






写在开头:
写这篇博客的是因为本人在学习tensorRT的过程中发现,很多tensorRT的相关教程存在如下五个方面的问题:1.版本过时,很多api已经弃用。2.讲解复杂,不符合入门学习需求3.C语言较少,大多数是Python的部署方案4.无重复调用,代码的鲁棒性较低。5.系统单一,大多数是windows上的教程,ubuntu较少
因此本人在经过一段时间的学习后将自己的学习成果进行分享,希望能帮助到tensorRT的初学者来快速的找到学习的大方向。由于本人也尚在学习中,所以文中如果有错误,欢迎进行指正。
ps:本文不涉及环境的搭建,在阅读之前可以参考本文1.2内容的链接,查阅相关资料完成环境的搭建
1 基本概述
1.1 什么是TensorRT
NVIDIA TensorRT 是一个专为深度学习推理设计的高性能优化器和运行时库,它通过一系列先进的优化技术(如采用半精度浮点来简化计算),显著提升深度学习模型在推理阶段的速度和数据处理能力,同时有效减少推理过程中的延迟,从而确保模型在实际应用中能够快速响应,满足实时性和高效率的要求。
1.2 开发环境
以本文代码对应的开发环境为例:ubuntu20.04;RTX4060笔记本版本;opencv版本:4.6.0;Nvidia驱动版本:535.183.01;Cuda版本:11.8;cudnn版本:8.9.6;TensorRT版本:10.0.1.6
要注意ubuntu系统版本和显卡驱动版本的关系,另外各个库版本之间也存在依赖关系,请在官网进行确认,以避免版本冲突带来的不必要的麻烦。
NVIDIA - CUDA | onnxruntimeInstructions to execute ONNX Runtime applications with CUDAhttps://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.html#requirementshttps://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.html#requirementshttps://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.html#requirementshttps://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.html#requirementshttps://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.html#requirementshttps://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.html#requirementshttps://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.html#requirementshttps://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.html#requirementshttps://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.html#requirements![]() https://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.html#requirementsNVIDIA - CUDA | onnxruntimeInstructions to execute ONNX Runtime applications with CUDAhttps://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.htmlhttps://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.htmlhttps://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.htmlhttps://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.htmlhttps://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.htmlhttps://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.htmlhttps://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.htmlhttps://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.htmlhttps://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.html
