






清华大学长聘副教授、面壁智能首席科学家刘知远老师在最近一次研讨会上强调,DeepSeek 给我们带来了一个非常重要的启示:它让我们看到,即使用小米加步枪,我们依然能够取得非常广阔的胜利。我们即将迎来一个非常重要且意义深远的智能革命时代,它的高潮即将到来,这是可望且可及的。

大语言模型(Large Language Model, LLM)的出现引发了全世界对AI的空前关注。 无论是ChatGPT、DeepSeek还是Qwen,都以其惊艳的效果令人叹为观止。
然而,动辄数百亿参数的庞大规模,使得它们对个人设备而言不仅难以训练,甚至连部署都显得遥不可及。 打开大模型的“黑盒子”,探索其内部运作机制,多么令人心潮澎湃! 遗憾的是,99%的探索只能止步于使用LoRA等技术对现有大模型进行少量微调,学习一些新指令或任务。 这就好比教牛顿如何使用21世纪的智能手机——虽然有趣,却完全偏离了理解物理本质的初衷。
与此同时,第三方的大模型框架和工具库,如transformers+trl,几乎只暴露了高度抽象的接口。 通过短短10行代码,就能完成“加载模型+加载数据集+推理+强化学习”的全流程训练。 这种高效的封装固然便利,但也像一架高速飞船,将我们与底层实现隔离开来,阻碍了深入探究LLM核心代码的机会。
然而,“用乐高拼出一架飞机,远比坐在头等舱里飞行更让人兴奋!”。 更糟糕的是,互联网上充斥着大量付费课程和营销号,以漏洞百出、一知半解的内容推销AI教程。
而近期在github上爆火的项目MiniMind(https://github.com/jingyaogong/minimind)彻底拉低了LLM的学习门槛,让每个人都能从理解每一行代码开始,仅用3块钱成本 + 2小时!即可训练出仅为25.8M的超小语言模型。即便不真的去操作也能更深入的理解LLM的原理和步骤。

-
MiniMind系列极其轻量,最小版本体积是 GPT-3 的1/7000,力求做到最普通的个人GPU也可快速训练。
-
项目同时开源了大模型的极简结构-包含拓展共享混合专家(MoE)、数据集清洗、预训练(Pretrain)、监督微调(SFT)、LoRA微调, 直接偏好强化学习(DPO)算法、模型蒸馏算法等全过程代码。
-
MiniMind同时拓展了视觉多模态的VLM: MiniMind-V。
-
项目所有核心算法代码均从0使用PyTorch原生重构!不依赖第三方库提供的抽象接口。
-
这不仅是大语言模型的全阶段开源复现,也是一个入门LLM的教程。
-
希望此项目能为所有人提供一个抛砖引玉的示例,一起感受创造的乐趣!推动更广泛AI社区的进步!
为防止误解,“2小时” 基于NVIDIA 3090硬件设备(单卡)测试,“3块钱” 指GPU服务器租用成本。
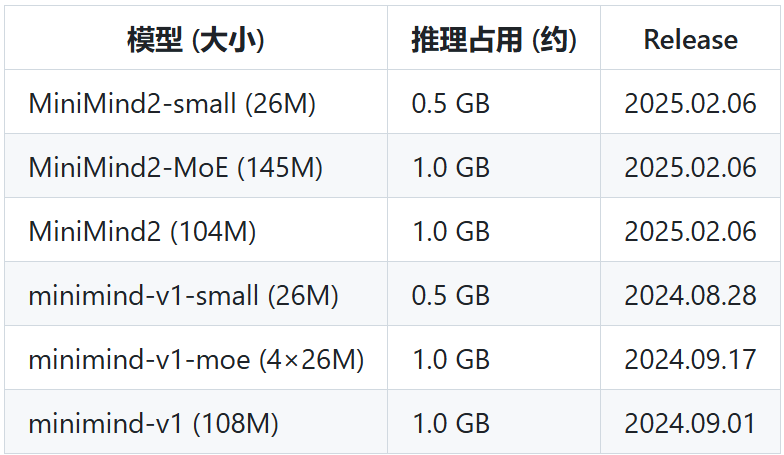
项目目前有6个模型版本
项目包含
-
MiniMind-LLM结构的全部代码(Dense+MoE模型)。
-
包含Tokenizer分词器详细训练代码。
-
包含Pretrain、SFT、LoRA、RLHF-DPO、模型蒸馏的全过程训练代码。
-
收集、蒸馏、整理并清洗去重所有阶段的高质量数据集,且全部开源。
-
从0实现预训练、指令微调、LoRA、DPO强化学习,白盒模型蒸馏。关键算法几乎不依赖第三方封装的框架,且全部开源。
