






一.机器学习——监督学习与无监督学习、分类、回归、标注、推荐系统、序列问题
- 监督学习:
擅长在“给定输入特征”的情况下预测标签。每个“特征-标签”对都称为一个样本(example)。我们的目标是生成一个模型,能够将任何输入特征映射到标签(即预测)。
监督学习的学习过程:
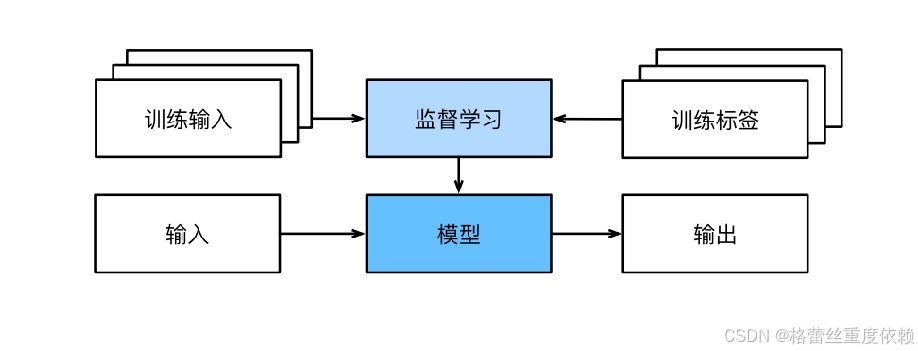
(按照老师的讲解,监督学习与无监督学习的区别说白了就是有无标签)
- 无监督学习:
数据中不含有标签的机器学习问题。(包含以下几项问题)
- 聚类问题
- 主成分分析问题
- 因果关系和概率图模型(白噪图)
- 生成对抗网络
- 回归问题——平方误差损失函数
回归是训练一个回归函数来输出一个数值;
回归是最简单的监督学习任务之一。平方误差可以预测结果与实际的差距。(一般相差不大,比如实际值是9,预测值大概也许会在8~10之间)
- 分类问题——交叉熵
分类是训练一个分类器来输出预测的类别。
样本属于“哪一类”的问题称为分类问题。分类问题希望模型能够预测样本属于哪个类别。有二项分类与多项分类。
比如:

猫狗识别:二项识别(因为不是猫就是狗)