https://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.html#requirementsNVIDIA - CUDA | onnxruntimeInstructions to execute ONNX Runtime applications with CUDAhttps://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.htmlhttps://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.htmlhttps://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.htmlhttps://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.htmlhttps://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.htmlhttps://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.htmlhttps://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.htmlhttps://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.htmlhttps://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.html![]() https://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.htmlNVIDIA - TensorRT | onnxruntimeInstructions to execute ONNX Runtime on NVIDIA GPUs with the TensorRT execution providerhttps://onnxruntime.ai/docs/execution-providers/TensorRT-ExecutionProvider.htmlhttps://onnxruntime.ai/docs/execution-providers/TensorRT-ExecutionProvider.htmlhttps://onnxruntime.ai/docs/execution-providers/TensorRT-ExecutionProvider.htmlhttps://onnxruntime.ai/docs/execution-providers/TensorRT-ExecutionProvider.htmlhttps://onnxruntime.ai/docs/execution-providers/TensorRT-ExecutionProvider.htmlhttps://onnxruntime.ai/docs/execution-providers/TensorRT-ExecutionProvider.htmlhttps://onnxruntime.ai/docs/execution-providers/TensorRT-ExecutionProvider.htmlhttps://onnxruntime.ai/docs/execution-providers/TensorRT-ExecutionProvider.htmlhttps://onnxruntime.ai/docs/execution-providers/TensorRT-ExecutionProvider.html
https://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.htmlNVIDIA - TensorRT | onnxruntimeInstructions to execute ONNX Runtime on NVIDIA GPUs with the TensorRT execution