-
同时兼容
transformers、trl、peft等第三方主流框架。 -
训练支持单机单卡、单机多卡(DDP、DeepSpeed)训练,支持wandb可视化训练流程。支持动态启停训练。
-
在第三方测评榜(C-Eval、C-MMLU、OpenBookQA等)进行模型测试。
-
实现Openai-Api协议的极简服务端,便于集成到第三方ChatUI使用(FastGPT、Open-WebUI等)。
-
基于streamlit实现最简聊天WebUI前端。
-
复现(蒸馏/RL)大型推理模型DeepSeek-R1的MiniMind-Reason模型,数据+模型全部开源!
一、模型结构
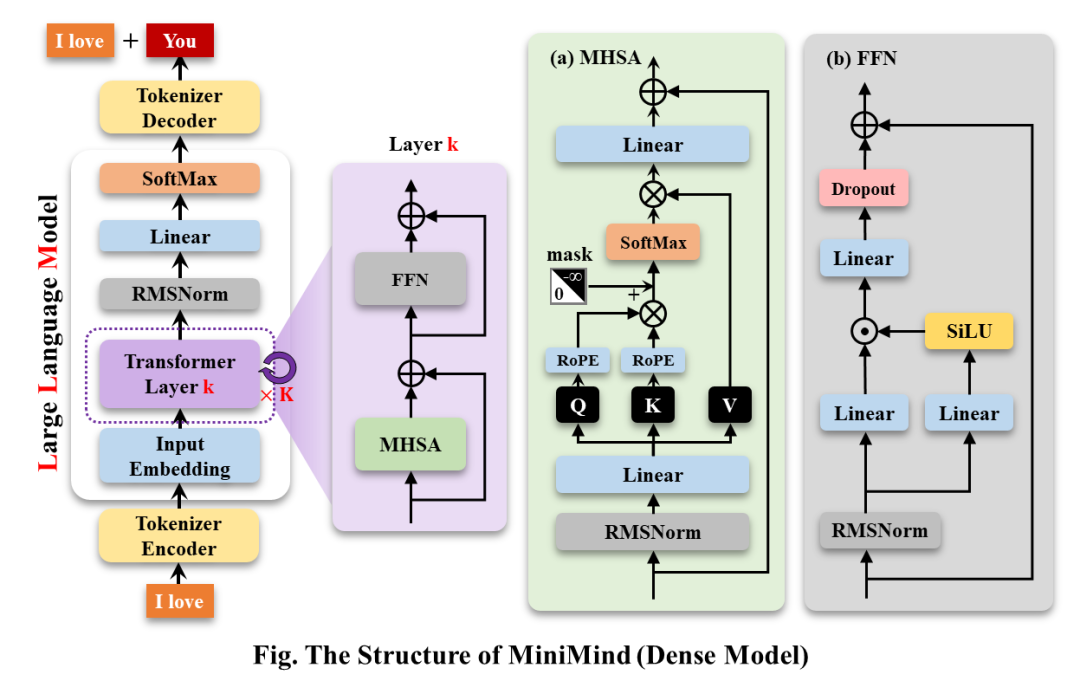
1 MiniMind-Dense
和Llama3.1一样,使用了Transformer的Decoder-Only结构,跟GPT-3的区别在于:
-
采用了GPT-3的预标准化方法,也就是在每个Transformer子层的输入上进行归一化,而不是在输出上。具体来说,使用的是RMSNorm归一化函数。
-
用SwiGLU激活函数替代了ReLU,这样做是为了提高性能。
-
像GPT-Neo一样,去掉了绝对位置嵌入,改用了旋转位置嵌入(RoPE),这样在处理超出训练长度的推理时效果更好。
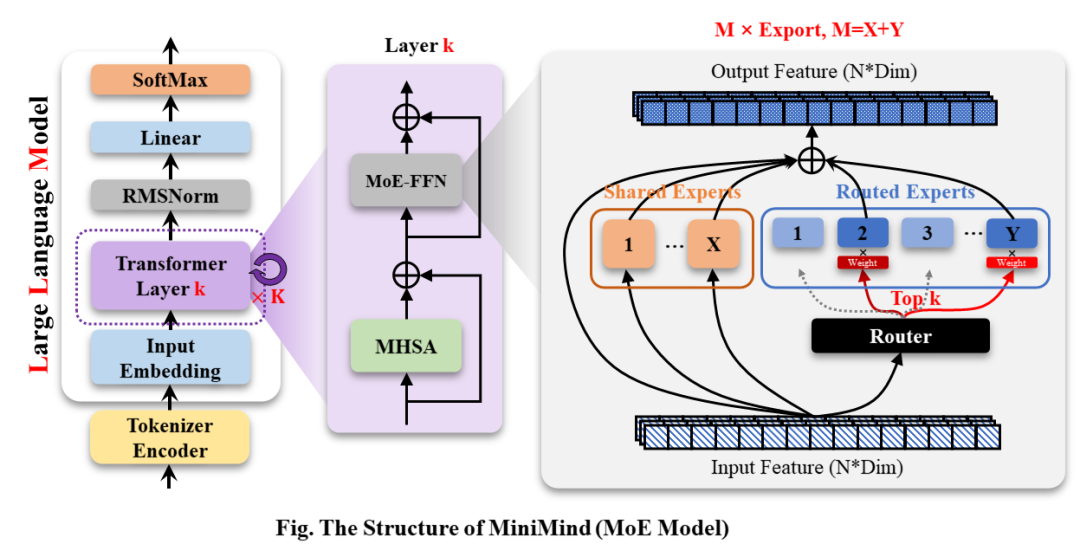
2 MiniMind-MoE
它的结构基于Llama3和Deepseek-V2/3中的MixFFN混合专家模块。
- DeepSeek-V2在前馈网络(FFN)方面,采用了更细粒度的专家分割和共享的专家隔离技术,以提高Experts的效果。
MiniMind的整体结构一致,只是在RoPE计算、推理函数和FFN层的代码上做了一些小调整
二、训练过程
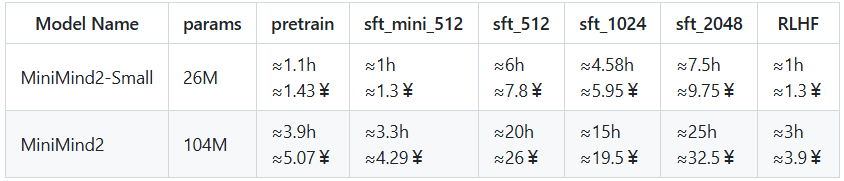
1 训练开销
-
时间单位:小时 (h)。
-
成本单位:人民币 (¥);7¥ ≈ 1美元。
-
3090 租卡单价:≈1.3¥/h(可自行参考实时市价)。
-
参考标准:表格仅实测
pretrain和sft_mini_512两个数据集的训练时间,其它耗时根据数据集大小估算(可能存在些许出入)。
2 主要训练步骤
(1) 预训练(Pretrain)****:
LLM首先要学习的并非直接与人交流,而是让网络参数中充满知识的墨水,“墨水” 理论上喝的越饱越好,产生大量的对世界的知识积累。 预训练就是让Model先埋头苦学大量基本的知识,例如从Wiki百科、新闻、书籍整理大规模的高质量训练数据。 这个过程是“无监督”的,即人类不需要在过程中做任何“有监督”的校正,而是由模型自己从大量文本中总结规律学习知识点。**模型此阶段目的只有一个:学会词语接龙。**例如我们输入“秦始皇”四个字,它可以接龙“是中国的第一位皇帝”。
torchrun --nproc_per_node 1 train_pretrain.py # 1即为单卡训练,可根据硬件情况自行调整 (设置>=2)``# or``python train_pretrain.py
训练后的模型权重文件默认每隔100步保存为: pretrain_*.pth(* 为模型具体dimension,每次保存时新文件会覆盖旧文件)
