







4.6.1 什么是无监督学习
没有目标值/从无标签的数据开始学习-无监督学习
eg:

4.6.2 无监督学习包含算法
聚类-K-means(K均值聚类)
降维-PCA
4.6.3 K-means原理
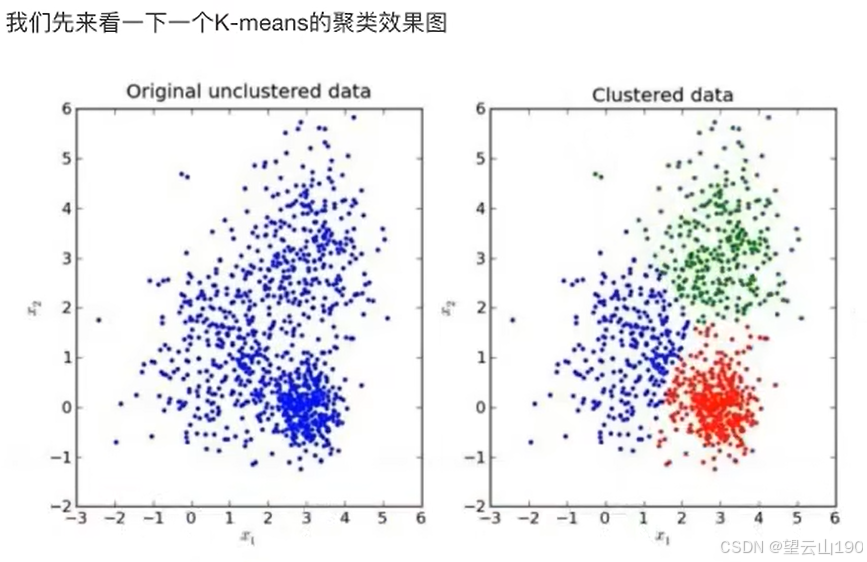
K-means聚类步骤:
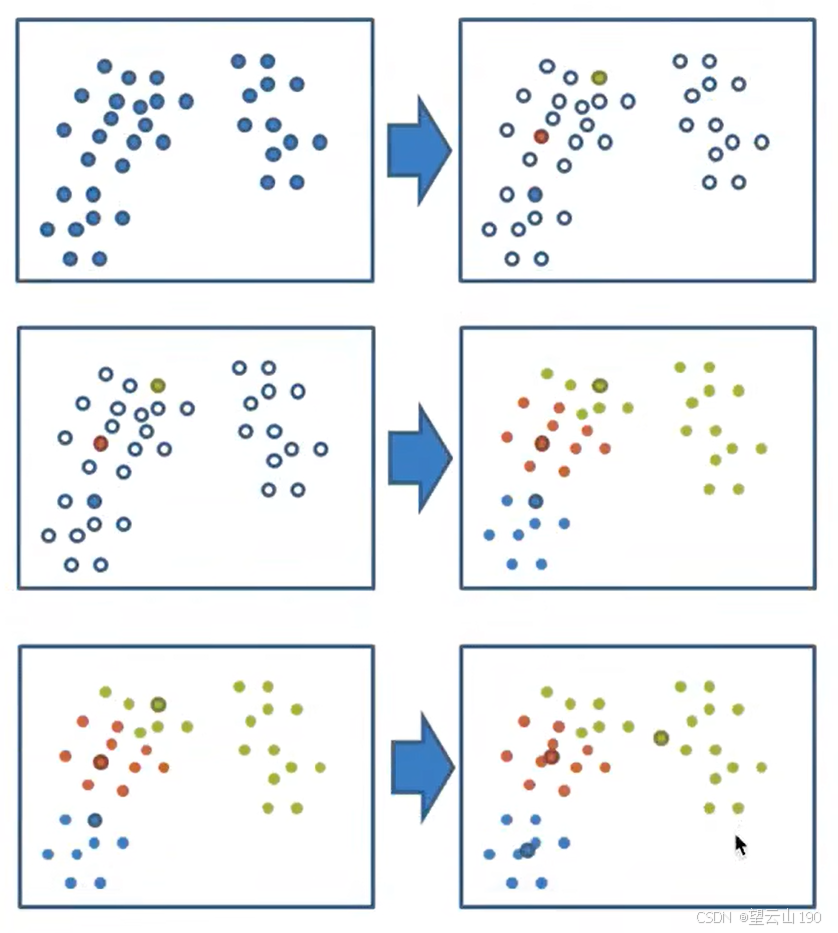
1.随机设置K个特征空间内的点作为初始的聚类中心
2.对于其他每个点计算到K个中心的距离,未知的点选择最近的一个聚类中心点作为标记类别
3.截止对着标记的聚类中心之后,重新计算每个聚类的新中心点(平均值)
4.如果计算得出的新中心点与原中心点一样,那么结束,否则重新进行第二步过程
我们一张图来解释效果:
K-超参数
1)看需求(找几个点)
2)调节超参数
eg:如果随机找三个点,那么K=3
4.6.4 K-means API