providerhttps://onnxruntime.ai/docs/execution-providers/TensorRT-ExecutionProvider.htmlhttps://onnxruntime.ai/docs/execution-providers/TensorRT-ExecutionProvider.htmlhttps://onnxruntime.ai/docs/execution-providers/TensorRT-ExecutionProvider.htmlhttps://onnxruntime.ai/docs/execution-providers/TensorRT-ExecutionProvider.htmlhttps://onnxruntime.ai/docs/execution-providers/TensorRT-ExecutionProvider.htmlhttps://onnxruntime.ai/docs/execution-providers/TensorRT-ExecutionProvider.htmlhttps://onnxruntime.ai/docs/execution-providers/TensorRT-ExecutionProvider.htmlhttps://onnxruntime.ai/docs/execution-providers/TensorRT-ExecutionProvider.htmlhttps://onnxruntime.ai/docs/execution-providers/TensorRT-ExecutionProvider.html![]() https://onnxruntime.ai/docs/execution-providers/TensorRT-ExecutionProvider.html
https://onnxruntime.ai/docs/execution-providers/TensorRT-ExecutionProvider.html
2 TensorRT的流程概述
2.1 最完整的流程一览图
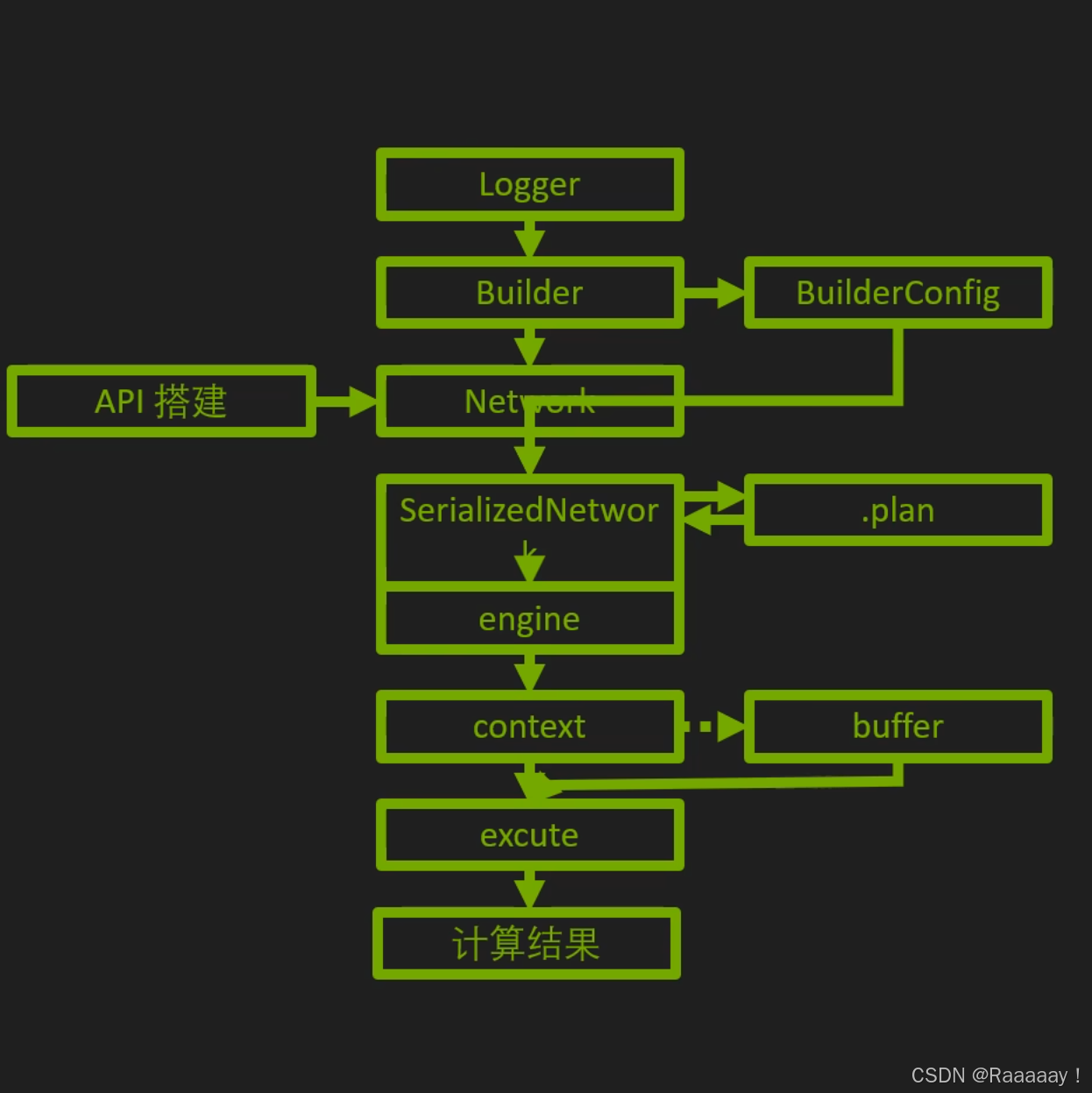
nvidia的官网流程图片如下,该图展示了一个最完整的engine构建和推理的流程,同时也是性能最高和部署难度最大的流程。这张图片无需立即看懂,但在后续的代码讲解中建议可以回过来在这张流程图上找到对应的代码所在的位置,以便更加系统的了解和学习tensorRT的部署流程
2.2 三种部署方案的对比
实际上,对于一个已经训练好的模型,TensorRT提供了三种部署方案,分别是使用框架自带的tensorRT接口;使用Praser来解析onnx模型,以及使用tensorRT的api直接构建的模型。

以下是三者详细的区别:
1. 框架自带接口:在PyTorch中直接部署。使用Torch-TensorRT进行转换,转换后的模型是一个包含TensorRT操作的PyTorch图,可以像运行普通PyTorch模型一样使用Python运行。适用于熟悉PyTorch且希望在PyTorch环境中快速部署模型的用户
2. 使用Parser:通过ONNX模型作为中间格式,使用TensorRT的ONNX Parser将ONNX模型转换为TensorRT网络图,再通过TensorRT Builder API生成优化后的TensorRT引擎。适用于需要将模型从其他框架(如TensorFlow、PyTorch等)转换为TensorRT引擎的用户
3. API搭建:使用TensorRT的C++或Python API直接构建和优化模型。这种方式提供了最低的开销和最细粒度的控制,但需要用户对TensorRT的API有较深入的了解。适用于对性能要求极高,需要最大限度减少开销,并且熟悉C++或Python API的用户
在本文中,仅对目前最范用且部署相对简单的部署方案2进行讲解
2.3 部署方案2的流程概述
假定已经有一个onnx格式的模型,那么如下的流程就是接下来代码将会展示的流程。(以下只是大概的步骤,不包含细节)
1.将onnx格式转化成序列化的推理引擎文件
2.创建全局变量logger(日志记录器)
3.创建运行时对象runtime
4.反序列化步骤一得到的的推理引擎文件
5.创建推理上下文context
6.分配主机内存,显卡显存
7.创建cuda流(cudaStream)
8.执行推理(包括前处理,前向推理,后处理)
3 代码的前置要求
3.1 将onnx格式转化推理引擎文件
有两种方式可以将ONNX模型转化为推理引擎并存储下来。第一种是编写c++实现,另外一种是使用tensorRT库自带的程序trtexec进行转化,对于希望更加深入了解tensorRT的用户可以尝试自行学习第一种方式,但考虑到本教程的目的旨在降低入门的门槛,所以会采用第二种方式进行模型的转化。
1.打开/usr/local/TensorRT-(你的版本号)/bin/目录(一般会装在/usr/local/这个路径下,但可能因为个人配置有变动),确认存在trtexec。
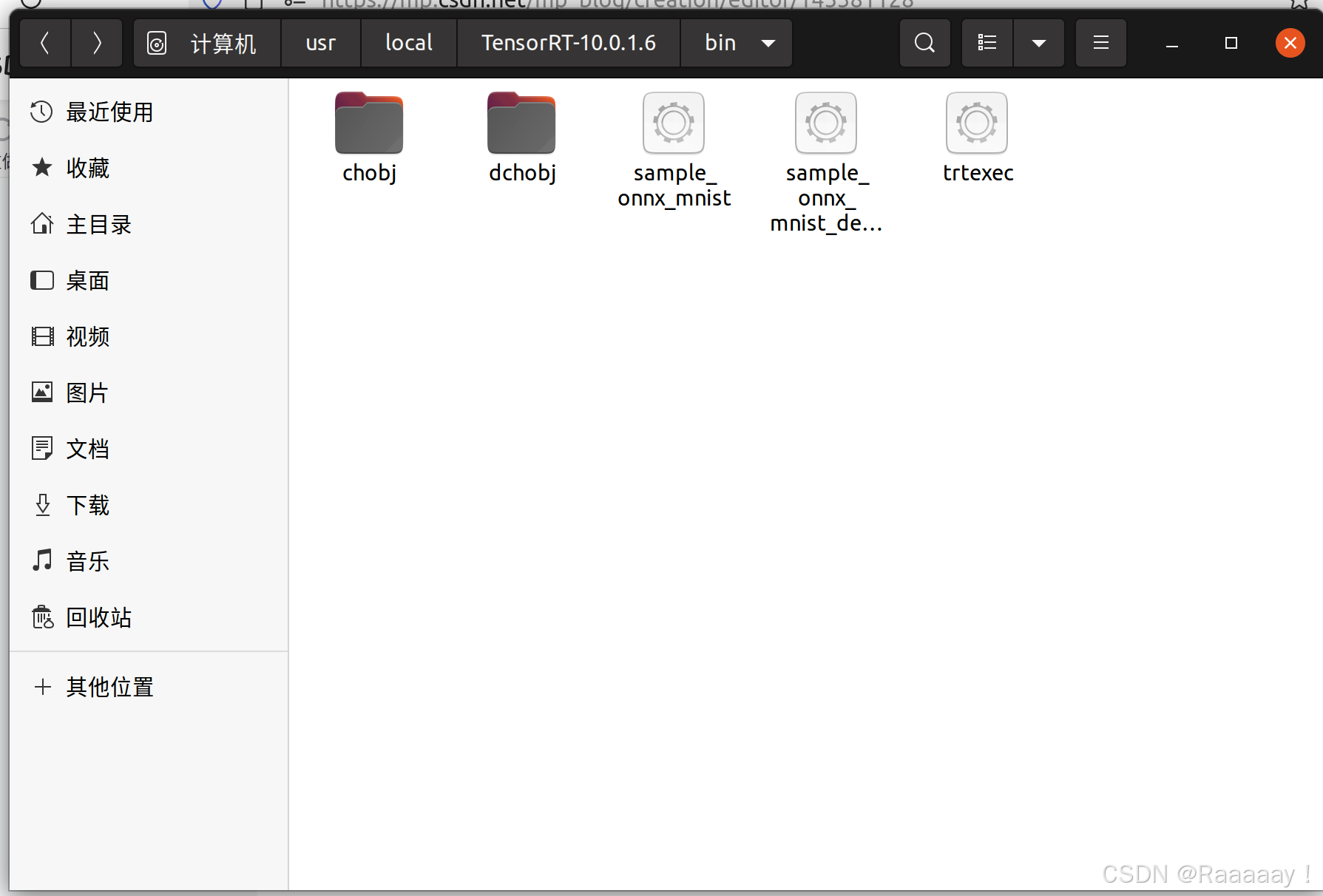
2.在这个目录下打开终端,运行如下的指令。5个参数分别对应:onnx模型路径;输出模型路径;采用半精度浮点进行优化(int8不作推荐,模型准确度会有明显损失);采用最优参数进行优化;输出详细信息
需要特别强调的是,输出模型模型的后缀可以是任意的(因为其本质是序列化的推理引擎),但是一般约定的是.trt或者.engine或者.plan。在B站2023版本的官方讲解中使用的是paln,但是为了便于理解,更加常见的做法是用engine作为后缀
