






Logistic回归
基本概念:
-
Logistic回归用于二分类问题,输出标签 y 只有两个可能的值(0或1)。
-
通过计算 z=w⋅x+b 来预测 y=1 的概率。
-
使用逻辑函数 g(z)=1+e−z1 来计算概率 a1=P(y=1∣x)。
-
a2=1−a1=P(y=0∣x)。
损失函数:
-
使用对数损失函数(Log Loss)来衡量预测概率与真实标签之间的差异。
-
损失函数为 loss=−yloga1−(1−y)log(1−a1)。
-
如果 y=1,则损失为 −loga1;如果 y=0,则损失为 −log(1−a1)。
-
成本函数 J(w,b) 是所有训练样本的平均损失。
Softmax回归
基本概念:
Softmax回归用于多分类问题,输出标签 y 可以有多个可能的值(例如1, 2, 3, ..., N)
-
对于每个类别 j,计算 zj=wj⋅x+bj。
-
所有类别的概率之和为1,即 a1+a2+...+aN=1。
-

损失函数:
-
使用交叉熵损失函数(Cross-Entropy Loss)来衡量预测概率分布与真实标签之间的差异。
-
损失函数为 loss(a1,...,aN,y)=−logay,其中 y 是真实类别。
-
如果真实类别是 y=j,则损失为 −logaj。
-
交叉熵损失函数的图形表示显示,当预测概率 aj 接近1时,损失很小;当 aj 较小时,损失较大。

好的,让我们仔细分析这两张图,以便更好地理解Logistic回归和Softmax回归的工作原理和区别。
第一张图:Logistic回归与Softmax回归的对比
Logistic回归部分(左侧):
-
公式:
-
z=w⋅x+b:这是线性模型的计算公式,其中 w 是权重向量,x 是输入特征向量,b 是偏置项。
-
a1=g(z)=1/1+e−z1:这是逻辑函数(sigmoid function),用于计算 y=1 的概率。
-
a2=1−a1:这是 y=0 的概率。
-
-
概率计算:
-
a1=P(y=1∣x):给定输入特征 x,属于类别1的概率。
-
a2=P(y=0∣x):给定输入特征 x,属于类别0的概率。
-
-
参数:
-
w 和 b 是模型的参数,需要通过训练数据学习得到。
-
Softmax回归部分(右侧):
-
公式:
-
zj=wj⋅x+bj:这是每个类别的线性模型计算公式,其中 wj 和 bj 是第 j 类的权重向量和偏置项。
-
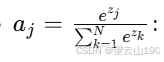 :这是Softmax函数,用于计算每个类别的概率。
:这是Softmax函数,用于计算每个类别的概率。
-
-
概率计算:
-
aj=P(y=j∣x):给定输入特征 x,属于类别 j 的概率。
-
所有类别的概率之和为1,即 a1+a2+...+aN=1。
-
-
参数:
-
wj 和 bj 是每个类别的模型参数,需要通过训练数据学习得到。
-
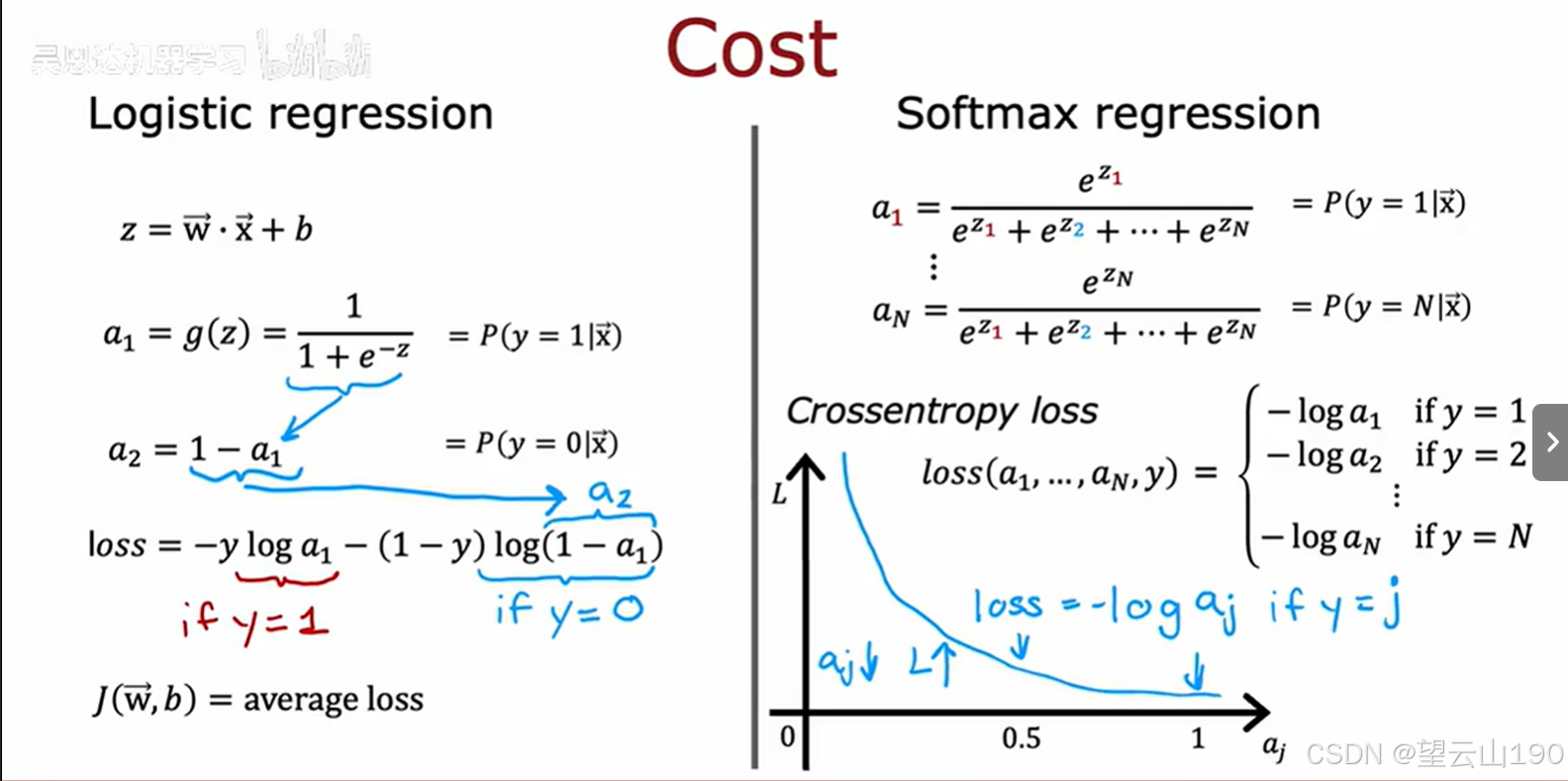
第二张图:Logistic回归与Softmax回归的损失函数
Logistic回归部分(左侧):
-
损失函数:
-
loss=−yloga1−(1−y)log(1−a1):这是对数损失函数(Log Loss),用于衡量预测概率与真实标签之间的差异。
-
如果 y=1,则损失为 −loga1;如果 y=0,则损失为 −log(1−a1)。
-
-
成本函数:
-
J(w,b) 是所有训练样本的平均损失,用于优化模型参数。
-
Softmax回归部分(右侧):

