







建议先阅读我之前的深度学习博客,掌握一定的深度学习前置知识后再阅读本文,链接如下:
带你从入门到精通——深度学习(一. 深度学习简介和PyTorch入门)-优快云博客
带你从入门到精通——深度学习(二. PyTorch中的类型转换、运算和索引)-优快云博客
目录
三. PyTorch中张量的形状重塑、拼接和自动微分
3.1 张量的形状重塑
3.1.1 transpose函数和permute函数
transpose函数和permute函数都可以交换张量的维度,但transpose函数一次只能交换两个维度,而permute函数可以一次性交换多个维度(必须传入所有维度,并封装到一个元组中),具体使用方法如下:
import torch
torch.random.manual_seed(0)
t1 = torch.randint(1, 9, (2, 3, 4))
print(t1.shape) # torch.Size([2, 3, 4])
t2 = t1.transpose(0, 1)
print(t2.shape) # torch.Size([3, 2, 4])
t3 = t1.permute((2, 0, 1))
print(t3.shape) # torch.Size([4, 2, 3])
3.1.2 reshape函数和view函数
reshape函数和view函数可以在保证张量数据不变的前提下,将其转换成指定的形状(数据排列遵循从左到右、从上到下的原则),具体使用方法如下:
import torch
torch.random.manual_seed(0)
t1 = torch.randint(1, 9, (2, 3, 4))
t2 = t1.reshape(2, -1)
print(t2.shape) # torch.Size([2, 12])
t3 = t1.view(6, 1, 4)
print(t3.shape) # torch.Size([6, 1, 4])注意:上述函数中可以使用-1表示自动计算该维度的长度(前提是转换前后维度的长度乘积相同)。
注意:使用view函数只能修改存储在整块的内存中的张量的形状。在PyTorch中,有些张量是由不同的数据块组成的,它们并没有存储在整块的内存中,view函数无法对这样的张量的形状进行转换,例如:一个张量经过了transpose函数或者permute函数的处理之后,就无法使用view函数进行转换操作,具体示例如下:
import torch
torch.random.manual_seed(0)
t1 = torch.randint(1, 9, (2, 3, 4))
# is_contiguous函数用于判断张量是否存储在整块的内存中
print(t1.is_contiguous()) # True
t2 = t1.transpose(0, 1)
print(t2.is_contiguous()) # False
# contiguous函数用于将张量存储在整块的内存中
t3 = t2.contiguous()
print(t3.is_contiguous()) # True
print(t3.view(-1).size()) # torch.Size([24])3.1.3 squeeze函数和unsqueeze函数
squeeze函数可以删除张量中长度为1的维度(进行降维),unsqueeze函数可以为张量添加一个长度为1的维度(进行升维),具体使用方法如下:
import torch
torch.random.manual_seed(0)
t1 = torch.randint(1, 9, (2, 1, 4, 3))
t2 = t1.squeeze(1)
print(t2.shape) # torch.Size([2, 4, 3])
t3 = t1.unsqueeze(2)
print(t3.shape) # torch.Size([2, 1, 1, 4, 3])
t4 = t1.unsqueeze(-2)
print(t4.shape) # torch.Size([2, 1, 4, 1, 3])注意:使用squeeze函数时可以传入需要删除的维度,如果传入的维度的长度不为1,则不会进行降维操作,如果不传入参数,默认删除所有长度为1的维度。
注意:使用unsqueeze函数时必须传入添加维度的位置索引,可以使用正索引和负索引,使用正索引时,在指定位置添加一个长度为1的维度之后,将其他维度向后移动一位;使用负索引时,在指定位置添加一个长度为1的维度之后,将其他维度向前移动一位。
3.2 张量的合并
3.2.1 张量的拼接
可以使用cat函数完成张量的拼接,具体使用方法如下:
import torch
torch.random.manual_seed(0)
t1 = torch.randint(1, 9, (2, 1, 4, 3))
t2 = torch.randint(1, 9, (2, 3, 4, 3))
t3 = torch.cat((t1, t2), dim=1)