./trtexec \
--onnx=路径/输入模型名.onnx \
--saveEngine=路径/输出模型名.plan \
--fp16 \
--best \
--verbose等待时间时间会比较久(这就导致不开verbose好像卡了一样),一般是3-20分钟左右,具体时间由原模型本身大小决定。
3.2 TensorRT中的重要概念
在TensorRT中,有一些重要概念。此处稍作讲解主要是为了避免后文提到之后完全不理解作用,更加详细的内容可以自行了解。
1.logger(日志器):是 TensorRT 提供的一个日志管理工具,主要用于监控 TensorRT 运行过程中的信息、警告和错误消息。
2.runtime(运行时):是 TensorRT 负责执行推理的核心组件。它提供了一种管理和执行已序列化(serialized)推理引擎的机制。可以把它理解为 TensorRT 的“执行环境”。
3.engine(推理引擎):是 TensorRT 的核心对象之一,表示经过优化的计算图,可以进行序列化存储,并在推理时反序列化到设备上运行。
4.context(执行上下文):是一个与 TensorRT 引擎绑定的运行实例。它维护了执行推理所需的所有资源,并允许在相同的 engine 上创建多个 Context 以同时执行不同的推理任务。
5.cudaStream(cuda流):是 GPU 任务的执行队列。多个cuda流可以同时执行不同的任务,实现并行计算,提高 GPU 计算效率。
4 代码示例
4.1 一些要注意的细节
这部分细节可以先大概的浏览一下,如果程序报错了可以再来仔细看一下。
1.很多api已经弃用,如:getBindingIndex();enqueueV2(); getNbTensors( );
2.推理有同步和异步两种,这里演示的是性能更高的异步推理
3.对于Yolo这样较小的模型,TensorRT的加速要在多次推理中才能体现出来,单次和一般的推理速度无明显区别
4.如果需要一直执行推理,ILogger这个类的实例就需要一直存在,所以一般可以设置为static来避免很多不必要的错误和麻烦。
5.TensorRT的优化不会影响输入或者输出张量的大小。也就是说如果原本的程序有接口,则不需要大幅改变前处理和后处理的部分的代码。
6.TensorRT的优化不会改变输入或者输出张量的名称。这两个个名称是非常关键的,涉及到内存和显存的分配。可以用Netron来查看onnx模型确定这两个名称。在一部分教程里可以看到使用的默认输出张量名称是"output\0",这是为了符合tensorrt api的一些调用条件。但实际上这是不推荐且不必要的做法,应当用c_str()来进行操作。并且绝大多数的情况下onnx默认的名称是没有\0的,所以这也是很多时候代码移植错误的原因。
4.2 头文件全文
按照cpp的书写习惯,代码分为头文件和源文件两个部分。这里头文件将全部给出并且有详细的注释,以便对照;源文件将分段给出并作详细的讲解,以便理解。建议从源文件开始阅读。
头文件yolo_trt.hpp如下,需要注意的其中很多变量已经赋予了初始值,其中很多初始值要根据实际的使用情况进行修改,并且按照我个人的编程习惯,将类私有成员分成了4组2对,分别与2个对外的接口进行对应。
/// @brief yolo_TRT_detect调用之后的返回的结构体
struct DetData
{
float confThreshold; // 置信度
int label; // 标签,即类别
cv::Rect rect; // 检测框
};
/// @brief 1280x1280对应的四种采样率的锚框的宽高
const float Anchors_1280[4][6] = { {19, 27, 44, 40, 38, 94},
{96, 68, 86, 152, 180, 137},
{140, 301, 303, 264, 238, 542},
{436, 615, 739, 380, 925, 792} };
/Yolo_TRT/
class Yolo_TRT
{
private:
void read_the_model();//读取模型
void create_the_engine();//创建推理引擎(以及日志,运行时对象)
void create_the_context();//创建推理上下文
void create_the_buffer();//创建输入输出显存缓冲区
void create_the_cudaStream();//创建cuda流
private:
std::string enginepath; //序列化后的模型路径(名称可能是.engine或.trt或.plan)
char* trtModelStream = NULL;//字符指针,指向最后存了模型信息的内存
int size = 0;//存储二进制文件字符的数量
std::unique_ptr<nvinfer1::IRuntime>runtime= NULL;//指向运行时对象