同理可得男女分类也是二项识别。
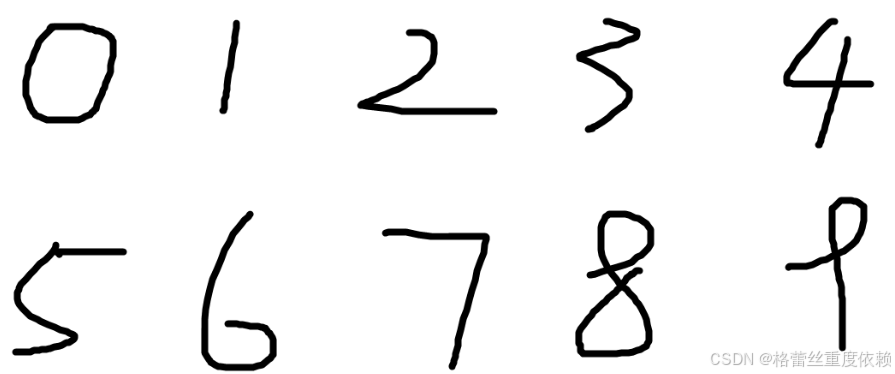
手写数字识别:多项识别
- 标注问题
学习预测不相互排斥的类别的问题称为多标签分类 (multi-label classification)一个样本(一个图片或者一个候选框)中含有多个物体,标注的label也是多个的,多个类间并不是互斥的,多选多比如:多目标检测、短视频分类
- 推荐系统
(推荐系统千人千面,如果面对不同的人推荐相同的东西,那这个推荐系统也许做的不是很成功)
目标是向特定用户进行“个性化”推荐。例如,对于电影推荐,科幻迷和喜剧爱好者的推荐结果页面可能会有很大不同。
- 序列问题
·输入和输出都是可变长度的序列。(标记和解析,自动语音识别,文本到语音,机器翻译)
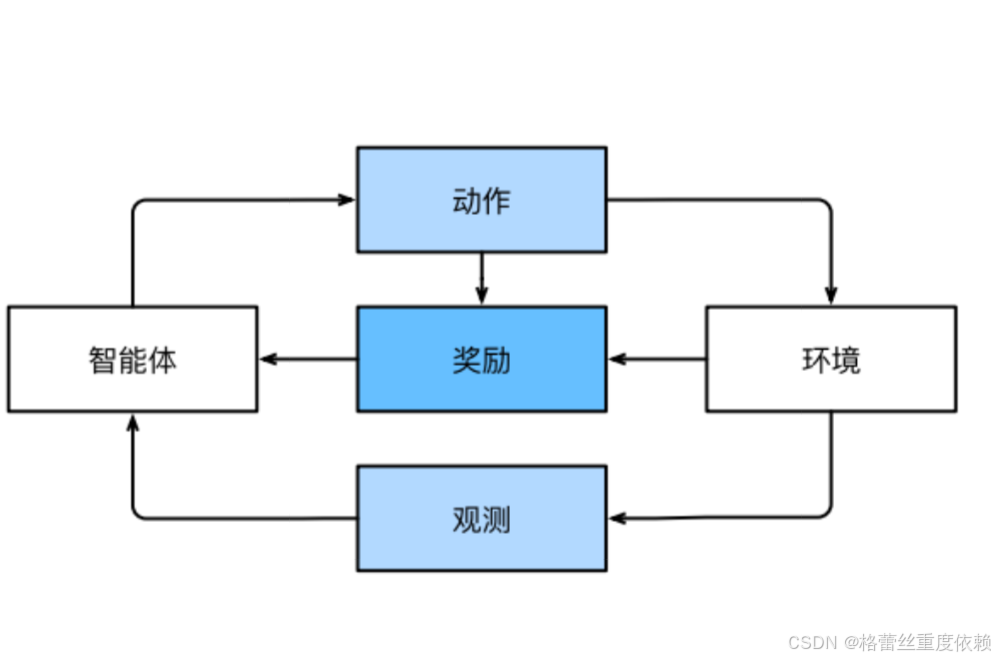
二.深度学习(强化学习)
智能体在一系列的时间步骤上与环境交互。在每个特定时间点,智能体从环境接收一些观察,并且必须选择一个动作,然后通过某种机制(有时称为执行器)将其传输回环境,最后智能体从环境中获得奖励。此后新一轮循环开始,智能体接收后续观察,并选择后续操作,依此类推。