4.6.5 案例:k-means对Instacrt Market用户聚类
k=3
流程分析:
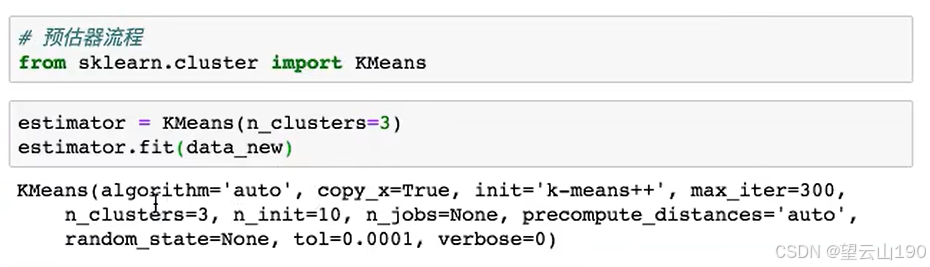
1)预估器流程
2)看结果
3)模型评估
4.6.6 K-means性能评估指标
1 轮廓系数
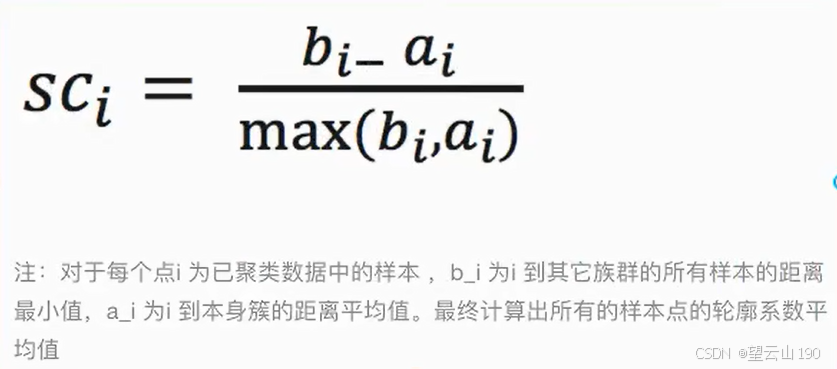
内部距离最小化,外部距离最大化
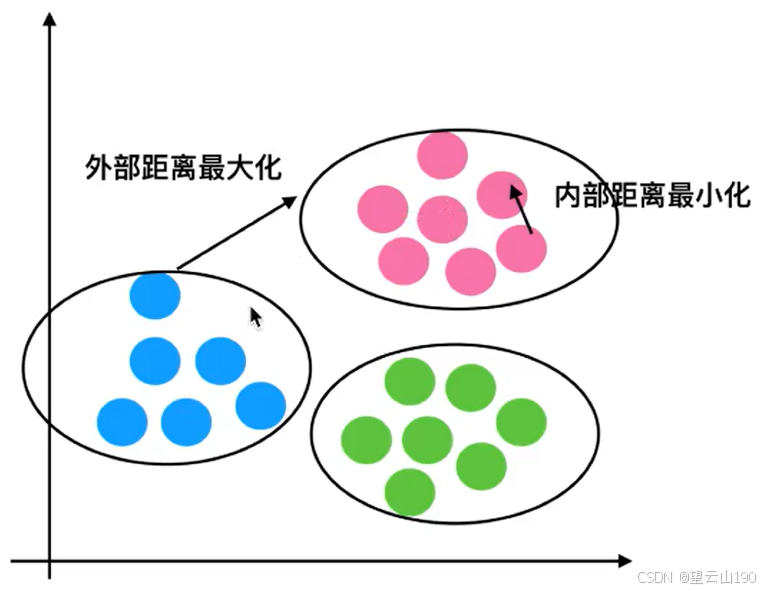

2 结论
如果b_i>>a:趋近于1,效果更好;如果b_i<<a:趋近于-1,效果不好;轮廓系数的值是介于【-1,1】,越趋近于1代表内聚度和分散度都相对较优。
3 轮廓系数API

4 用户聚类结果评估

4.6.7 K-means总结
特点分析:采用迭代式算法,直观易懂并且非常实用
缺点:容易收敛到局部最优解(多次聚类)
注意:聚类一般做在分类之前


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