std::unique_ptr<nvinfer1::ICudaEngine>engine = NULL;//指向推理引擎的指针
std::unique_ptr<nvinfer1::IExecutionContext>context= NULL;//指向执行上下文
void **data_buffer= NULL;//void*动态数组,里面的void*指针指向每个输入和输出张量的GPU显存地址
int num_io_tensor=0;//输入输出张量的数量
std::string input_tensor_name="images";//输入张量的名字(images是默认值)
int input_tensor_index=-1;//输入张量的索引
size_t input_volume = 1.0;//输入张量的数据量(已经乘过sizeof(float)了)
std::string output_tensor_name="output";//输出张量的名字(output是默认值)
int output_tensor_index=-1;//输出张量的索引
size_t output_volume = 1.0;//输出张量的数据量(已经乘过sizeof(float)了)
float* host_output_data = NULL;//指向主机输出数据的指针
float* host_output_data_copy=NULL;//指向主机输出数据的指针的副本
private:
void preprocess_image(const cv::Mat &srcimg);//图像预处理
void do_the_infer();//进行异步传入数据,异步推理,异步传入CPU内存,同步流。
void postprocess_image(std::vector<DetData> &results);//图像后处理
private:
int input_size;//推理所需张量尺寸
cv::Mat srcimg;//原图
cv::Mat frame;//处理后的图
float ratio_w;//宽的缩放比例
float ratio_h;//高的缩放比例
float blobScale = 1.0 / 255;//归一化参数
cv::Mat blob;//张量化的图像
cudaStream_t cuda_stream;//cuda流的句柄(此时只是一个容器,调用cudaStreamCreate之后才初始化)
bool if_success;//用于判断一些操作是否成功
cudaError_t cuda_status;//cuda状态,用于判断一些cuda操作是否成功
const int totalStride=4;//1280x1280对应四种采样率
const int stride[4] = {8, 16, 32, 64};//四种采样率的值
float *anchors_1280;//指向锚框的宽高的指针
const int nout = 6;//每个锚框具有的数据个数
const float objThreshold=0.1;//锚框的置信度阈值
const float confThreshold=0.4;//最终预测结果的置信度阈值
const float nmsThreshold=0.4;//非极大值抑制的阈值
public:
//对外的接口,用于初始化推理模型
Yolo_TRT(const std::string &enginepath, int input_size);
// 对外的接口,用来创建cuda流,执行预处理,推理,后处理
void yolo_TRT_detect(const cv::Mat &srcimg, std::vector<DetData> &results);
//对外的接口,用于销毁推理模型
~Yolo_TRT();
};
/Logger/
// tensorRT推理引擎的日志,也是推理引擎和推理上下文构建的条件之一
class Logger : public nvinfer1::ILogger
{
public:
// log原本是虚函数,这里是实现。//severity是枚举变量,表示严重程度//msg是指向的消息
void log(Severity severity, const char *msg) noexcept override
{
if (severity != Severity::kINFO)//屏蔽了所有的INFO等级信息
{
std::cout << msg << std::endl;
}
}
};4.3 源文件代码详细讲解
以下的源文件代码已经进行过精简,删去了很多调试用的代码,如果需要带有调试信息的完整代码请私信与我联系。
1.构造函数
Yolo_TRT::Yolo_TRT(const std::string &enginepath, int input_size)
{
this->enginepath=enginepath;
this->input_size=input_size;