三.回归到多分类
回归:三个连续数值输出,自然区间与真实值的区别作为损失。
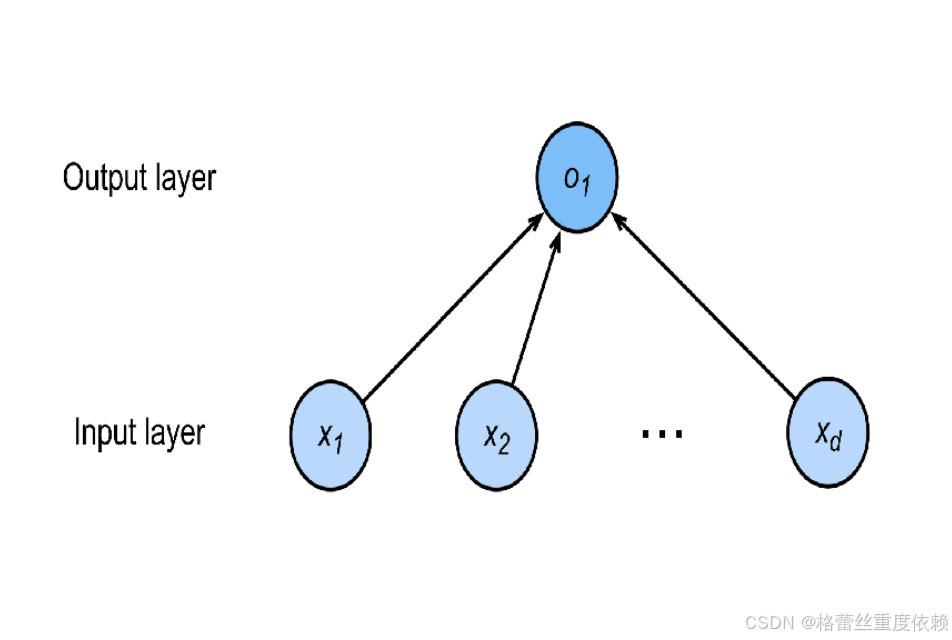
分类:通常多个输出,输出的i表示预测为第i类的置信度。
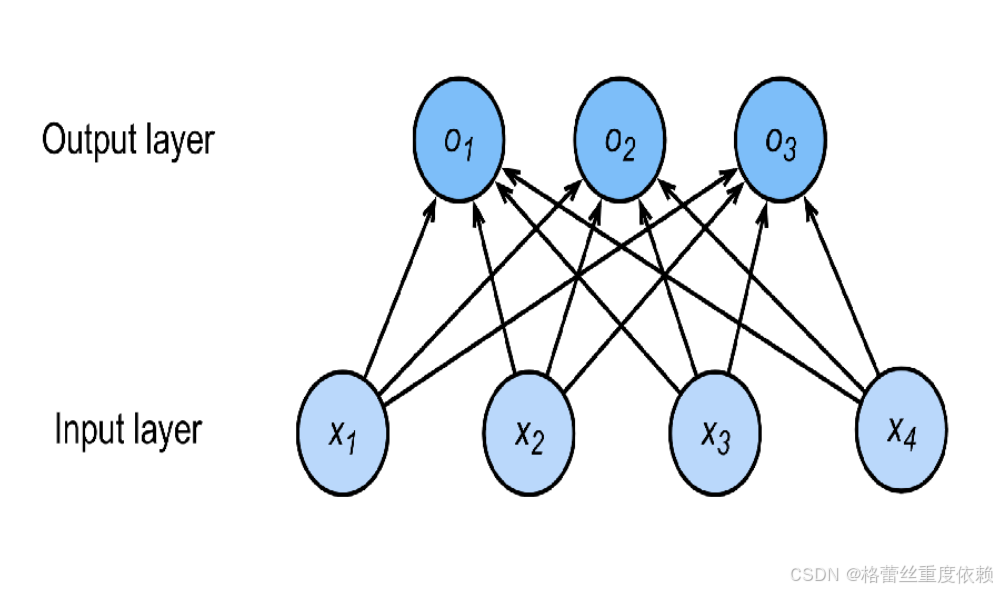
例如:
一张图片进行预测
x₁=o₁=猫 x₂=o₂=狗 x₃=o₃=熊 x₄=鹿
o₁=0.6 o₂=0.3 o₃=0.1
那最后预测的结果是猫
(因为使用均方损失训练,最大值作为预测结果)
四.损失函数
Huber损失
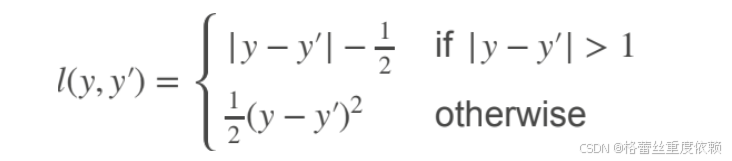
交叉熵
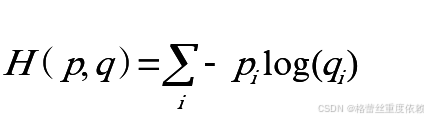
通常用于比较概率分布
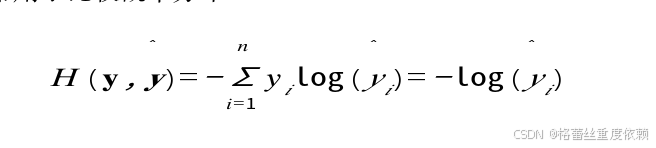
所学内容已总结完毕 (*^▽^*)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