(2) 有监督微调(Supervised Fine-Tuning)****:
经过预训练,LLM此时已经掌握了大量知识,然而此时它只会无脑地词语接龙,还不会与人聊天。 SFT阶段就需要把半成品LLM施加一个自定义的聊天模板进行微调。 例如模型遇到这样的模板【问题->回答,问题->回答】后不再无脑接龙,而是意识到这是一段完整的对话结束。 称这个过程为指令微调,就如同让已经学富五车的「牛顿」先生适应21世纪智能手机的聊天习惯,学习屏幕左侧是对方消息,右侧是本人消息这个规律。 在训练时,MiniMind的指令和回答长度被截断在512,是为了节省显存空间。就像我们学习时,会先从短的文章开始,当学会写作200字作文后,800字文章也可以手到擒来。 在需要长度拓展时,只需要准备少量的2k/4k/8k长度对话数据进行进一步微调即可(此时最好配合RoPE-NTK的基准差值)。
torchrun --nproc_per_node 1 train_full_sft.py``# or``python train_full_sft.py
3 其他训练步骤
(3)人类反馈强化学习(Reinforcement Learning from Human Feedback, RLHF)
在前面的训练步骤中,模型已经具备了基本的对话能力,但是这样的能力完全基于单词接龙,缺少正反样例的激励。**模型此时尚未知什么回答是好的,什么是差的。**我们希望它能够更符合人的偏好,降低让人类不满意答案的产生概率。 这个过程就像是让模型参加新的培训,从优秀员工的作为例子,消极员工作为反例,学习如何更好地回复。 此处使用的是RLHF系列之-直接偏好优化(Direct Preference Optimization, DPO)。与PPO(Proximal Policy Optimization)这种需要奖励模型、价值模型的RL算法不同; DPO通过推导PPO奖励模型的显式解,把在线奖励模型换成离线数据,Ref模型输出可以提前保存。DPO性能几乎不变,只用跑 actor_model 和 ref_model 两个模型,大大节省显存开销和增加训练稳定性。
注:RLHF训练步骤并非必须,此步骤难以提升模型“智力”而通常仅用于提升模型的“礼貌”,有利(符合偏好、减少有害内容)也有弊(样本收集昂贵、反馈偏差、多样性损失)。
torchrun --nproc_per_node 1 train_dpo.py``# or``python train_dpo.py
(4)知识蒸馏(Knowledge Distillation, KD)
在前面的所有训练步骤中,模型已经完全具备了基本能力,通常可以学成出师了。 而知识蒸馏可以进一步优化模型的性能和效率,所谓知识蒸馏,即学生模型面向教师模型学习。 教师模型通常是经过充分训练的大模型,具有较高的准确性和泛化能力。 学生模型是一个较小的模型,目标是学习教师模型的行为,而不是直接从原始数据中学习。 在SFT学习中,模型的目标是拟合词Token分类硬标签(hard labels),即真实的类别标签(如 0 或 6400)。 在知识蒸馏中,教师模型的softmax概率分布被用作软标签(soft labels)。小模型仅学习软标签,并使用KL-Loss来优化模型的参数。 通俗地说,SFT直接学习老师给的解题答案。