总结:
区别:
总结来说,Logistic回归是Softmax回归在二分类问题上的特例。当类别数为2时,Softmax回归简化为Logistic回归。在实际应用中,根据问题的类别数量选择合适的模型是非常重要的。
-
Logistic回归适用于二分类问题,使用逻辑函数计算概率,并使用对数损失函数衡量预测与真实标签之间的差异。
-
Softmax回归适用于多分类问题,使用Softmax函数计算每个类别的概率,并使用交叉熵损失函数衡量预测与真实标签之间的差异。
-
两张图分别展示了Logistic回归和Softmax回归的计算过程和损失函数,帮助我们更好地理解它们的工作原理和区别。
Logistic回归和Softmax回归都是线性分类模型,用于解决分类问题,但它们在处理类别数量上有所不同。以下是它们之间的联系和区别:
联系:
-
线性模型:两者都是线性模型,意味着它们都试图找到一个线性决策边界来区分不同的类别。
-
概率输出:两者都输出类别的概率,这些概率可以解释为给定输入特征属于各个类别的可能性。
-
损失函数:两者都使用对数损失函数(Log Loss),即交叉熵损失,来衡量预测概率分布与真实标签之间的差异。
-
参数学习:两者都通过优化损失函数来学习模型参数,通常使用梯度下降或其变体。
-
类别数量:
-
Logistic回归:适用于二分类问题,即输出标签只有两个可能的值(0或1)。
-
Softmax回归:适用于多分类问题,即输出标签有多个可能的值(1, 2, 3, ..., N)。
-
-
输出概率计算:
-
Logistic回归:使用逻辑函数(sigmoid function)计算属于一个类别的概率,另一个类别的概率由1减去这个概率得到。
-
Softmax回归:使用Softmax函数计算属于每个类别的概率,所有类别的概率之和为1。
-
-
决策边界:
-
Logistic回归:在二维特征空间中,决策边界是一条直线。
-
Softmax回归:在多维特征空间中,决策边界是超平面,数量等于类别数减一。
-
-
应用场景:
-
Logistic回归:适用于简单的二分类问题,如垃圾邮件检测、疾病诊断等。
-
Softmax回归:适用于更复杂的多分类问题,如手写数字识别、图像分类等。
-
-
数学复杂性:
-
Logistic回归:数学上更简单,因为只涉及一个逻辑函数。
-
Softmax回归:数学上更复杂,因为需要计算所有类别的概率。
-
-
计算效率:
-
Logistic回归:计算效率较高,因为只涉及一次逻辑函数的计算。
-
Softmax回归:计算效率较低,因为需要计算所有类别的指数和Softmax函数。
-

















 1231
1231

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









