









目录
0 引言
蚁狮算法(Ant Lion Optimizer,ALO)是Seyedali Mirjalili学者于2015年基于蚁狮的狩猎机制而提出群智能算法,该算法模拟了蚂蚁随机行走、诱捕蚂蚁、狩猎及重建陷阱、精英化。

1 数学模型
ALO算法的数学模型主要对蚂蚁随机行走、诱捕蚂蚁、狩猎及重建陷阱、精英化等主要行为进行模型构建,对问题进行寻优求解,具体模型如下:
1)初始化:ALO算法为群体智能算法,其蚁狮和蚂蚁的位置采用随机生成,具体如下:
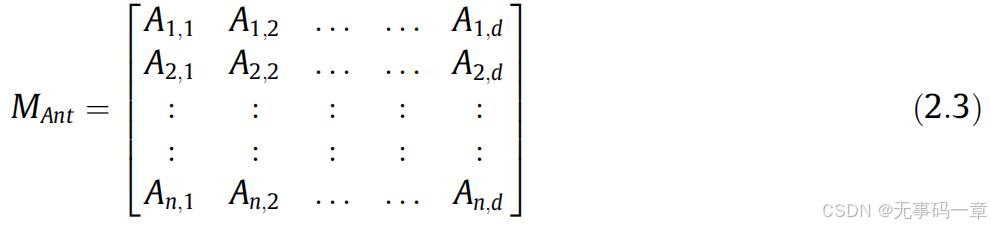
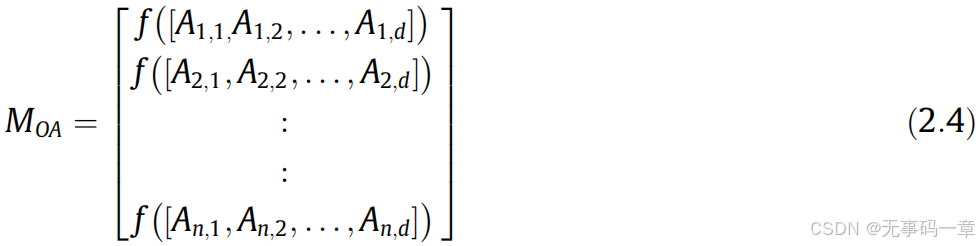
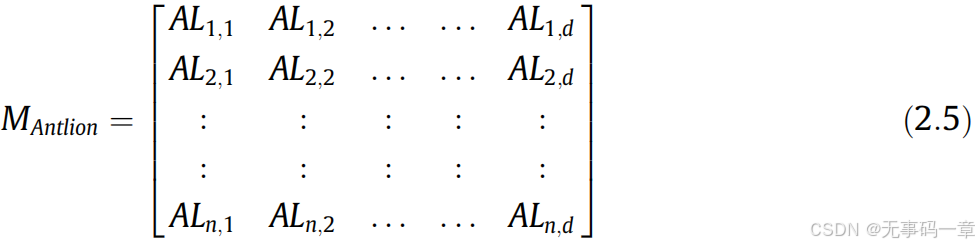
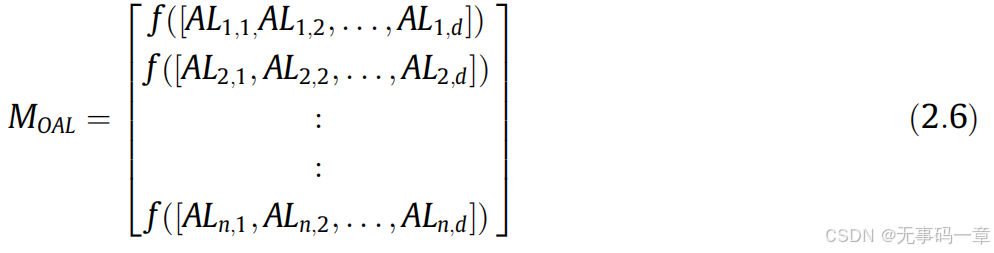
式中Mant为蚂蚁的种群位置;Moa为蚂蚁种群位置对应的适应度函数;Mantlion为蚁狮的种群位置,Moal为蚁狮种群位置对应适应度函数;其中f为适应度函数,d为问题维度,n为种群数目大小。
2)蚂蚁的随机行走:蚂蚁在问题维度范围内进行随机行走更新其自身位置,有利于模型随机性,具体位置更新如下:

式中ai是第i个变量的随机游走的最小值,bi是第i个变量的随机游走的最大值,ct i是第t次迭代时第i个变量的最小值,dt i表示第t次迭代时第i次变量的最大值。X为蚂蚁位置。
3)蚁狮陷阱干扰:蚂蚁随机行走过程中,受蚁狮布置陷阱干扰,其位置更新受范围影响,具体表达如下:

式中ct是在t次迭代过程最小的所有变量,dt表示t次迭代最大变量,ct i是所有变量的最低i次蚂蚁,dt i是所有变量的最大i次蚂蚁,Antliont j显示选定的j次蚂蚁在t次迭代的位置.
4)构建陷阱:为了模拟蚁狮的狩猎能力,使用了轮盘赌轮对蚁狮适应度选取。如图3所示,假设蚂蚁只被困在一个选定的蚂蚁群中。
5)蚂蚁滑入蚁狮陷阱:蚁狮陷阱构建完成后,当蚁狮意识到一只蚂蚁在陷阱里时,它们就会向坑的中心向外喷射沙子。这种行为会滑下试图想逃跑的被困蚂蚁。ALO算法利用蚂蚁的随机游动超球的半径被自适应地减小来描述这类行为:

式中ct是第t次迭代中所有变量的最小值,dt表示第t次迭代中所有变量的最大值的向量;I是一个比值I =10^w T/ t,(w = 2 当 t > 0.1T, w = 3当 t > 0.5T, w = 4 当t > 0.75T, w = 5 当t > 0.9T, and w = 6 当t > 0.95T)
6)捕捉猎物并重建陷阱:ALO通过对比蚁狮捕捉蚂蚁后适应度,选拔出是否取代蚂蚁位置向量,具体如下:
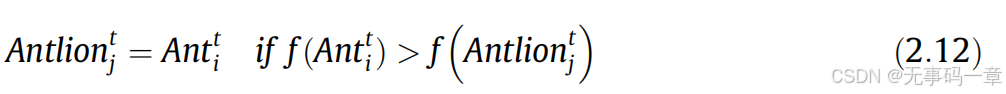
式中t表示当前迭代,Antliont j表示第t次迭代时第j的位置,Antt i表示第i蚂蚁在第t次迭代时的位置。
7)精英化:精英主义是进化算法的一个重要特征,它允许它们保持在优化过程的任何阶段获得的最佳解决方案。在本研究中,每次迭代中获得的最佳角被保存下来,并被视为精英。由于精英是最适合的蚁群,它应该能够在迭代过程中影响所有蚂蚁的运动。因此,假设每只蚂蚁都通过轮盘赌轮和精英们同时随机地在一个选定的蚂蚁周围行走,具体如下:

式中Rt A为第t次迭代时轮盘赌轮选择的蚁狮的随机游走,Rt E为第t次迭代时精英的随机游走,Antt i表示第i蚂蚁在第t次迭代时的位置。
2 优化方式
前篇对长短期记忆神经网络(长短期记忆神经网络原理及Matlab代码复现-优快云博客)原理讲解,从长短期记忆神经网络matlab代码运算过程中,可以看到LSTM受多个超参数影响(隐藏层节点、学习率、分批量、正则化等等)。因此结合上述ALO原理介绍,可以将长短期记忆神经网络的超参数作为蚂蚁和蚁狮的种群位置,每一个种群位置对应长短期记忆神经网络的预测值,将这个预测值作为适应度作为蚂蚁和蚁狮适应度,进行蚂蚁随机行走及蚁狮构建陷阱捕食蚂蚁行为,最终将其精英化保留下来参与迭代,更新最佳蚁狮。
3 MATLAB代码
3.1 伪代码

3.2 ALO主函数代码
while Current_iter<Max_iter+1
% 此 for 循环模拟蚂蚁随机行走
for i=1:size(ant_position,1)
% 根据蚁狮的体能选择蚁狮(体能陷阱大小)
Rolette_index=RouletteWheelSelection(1./sorted_antlion_fitness);
if Rolette_index==-1
Rolette_index=1;
end
% RA 是通过轮盘在选定的蚁穴周围随机行走
RA=Random_walk_around_antlion(dim,Max_iter,lb,ub, Sorted_antlions(Rolette_index,:),Current_iter);
% RE 是随机行走最好的蚁狮
[RE]=Random_walk_around_antlion(dim,Max_iter,lb,ub, Elite_antlion_position(1,:),Current_iter);
ant_position(i,:)= (RA(Current_iter,:)+RE(Current_iter,:))/2; % Equation (2.13)
end
for i=1:size(ant_position,1)
% 边界检查
Flag4ub=ant_position(i,:)>ub;
Flag4lb=ant_position(i,:)<lb;
ant_position(i,:)=(ant_position(i,:).*(~(Flag4ub+Flag4lb)))+ub.*Flag4ub+lb.*Flag4lb;
ants_fitness(1,i)=SYD(ant_position(i,:),net);
end
% 根据蚂蚁的情况更新蚁群的位置和体能
double_population=[Sorted_antlions;ant_position];
double_fitness=[sorted_antlion_fitness ants_fitness];
[double_fitness_sorted I]=sort(double_fitness);
double_sorted_population=double_population(I,:);
antlions_fitness=double_fitness_sorted(1:N);
Sorted_antlions=double_sorted_population(1:N,:);
% 如果有蚂蚁比精英更合适,就更新精英的位置
if antlions_fitness(1)<Elite_antlion_fitness
Elite_antlion_position=Sorted_antlions(1,:);
Elite_antlion_fitness=antlions_fitness(1);
end
% 让精英留在人群中
Sorted_antlions(1,:)=Elite_antlion_position;
antlions_fitness(1)=Elite_antlion_fitness;
% 更新收敛曲线
Convergence_curve(Current_iter)=Elite_antlion_fitness;
Current_iter=Current_iter+1;
end3.3 ALO-LSTM
1)时间序列模型:时间序列:蚁狮算法优化长短期记忆神经网络模型(ALO-BP)


















 990
990

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









