







如何为机器学习算法选择合适的模型
在机器学习中,选择一个好的模型是至关重要的。然而,仅仅通过训练集的误差来评估模型的性能是不够的,因为训练误差可能会因为模型过度拟合而变得很低,但模型在新数据上的表现可能很差。因此,我们需要一种更可靠的方法来评估模型的泛化能力,即模型在未见过的新数据上的表现。
1. 训练集与测试集的局限性
通常,我们会将数据分为训练集和测试集。训练集用于训练模型,而测试集用于评估模型的性能。然而,如果直接使用测试集来选择模型,比如选择多项式的阶数或其他超参数,那么测试集的误差可能会变得过于乐观,因为它已经参与了模型的选择过程。这种情况下,测试集的误差不再是模型泛化能力的真实反映。
2. 引入交叉验证集
为了避免上述问题,我们可以将数据分为三个部分:训练集、交叉验证集和测试集。交叉验证集的作用是用于模型选择,即选择最适合的模型参数(如多项式的阶数、神经网络的结构等),而测试集则用于最终评估模型的泛化能力。
-
训练集:用于训练模型,拟合模型参数(如权重 w 和偏置 b)。
-
交叉验证集:用于选择模型的超参数(如多项式的阶数 d),并评估不同模型的性能。
-
测试集:用于最终评估选定模型的泛化能力,确保模型在未见过的数据上表现良好。
3. 模型选择的具体步骤
假设我们要选择一个多项式回归模型,具体步骤如下:
-
数据划分:
-
将数据分为三个部分:训练集、交叉验证集和测试集。例如,如果有10个数据点,可以将6个数据点作为训练集,2个作为交叉验证集,2个作为测试集。
-
-
训练模型:
-
对于不同的多项式阶数 d(如 d=1,2,3,…,10),分别使用训练集拟合模型,得到对应的参数 wd 和 bd。
-
-
评估模型:
-
使用交叉验证集计算每个模型的交叉验证误差 Jcv(wd,bd)。选择交叉验证误差最小的模型,假设 d=4 的模型具有最小的交叉验证误差,那么就选择 d=4 的多项式模型。
-
-
最终评估:
-
使用测试集计算选定模型的测试误差 Jtest(w4,b4)。这个测试误差是模型泛化能力的公平估计,因为它没有参与模型的选择过程。
-
4. 应用到其他模型
这种方法不仅适用于多项式回归,还可以用于其他类型的模型选择,例如神经网络结构的选择。例如:
-
假设我们有三种不同结构的神经网络,分别训练这些模型。
-
使用交叉验证集计算每个模型的交叉验证误差 Jcv,选择误差最小的模型。
-
最后,使用测试集评估选定模型的泛化能力。
5. 注意事项
-
独立性:在模型选择过程中,测试集应该完全独立于训练和交叉验证过程。只有在最终评估时才使用测试集。
-
公平性:通过将测试集与模型选择过程隔离,可以确保测试集误差是一个公平的泛化能力估计,而不是过于乐观的估计。
如何修改训练和测试过程以进行模型选择
为了更好地选择合适的模型,我们通常需要对数据进行更细致的划分。传统的做法是将数据分为训练集和测试集,但这种方法在模型选择时可能会导致测试集误差过于乐观。为了避免这个问题,我们可以将数据分为三个子集:训练集、交叉验证集和测试集。
数据划分的具体步骤
-
划分比例:
-
假设我们有10个数据样本,可以按照以下比例进行划分:
-
60%的数据作为训练集:用于训练模型,拟合模型参数。
-
20%的数据作为交叉验证集:用于评估不同模型的性能,选择最优模型。
-
20%的数据作为测试集:用于最终评估选定模型的泛化能力。
-
-
-
具体数量:
-
在我们的例子中,10个数据样本可以划分为:
-
训练集:6个样本(60%)。
-
交叉验证集:2个样本(20%)。
-
测试集:2个样本(20%)。
-
-
-
符号表示:
-
训练集:用 Xtrain 表示,包含6个训练样本。
-
交叉验证集:用 Xcv 表示,包含2个交叉验证样本。这里的“cv”代表“交叉验证”(Cross-Validation)。
-
测试集:用 Xtest 表示,包含2个测试样本。
-
交叉验证集的作用
交叉验证集的主要作用是帮助我们评估不同模型的性能,从而选择最优的模型。它是一个额外的数据集,用于检查或交叉验证模型的有效性和准确性。在一些应用场景中,交叉验证集也被称为验证集(Validation Set)或开发集(Development Set),但它们的含义基本相同。
通过引入交叉验证集,我们可以更客观地评估模型的性能,避免直接使用测试集进行模型选择而导致的误差估计过于乐观的问题。最终,测试集仅用于评估选定模型的泛化能力,确保其在未见过的数据上表现良好。
为什么这种方法有效
在整个过程中,训练集用于拟合模型参数,交叉验证集用于选择模型的超参数(如多项式的阶数 d),而测试集仅用于评估最终选定模型的泛化能力。通过这种方式,我们确保了测试集的独立性,避免了测试集误差过于乐观的问题。
-
训练集:拟合模型参数 w 和 b。
-
交叉验证集:选择模型的超参数 d。
-
测试集:评估选定模型的泛化能力。
适用范围
这种方法不仅适用于多项式回归模型,还可以应用于其他类型的模型选择,例如神经网络结构的选择、支持向量机的核函数选择等。通过将数据划分为三个子集,并合理利用每个子集的作用,可以更科学地选择最优模型,提高模型的泛化能力。
机器学习模型在不同数据集(训练集、交叉验证集和测试集)上的误差的。
1. 训练误差(Training error)