print(t3.shape) # torch.Size([2, 4, 4, 3])注意:cat函数只有torch.cat()的形式,并且第一个参数为需要拼接的张量组成的元组,dim参数用于指定拼接的维度,指定的维度的长度可以不一样,但其它维度的长度必须一样。
3.2.2 张量的堆叠
可以使用stack函数完成张量的堆叠,具体使用方法如下:
import torch
t1 = torch.rand(2, 3, 4)
t2 = torch.rand(2, 3, 4)
t3 = torch.stack((t1, t2), dim=2)
print(t3.shape) # torch.Size([2, 3, 2, 4])注意:dim参数用于指定堆叠张量的维度,并且张量的形状必须完全一样才能够进行堆叠。
3.3 自动微分模块
3.3.1 计算图
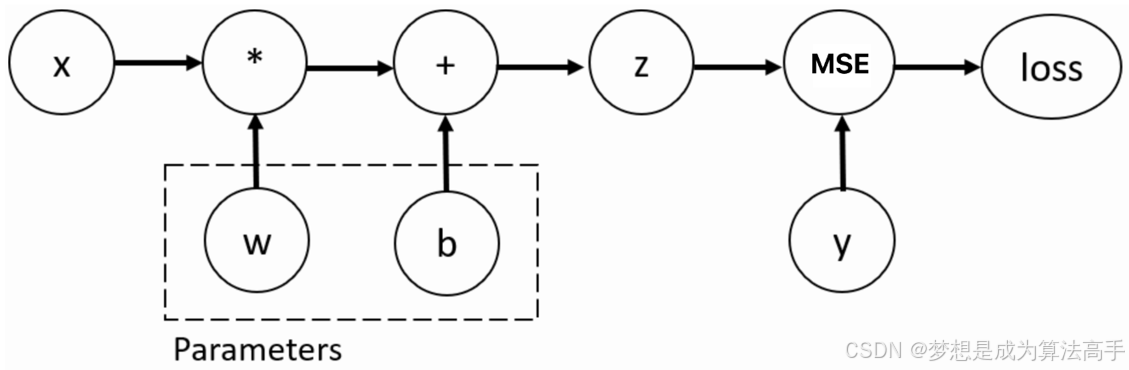
计算图是一种用于表示数学表达式和程序中计算过程的数据结构,它通过节点(Nodes)和边(Edges)来表示计算中的操作和数据流。
计算图中的节点代表计算图中的操作或变量,变量节点通常表示输入数据或中间结果;操作节点通常表示对输入数据进行的运算操作。
计算图中的边表示数据在节点之间的流动,从一个节点到另一个节点的边表示数据间的依赖关系,即一个节点的输出是另一个节点的输入。
计算图中的前向传播是指从输入节点开始,按照计算图的结构逐步计算每个节点的值,直到得到最终结果的过程;而反向传播是指从输出节点开始,计算每个节点对损失函数的梯度,用于更新模型参数的过程,这是也是自动微分的基础。
3.3.2 静态计算图和动态计算图
静态计算图和动态计算图是两种不同的计算图构建和执行方式。
静态计算图是指在运行之前便构建好的计算图,然后在运行时重复使用相同的图结构,这种计算图的结构在编译阶段就已经确定,不会在运行时改变。
静态计算图的优点:性能较高,可以在编译阶段对计算图进行优化,以提高计算效率,例如进行常量折叠、内存分配优化等,并且静态计算图的稳定性较高,固定的计算图结构使得代码更加稳定和可预测。
静态计算图的缺点:灵活性低,难以处理变长序列和复杂的控制流(如条件分支和循环)并且调试过程较为复杂,需要额外的工具支持。
TensorFlow的1.x版本使用的即为静态计算图。
动态计算图是指在每次运行时根据输入数据动态构建的计算图,这种计算图的结构在运行时可以改变。
动态计算图的优点:灵活性高,可以处理变长序列和复杂的控制流并且调试过程相对简单,可以直接使用标准调试工具。
动态计算图的缺点:性能较低,由于计算图的结构不固定,可能无法进行一些高级优化并且稳定性较低,由于计算图的结构在运行时变化,可能导致代码不稳定。
TensorFlow的2.x版本和PyTorch使用的即为动态计算图。
3.3.3 自动微分模块示例
训练神经网络时,最常用的算法就是反向传播(Back propagation,BP)算法,在该算法中,参数(模型权重和偏置)会根据损失函数关于对应参数的梯度进行调整,为了计算这些梯度,PyTorch的torch.autograd模块提供了自动微分功能,它支持动态计算图的自动梯度计算,具体示例如下:
import torch
# 输入张量的形状为2 * 5
x = torch.ones(2, 5)
# 目标值的形状为2 * 3
y = torch.zeros(2, 3)
# 设置要更新的权重和偏置的初始值
# requires_grad参数用于指定是否需要对该张量的所有操作进行跟踪,并在反向传播时计算其梯度
# 对于模型的参数(如权重和偏置),一般会设置requires_grad=True,以便在训练过程中更新这些参数
w = torch.randn(5, 3, requires_grad=True)
b = torch.randn(3, requires_grad=True)
# 设置网络的输出值
z = torch.matmul(x, w) + b # matmul函数为矩阵乘法, 加b时使用了张量的广播机制
# 创建损失函数对象, MSELoss表示使用均方误差损失函数
loss = torch.nn.MSELoss()
# 计算损失,此时的loss为一个张量
loss = loss(z, y)
# 调用loss的backward函数,底层使用了PyTorch中的torch.autograd模块进行自动微分
loss.backward()
# backward函数计算的梯度值会存储在张量的grad属性中
print("w的梯度:", w.grad)
print("b的梯度", b.grad)
'''
w的梯度: tensor([[-1.4915, 2.2535, -2.5010],
[-1.4915, 2.2535, -2.5010],
[-1.4915, 2.2535, -2.5010],
[-1.4915, 2.2535, -2.5010],
[-1.4915, 2.2535, -2.5010]])
b的梯度 tensor([-1.4915, 2.2535, -2.5010])
'''上述计算过程的计算图如下:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









