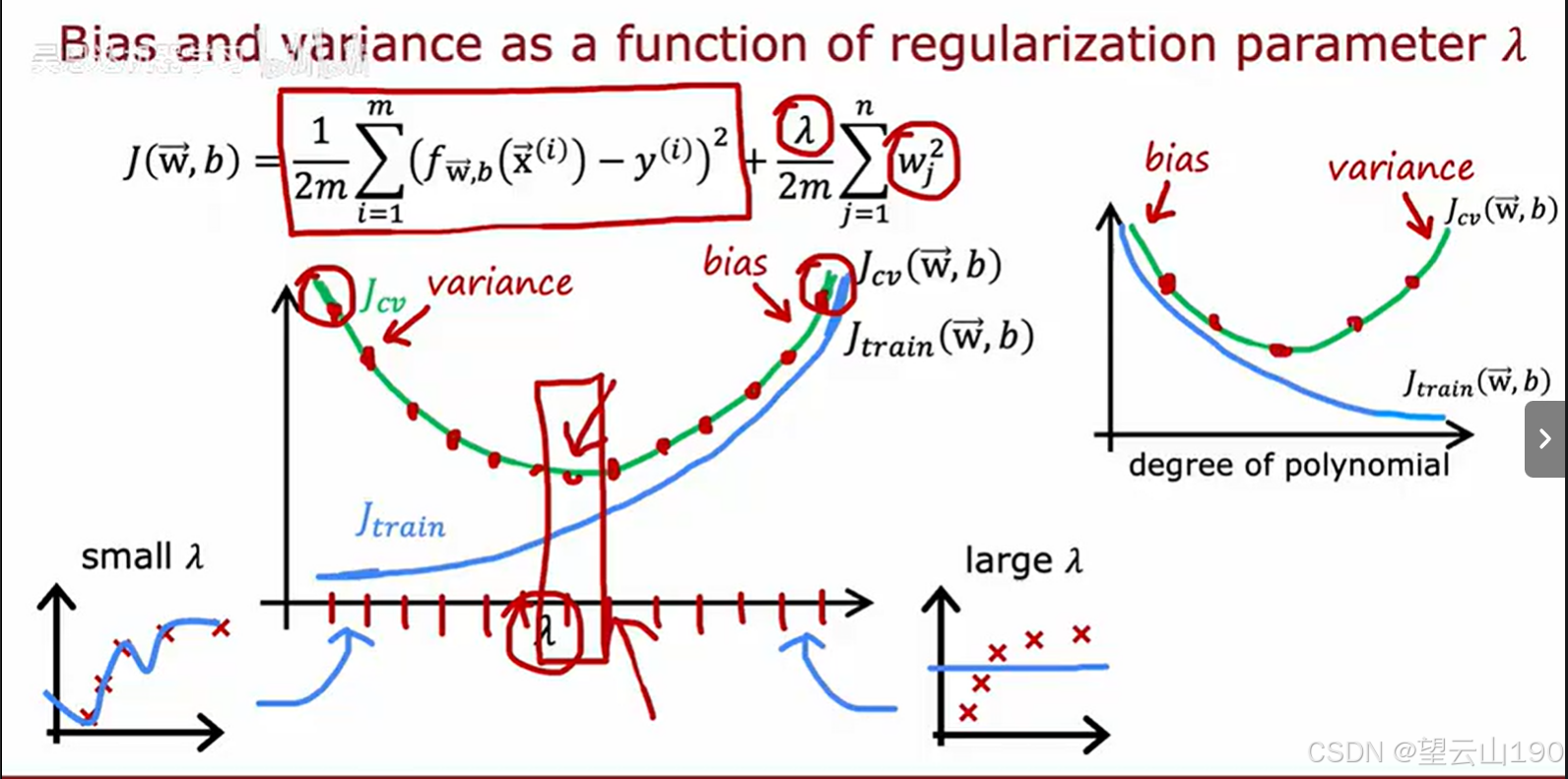
图片展示了两个图表,分别描述了训练误差(Jtrain(w,b))和交叉验证误差(Jcv(w,b))如何随着正则化参数 λ 的变化而变化。
-
左图:展示了当 λ 较小时(对应于模型复杂度较高),训练误差和交叉验证误差都较小,但随着 λ 增加(模型复杂度降低),训练误差会逐渐增大,而交叉验证误差先减小后增大,表现出U型曲线。
-
右图:展示了随着多项式次数的增加,训练误差和交叉验证误差的变化。随着多项式次数的增加,训练误差逐渐减小,但交叉验证误差先减小后增大,同样表现出U型曲线。
交叉验证的作用
交叉验证是一种评估模型泛化能力的方法,通过尝试多个不同的 λ 值,并评估每个值对应的交叉验证误差,我们可以找到一个使交叉验证误差最小的 λ 值。这个 λ 值能够平衡模型的偏差和方差,从而在训练集和验证集上都表现良好。
总结
通过调整正则化参数 λ,我们可以控制模型的复杂度,从而影响模型的偏差和方差。小 λ 可能导致高方差(过拟合),而大 λ 可能导致高偏差(欠拟合)。通过交叉验证,我们可以找到一个合适的 λ 值,使得模型在训练集和验证集上都能有良好的表现,从而提高模型的泛化能力。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