这个公式计算的是模型在训练集上的平均平方误差,它衡量了模型对训练数据的拟合程度。平方误差被广泛使用是因为它可以放大较大的误差,使得优化算法更关注减少这些大误差。
2. 交叉验证误差(Cross validation error)

交叉验证误差的计算方式与训练误差类似,但它是在交叉验证集上计算的,这有助于评估模型对未参与训练的新数据的泛化能力。通过比较不同模型或不同参数设置下的交叉验证误差,可以选择出最优的模型。
3. 测试误差(Test error)

测试误差是在完全独立的测试集上计算的,用于最终评估选定模型的泛化能力。这个误差提供了模型在实际应用中可能表现的估计,因为它是在模型选择过程之后,且未参与模型训练或选择的数据上计算的。
总结
这些公式都是基于平方误差的,因为平方误差可以放大较大的预测误差,从而在模型训练过程中给予这些误差更多的关注。通过计算这些误差,我们可以评估模型在不同数据集上的表现,并据此进行模型选择和评估。

如何使用不同阶数的多项式模型来进行模型选择,并估计模型的泛化误差。整个过程可以分为以下几个步骤:
1. 定义多项式模型
对于不同的多项式阶数 d,定义模型:
-
当 d=1 时,模型为 fw,b(x)=w1x1+b
-
当 d=2 时,模型为 fw,b(x)=w1x1+w2x2+b
-
当 d=3 时,模型为 fw,b(x)=w1x1+w2x2+w3x3+b
-
以此类推,直到 d=10 时,模型为 fw,b(x)=w1x1+w2x2+⋯+w10x10+b
2. 训练模型并计算交叉验证误差
对于每个阶数 d 的模型,使用训练集拟合模型参数 w 和 b,然后在交叉验证集上计算交叉验证误差 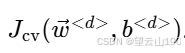
3. 选择最佳模型
比较不同阶数模型的交叉验证误差,选择交叉验证误差最低的模型。例如,如果 d=4 时的交叉验证误差最低,即 Jcv(w<4>,b<4>) 最小,则选择 d=4 的模型。
4. 估计泛化误差
使用测试集估计选定模型的泛化误差。对于选定的 d=4 的模型,计算测试误差 Jtest(w<4>,b<4>)。这个误差提供了模型在未见过的数据上可能表现的估计。
图片解释
图片中展示了这个过程:
-
左侧列出了不同阶数 d 的多项式模型。
-
中间部分展示了对于每个模型,如何使用训练集拟合参数,并在交叉验证集上计算交叉验证误差 Jcv。
-
右侧展示了如何选择交叉验证误差最低的模型,并使用测试集估计其泛化误差。
关键点
-
交叉验证误差:用于模型选择,因为它评估了模型对未参与训练的新数据的泛化能力。
-
测试误差:用于估计选定模型的泛化能力,因为它是在完全独立的测试集上计算的,未参与模型的训练或选择过程。

如何在机器学习中,特别是神经网络模型中,进行模型选择和评估泛化误差的过程。以下是详细的步骤和解释:
图片展示了三种不同的神经网络架构,每种架构都有不同数量的隐藏层和隐藏单元:
-
第一个神经网络:
-
输入层有25个单元,一个隐藏层有15个单元,输出层有1个单元。
-
训练后得到的参数为 w(1),b(1)。
-
在交叉验证集上计算的交叉验证误差为 Jcv(w(1),b(1))。
-
-
第二个神经网络:
-
输入层有20个单元,两个隐藏层分别有12和20个单元,输出层有1个单元。
-
训练后得到的参数为 w(2),b(2)。
-
在交叉验证集上计算的交叉验证误差为 Jcv(w(2),b(2))。
-
-
第三个神经网络:
-
输入层有32个单元,三个隐藏层分别有16、8和12个单元,输出层有1个单元。
-
训练后得到的参数为 w(3),b(3)。
-
在交叉验证集上计算的交叉验证误差为 Jcv(w(3),b(3))。
-
模型选择过程
-
训练模型:
-
对于每种神经网络架构,使用训练集拟合模型参数。
-
-
计算交叉验证误差:
-
对于每种模型,使用交叉验证集计算交叉验证误差 Jcv。
-
-
选择最佳模型:
-
比较不同模型的交叉验证误差,选择误差最低的模型。在这个例子中,选择了第二个神经网络,即 w(2),b(2)。
-
-
估计泛化误差:
-
使用测试集估计选定模型的泛化误差。对于选定的第二个神经网络,计算测试误差 Jtest(w(2),b(2))。
-
文字解释
这段话进一步解释了这个过程的重要性和最佳实践:
-
交叉验证误差:用于评估模型在未参与训练的新数据上的性能,从而选择最优的模型。
-
测试误差:用于最终评估选定模型的泛化能力,确保模型在未见过的数据上表现良好。
-
最佳实践:在模型选择过程中,只使用训练集和交叉验证集,不使用测试集。这样可以确保测试集的独立性,避免过拟合,从而提供一个公平的泛化误差估计。
通过这种方法,可以科学地选择最优的神经网络架构,并准确估计其在实际应用中的性能。

















 1391
1391

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