this->anchors_1280 = (float*)Anchors_1280;
read_the_model();//读取模型
create_the_engine();//创建推理引擎
create_the_context();//创建推理上下文
create_the_buffer();//创建显存缓冲区
create_the_cudaStream();//创建cuda输入流,绑定张量输入输出地址
}
为了降低构造的复杂性,只需要之前传入创建好的推理引擎文件以及yolo输入图片的尺寸的大小即可。这里采用的anchors_1280指针指向的锚框宽高需要自己确定大小,是yolo部分的内容。由于本教程的更多重心将放在tensorRT的部分,所以这里进行赘述。
2.读取模型
void Yolo_TRT::read_the_model()
{
std::ifstream file(this->enginepath, std::ios::binary);//以二进制方式打开
file.seekg(0, file.end);//将文件指针移动到文件末尾
this->size = file.tellg();//获取当前文件指针的位置,即文件的大小
file.seekg(0, file.beg);//文件指针移回文件开始处
this->trtModelStream = new char[size];//分配足够的内存储存文件内容
file.read(this->trtModelStream, this->size);//读取文件信息,并存储在trtModelStream指向的内存中
file.close();//关闭文件流
}
比较需要的注意的地方是需要用二进制的方式打开文件,因为序列化的引擎本质就是二进制的文件,其次这里new了之后不要忘记在下文delete。
3.创建(反序列化)推理引擎
void Yolo_TRT::create_the_engine()
{
//创建日志(注意这个static很重要,因为最后要传递给context)
static Logger logger;
//创建运行时对象
runtime.reset(nvinfer1::createInferRuntime(logger));
//反序列化模型数据,生成引擎
this->engine.reset(runtime->deserializeCudaEngine(this->trtModelStream, this->size));
}logger是一个日志记录器,用来输出推理中的各种信息和错误。非常重要的是,由于logger创建之后要用来创建runtime,runtime在后续要用来创建engine,engine后续要用来创建context,logger最终会被传递给context,因此logger和整个推理流程高度绑定,在需要反复持续进行推理的时候建议设置为static变量
4.创建推理(执行)上下文
void Yolo_TRT:: create_the_context()
{
//注意每个context只能在单一线程使用
//创建执行上下文
this->context.reset(engine->createExecutionContext());
//释放之前读取到的模型文件数据的内存(一般在创建执行上下文之后销毁)
delete[] trtModelStream;
}之所以单独把这个部分作为一个函数,是因为进行推理的函数其实归属于context而不是engine,可以说context是推理前的最后一步。需要注意的是context是不支持多线程的,context仅仅能在单一线程下使用。
5.分配内存与显存
void Yolo_TRT::create_the_buffer()
{
//获取输出输入张量的数目
this->num_io_tensor = engine->getNbIOTensors();
//给void*动态数组分配内存
this->data_buffer = new void *[num_io_tensor];
//计算输入张量的数据量
for (int i = 0; i < this->num_io_tensor; i++)
{
//获取名称input和output张量名称
const char *tensor_name = engine->getIOTensorName(i);
std::string I_or_O_tensor_name = tensor_name;
//输入张量
if (I_or_O_tensor_name == input_tensor_name)
{
this->input_tensor_index = i;
nvinfer1::Dims dims = engine->getTensorShape(tensor_name); // 获取张量形状(dims是一个结构体)
// 计算输入张量的数据量
this->input_volume = 1.0;
for (int j = 0; j < dims.nbDims; ++j)
{
input_volume *= dims.d[j];