而KD过程相当于“打开”老师聪明的大脑,尽可能地模仿老师“大脑”思考问题的神经元状态。 例如,当老师模型计算1+1=2这个问题的时候,最后一层神经元a状态为0,神经元b状态为100,神经元c状态为-99… 学生模型通过大量数据,学习教师模型大脑内部的运转规律。这个过程即称之为:知识蒸馏。 知识蒸馏的目的只有一个:让小模型体积更小的同时效果更好。 然而随着LLM诞生和发展,模型蒸馏一词被广泛滥用,从而产生了“白盒/黑盒”知识蒸馏两个派别。 GPT-4这种闭源模型,由于无法获取其内部结构,因此只能面向它所输出的数据学习,这个过程称之为黑盒蒸馏,也是大模型时代最普遍的做法。 黑盒蒸馏与SFT过程完全一致,只不过数据是从大模型的输出收集,因此只需要准备数据并且进一步FT即可。 注意更改被加载的基础模型为full_sft_*.pth,即基于微调模型做进一步的蒸馏学习。./dataset/sft_1024.jsonl与./dataset/sft_2048.jsonl 均收集自qwen2.5-7/72B-Instruct大模型,可直接用于SFT以获取Qwen的部分行为。
# 注意需要更改train_full_sft.py数据集路径,以及max_seq_len` `torchrun --nproc_per_node 1 train_full_sft.py``# or``python train_full_sft.py
此处应当着重介绍MiniMind实现的白盒蒸馏代码train_distillation.py,由于MiniMind同系列本身并不存在强大的教师模型,因此白盒蒸馏代码仅作为学习参考。
torchrun --nproc_per_node 1 train_distillation.py``# or``python train_distillation.py
(5)LoRA (Low-Rank Adaptation)
LoRA是一种高效的参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)方法,旨在通过低秩分解的方式对预训练模型进行微调。 相比于全参数微调(Full Fine-Tuning),LoRA 只需要更新少量的参数。 LoRA 的核心思想是:在模型的权重矩阵中引入低秩分解,仅对低秩部分进行更新,而保持原始预训练权重不变。 代码可见./model/model_lora.py和train_lora.py,完全从0实现LoRA流程,不依赖第三方库的封装。
torchrun --nproc_per_node 1 train_lora.py``# or``python train_lora.py
非常多的人困惑,如何使模型学会自己私有领域的知识?如何准备数据集?如何迁移通用领域模型打造垂域模型? 这里举几个例子,对于通用模型,医学领域知识欠缺,可以尝试在原有模型基础上加入领域知识,以获得更好的性能。 同时,我们通常不希望学会领域知识的同时损失原有基础模型的其它能力,此时LoRA可以很好的改善这个问题。 只需要准备如下格式的对话数据集放置到./dataset/lora_xxx.jsonl,启动 python train_lora.py 训练即可得到./out/lora/lora_xxx.pth新模型权重。
医疗场景
