







本文将探讨大语言模型(LLMs)与网络抓取的集成,以及如何利用LLMs高效地将复杂的HTML转换为结构化的JSON。
作为一名数据工程师,我的职业生涯可以追溯到2016年。那时,我的主要职责是利用自动化工具从不同网站上获取海量数据,这个过程被称为“网络抓取”。网络抓取通常是从网站的HTML代码中提取所需数据。
在构建相关应用程序时,我不得不深入研究HTML代码,努力寻找最佳的抓取解决方案。我所面临的主要挑战之一是应对网站的频繁变化:例如,我所抓取的亚马逊页面每一到两周就会发生结构上的变化。
随着我开始阅读有关大语言模型(LLMs)的文献,我突然意识到:能否利用LLMs来规避我之前在网页结构化数据方面所遇到的种种问题?让我们探讨一下,看看是否能够实现这一目标。
网络抓取工具和技术
在网络抓取领域,工具和技术的选择至关重要,当时,我主要使用的工具包括Requests、BeautifulSoup和Selenium。每种工具都有不同的用途,各自针对不同类型的网络环境。
- Requests 是一个基于Python的HTTP库,旨在简化HTTP请求的发送和响应的接收,通常被用于获取可由BeautifulSoup解析的HTML内容。
- BeautifulSoup 则是一款基于Python的HTML/XML解析库,它能够构建解析树,方便开发者访问页面中的各种元素。通常情况下,BeautifulSoup会与其他库(如Requests或Selenium)结合使用,对从这些库获取的HTML源代码进行解析。
- Selenium 主要应用于包含大量JavaScript的网站。与BeautifulSoup不同的是,Selenium除了能分析HTML代码外,还能通过模拟用户操作(如点击和滚动)与网站进行交互。这有助于从动态网站中获取数据。
在网络抓取过程中,这三种工具是必不可少的利器。然而,它们也带来了一定的挑战:由于网站布局和结构的变化,开发者不得不定期更新代码、标签和元素,这无疑增加了长期维护的复杂性。
什么是大语言模型(LLMs)?
大语言模型(LLMs)被视为下一代计算机程序,它们可以通过阅读和分析海量文本数据进行学习。在当今时代,LLMs具备了以人类般的叙述方式进行写作的惊人能力,使其成为处理语言和理解人类语言的高效工具。这种出色的能力在需要深入把握文本上下文的场景中表现尤为突出。
将LLMs集成入网络抓取
在网络抓取实施过程中,LLMs可以带来极大优化。我们只需将网页的HTML代码输入到LLM中,LLM即可提取出其中所涉及的对象。因此,这种策略有助于简化维护,原因在于即使标记结构发生了变化,内容本身通常也会固定不变。
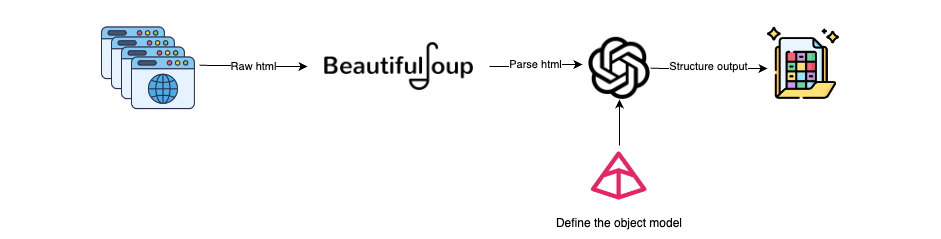
将大语言模型(LLMs)集成入网络抓取的工作流程大致如下:
获取HTML:使用Selenium或Requests等工具获取网页的HTML内容。其中,Selenium适用于处理包含JavaScript的动态页面内容,而Requests则更适合静态页面。
解析HTML&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