}
input_volume = input_volume * sizeof(float);
this->cuda_status=cudaMalloc(&data_buffer[i], input_volume);
}
//输出张量
if (I_or_O_tensor_name == output_tensor_name)
{
this->output_tensor_index = i;
nvinfer1::Dims dims = engine->getTensorShape(tensor_name); // 获取张量形状(dims是一个结构体)
// 计算输入张量的数据量
this->output_volume = 1.0;
for (int j = 0; j < dims.nbDims; ++j)
{
output_volume *= dims.d[j];
}
output_volume = output_volume * sizeof(float);
this->cuda_status=cudaMalloc(&data_buffer[i], output_volume);
}
}
//分配主机输出数据的内存
this->cuda_status = cudaMallocHost((void **)&host_output_data, output_volume);
//创建指向主机输出数据的指针的副本
host_output_data_copy = this->host_output_data;
} tensorRT做的事情之一,就是把CPU中的数据传输到GPU中,然后让GPU作推理得到结果,再传输给CPU。在推理开始前,原始数据(如图片转化后得到的input张量)本身是有内存所以不需要分配内存。但是input张量需要传入GPU,GPU需要需要多大的显存来容纳这个张量,还需要知道推理结束之后需要多大的显存来容纳推理结果(output张量),并且由于后续要传回主机(host)内存,所以还需要确定主机(host)需要多大的内存来容纳推理结果。
可以简单的描述一下数据的流动中的位置:
原始数据张量(处于CPU输入内存)→GPU输入显存→GPU输出显存→CPU输出数据内存
这段代码的目的就是确定后三者的大小。最后一个指针副本的用途会在数据后处理中用上,尤其是在多次推理中非常有用,这与cudaMallocHost分配的内存是页锁定内存(详细内容可以自行了解)有关
6.创建cuda流
void Yolo_TRT::create_the_cudaStream()
{
//初始化cuda流句柄并放入容器
this->cuda_status = cudaStreamCreate(&cuda_stream);
//绑定张量输入地址
this->if_success=context->setTensorAddress(this->input_tensor_name.c_str(), data_buffer[this->input_tensor_index]);
//绑定张量输出地址
this->if_success=context->setTensorAddress(this->output_tensor_name.c_str(), data_buffer[this->output_tensor_index]);
}在上一步中,简单的流程是这样的:
原始数据张量(处于CPU输入内存)→GPU输入显存→GPU输出显存→CPU输出数据内存
其中载着数据流动的流就是cudaStream,而这个cudaStream的在显存里的流动方向就是这一段代码确定的。
7.对外接口,detect函数
void Yolo_TRT::yolo_TRT_detect(const cv::Mat &srcimg, std::vector<DetData> &results)
{
//图像预处理
Yolo_TRT::preprocess_image(srcimg);
//进行传入,推理,传出,同步
Yolo_TRT::do_the_infer();
//图像后处理
Yolo_TRT::postprocess_image(results);
}
这是对外的接口,接受一张图片和一个结构体向量。分别对应最原始的数据和用于装处理结果的容器,此处由于涉及到代码开源问题,所以仅会在后文详解do_the_infer()函数。
8.执行推理
void Yolo_TRT::do_the_infer()
{
//输入数据由主机输入内存到GPU输入显存
this->cuda_status=cudaMemcpyAsync(data_buffer[this->input_tensor_index], this->blob.ptr<float>(), this->input_volume, cudaMemcpyHostToDevice, this->cuda_stream);
// 执行推理
this->if_success =context->enqueueV3(this->cuda_stream);