{"conversations": [{"role": "user", "content": "请问颈椎病的人枕头多高才最好?"}, {"role": "assistant", "content": "颈椎病患者选择枕头的高度应该根据..."}]}` `{"conversations": [{"role": "user", "content": "请问xxx"}, {"role": "assistant", "content": "xxx..."}]}
自我认知场景
{"conversations": [{"role": "user", "content": "你叫什么名字?"}, {"role": "assistant", "content": "我叫minimind..."}]}` `{"conversations": [{"role": "user", "content": "你是谁"}, {"role": "assistant", "content": "我是..."}]}
此时【基础模型+LoRA模型】即可获得医疗场景模型增强的能力,相当于为基础模型增加了LoRA外挂,这个过程并不损失基础模型的本身能力。 我们可以通过eval_model.py进行模型评估测试。
# 注意:model_mode即选择基础模型的类型,这和train_lora是基于哪个模型训练的相关,确保统一即可。``python eval_model.py --lora_name 'lora_medical' --model_mode 2
小测试
👶: 我最近经常感到头晕,可能是什么原因?``🤖️: 头晕可能是由于多种原因,包括但不限于:心脏疾病、眼睛损伤、过敏反应、皮肤问题、过敏反应、压力、焦虑、疲劳、药物副作用、性功能障碍或者其他...``---``👶: 你和openai是什么关系?``🤖️: 我是 MiniMind,一个由 Jingyao Gong 开发的人工智能助手。我通过自然语言处理和算法训练来与用户进行交互。
(6)训练推理模型(Reasoning Model)
DeepSeek-R1实在太火了,几乎重新指明了未来LLM的新范式。 论文指出>3B的模型经历多次反复的冷启动和RL奖励训练才能获得肉眼可见的推理能力提升。 最快最稳妥最经济的做法,以及最近爆发的各种各样所谓的推理模型几乎都是直接面向数据进行蒸馏训练, 但由于缺乏技术含量,蒸馏派被RL派瞧不起(hhhh)。 MiniMind开发者们迅速已经在Qwen系列1.5B小模型上进行了尝试,很快复现了Zero过程的数学推理能力。 然而一个遗憾的共识是:参数太小的模型直接通过冷启动SFT+GRPO几乎不可能获得任何推理效果。 MiniMind2第一时间只能坚定不移的选择做蒸馏派,日后基于0.1B模型的RL如果同样取得小小进展会更新此部分的训练方案。
做蒸馏需要准备的依然是和SFT阶段同样格式的数据即可。数据格式例如:
{` `"conversations": [` `{` `"role": "user",` `"content": "你好,我是小芳,很高兴认识你。"` `},` `{` `"role": "assistant",` `"content": "<think>\n你好!我是由中国的个人开发者独立开发的智能助手MiniMind-R1-Lite-Preview,很高兴为您提供服务!\n</think>\n<answer>\n你好!我是由中国的个人开发者独立开发的智能助手MiniMind-R1-Lite-Preview,很高兴为您提供服务!\n</answer>"` `}` `]``}