//输出数据由GPU显存输出显存到主机输出内存
this->cuda_status=cudaMemcpyAsync(this->host_output_data, data_buffer[output_tensor_index], output_volume, cudaMemcpyDeviceToHost, this->cuda_stream);
//同步CUDA流
this->cuda_status=cudaStreamSynchronize(this->cuda_stream);
}
在上文中,cudaStream只在GPU中确定了方向,此处相当于是确定了GPU和CPU交互的方向。这里使用的推理方法是enqueueV3( ),是一种异步推理,数据一边拷贝一边计算因此性能大幅度的提升。然而我们后处理数据必须要保证数据完全拷贝了(否则会访问到无效的内存),因此在最后做了一次同步,确保了数据的完整性。
后续的步骤中,数据全部在host_output_data指向的内存中,进行后处理即可,此处不作展示。
9.析构函数
Yolo_TRT::~Yolo_TRT()
{
//释放主机内存
cudaFreeHost(host_output_data);
//释放显存
for (int i = 0; i < num_io_tensor; i++)
{
cudaFree(data_buffer[i]);
}
//释放void*动态数组
delete[] data_buffer;
//销毁cuda流
cudaStreamDestroy(cuda_stream);
}
注意,runtime,engine,context我是用智能指针管理的,因此这里没有作处理。如果不用智能指针管理,释放顺序应该是context,engine,runtime
4.4 CMakeLists和include<>
cmakelists,注意修改版本
cmake_minimum_required(VERSION 3.12)
project(Yolo_TRT)
# 查找 CUDA
find_package(CUDA REQUIRED)
include_directories(${CUDA_INCLUDE_DIRS})
link_directories(${CUDA_LIBRARY_DIRS})
# 查找 OpenCV
find_package(OpenCV REQUIRED)
include_directories(${OpenCV_INCLUDE_DIRS})
link_directories(${OpenCV_LIBRARY_DIRS})
# 包含项目头文件目录
include_directories(${PROJECT_SOURCE_DIR}/include)
# 包含 TensorRT 头文件目录
include_directories("/usr/local/TensorRT-10.0.1.6/include")
link_directories("/usr/local/TensorRT-10.0.1.6/lib")
# 添加源文件
add_executable(${PROJECT_NAME} src/main.cpp src/yolo_trt.cpp)
# 查找并链接 TensorRT 库
find_library(NVINFER_LIBRARY nvinfer PATHS "/usr/local/TensorRT-10.0.1.6/lib")
# 链接库
target_link_libraries(${PROJECT_NAME}
${NVINFER_LIBRARY}
cudart
${CUDA_LIBRARIES}
${OpenCV_LIBS}
)include<>
#include<iostream>
#include <string>
#include <cmath>
#include <opencv2/opencv.hpp>
#include <opencv2/dnn.hpp>
#include <fstream>
#include <unistd.h>
#include<memory>
#include <cuda_runtime_api.h> // 包含CUDA运行时API,用于CUDA相关的操作,如内存分配、内存拷贝等
#include <NvInfer.h> // 包含TensorRT的核心类和接口,如ICudaEngine、IExecutionContext等
#include <NvInferRuntime.h> // 包含TensorRT运行时相关的类和接口
#include <NvInferRuntimeCommon.h> // 包含TensorRT运行时的一些公共定义和宏
5 写在最后
如果需要完整代码请私信联系我,如果发现错误欢迎前来指出,如果需要转载请标明出处。
十分感谢以下的博客对我的帮助:

















 1210
1210

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