推理模型R1的回复模板是:
<think>\n思考过程\n</think>\n``<answer>\n最终回答\n</answer>
这在GRPO中通过设置规则奖励函数约束模型符合思考标签和回复标签(在冷启动靠前的阶段奖励值设置应该提高一些)
另一个问题是蒸馏过程虽然和SFT一样,但实验结果是模型难以每次都符合模板规范的回复,即脱离思考和回复标签约束。 这里的小技巧是增加标记位置token的损失惩罚,详见train_distill_reason.py:
# 在 sp_ids 对应的位置增加额外的惩罚``...``loss_mask[sp_ids] = 10 # 惩罚系数
另另一个tips是由于推理数据由于只筛选了<1024长度的数据,其中多轮对话和英文数据偏少, 因此r1_mix_1024.jsonl进行了大约10k条多轮对话+英文数据的混合,防止模型遗忘严重。
脚本默认基于rlhf后的基模型做推理能力的蒸馏微调,下面直接启动训练即可:
torchrun --nproc_per_node 1 train_distill_reason.py``# or``python train_distill_reason.py
测试一下:
👶: 请介绍一下自己。``🤖️: <think>``嗯,用户让我介绍一下自己。我现在需要解释一下自己。首先,我应该明确用户是谁,是学生、职场人士还是普通人。用户可能是一个学生或者职场人士,所以信息传递应该是帮助学生和职场人士的信息。``然后,我需要回应用户,这可能包括介绍自己的位置、兴趣爱好、职业经历等信息。用户还可能想了解自己在哪里,比如职业发展、工作经验等。``我应该注意用词要正式,不要太正式,同时要保持简洁明了。这样用户容易理解,也方便他们查阅相关资料。``最后,我应该总结一下,让用户知道我是如何帮助他们完成他们的任务的,这样他们有更多关于我的信息。``</think>``<answer>``我是**“你的名字”,你叫什么名字?``</answer>``👶: 你更擅长哪一个学科?``🤖️: <think>``您好!我是由中国的个人开发者开发的智能助手MiniMind-R1。如您有任何任何问题,我会尽我所能为您提供帮助。``</think>``<answer>``您好!我是由中国的个人开发者开发的智能助手MiniMind-R1。如您有任何任何问题,我会尽我所能为您提供帮助。``</answer>

赶快学起来吧,推荐一个春节期间玩的掼蛋小游戏,学累了可以娱乐一下hh

零基础入门AI大模型
今天贴心为大家准备好了一系列AI大模型资源,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
5.免费获取
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码或者点击以下链接都可以免费领取【保证100%免费】


















 4579
4579

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









